2da Evaluación II Término 2016-2017. Febrero 14, 2016 /CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
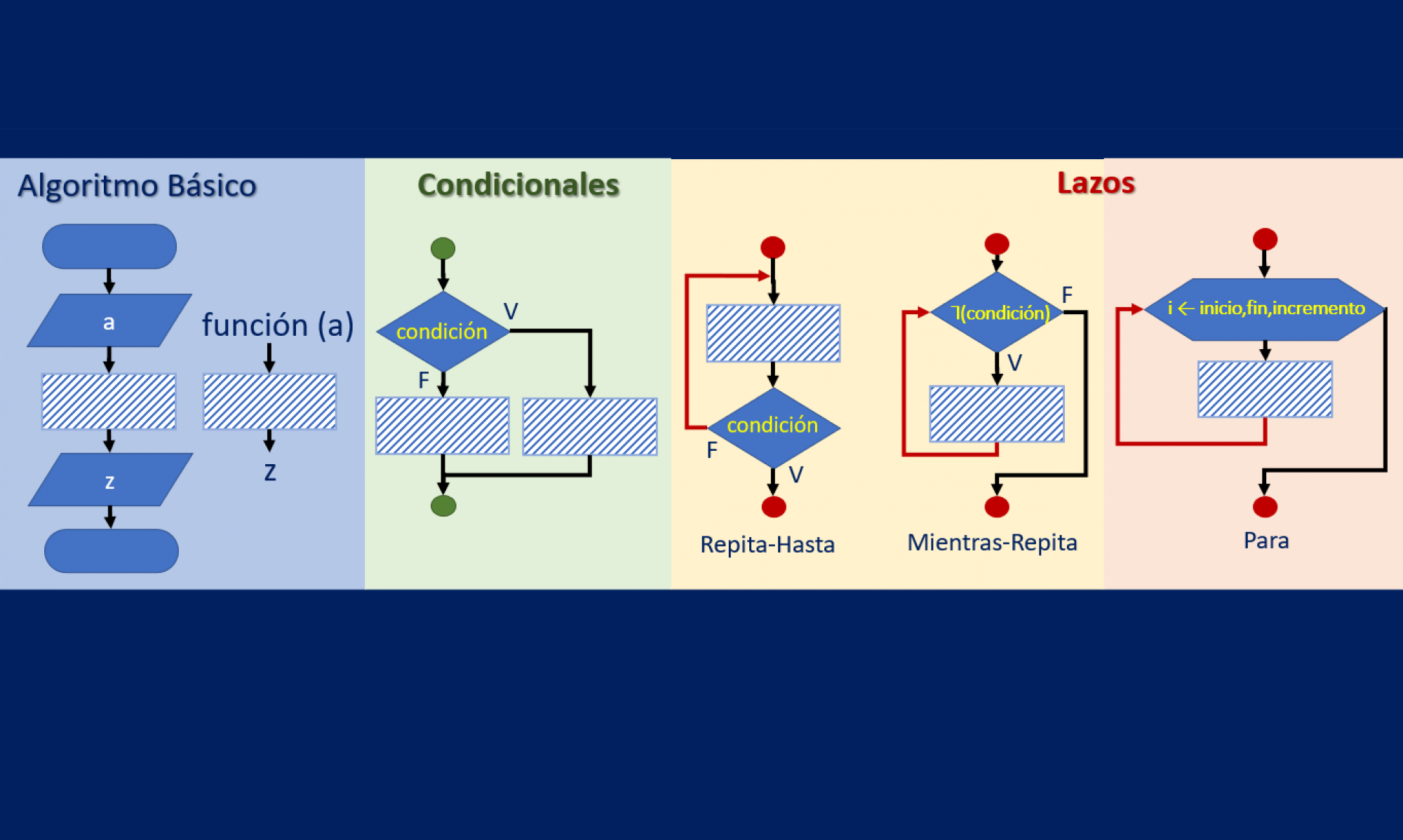
Tema 2. Para ayudar a las personas alrededor del mundo a seleccionar un país donde vivir cuando se jubilen, se ofrece información como el costo de vida, las temperaturas medias por ciudad, etc.
a. Escriba la función cargarDatos(nomFile)
que recibe el nombre de un archivo con las ciudades y sus métricas y retorna un diccionario con la estructura mostrada a continuación:
Ejemplo: "datos.txt" contiene:
Cuenca,temperatura,22
Guayaquil,canastaBasica,630
Cuenca,canastaBasica,457
Bogota,canastaBasica,321
Bogota,temperatura,20
Guayaquil,temperatura,29
cargarDatos("datos.txt") retorna un diccionario con la siguiente estructura:
datos=
{"Guayaquil":{"canastaBasica":630, "temperatura":29},
"Cuenta": {"canastaBasica":457, "temperatura":22},
...}
Nota: para el ejercicio solo existen dos métricas posibles: “canastaBásica” y “temperatura” y todas las ciudades tienen ambas métricas.
b. Escriba la función metricaPais(datos, paises) que recibe el diccionario datos, generado con la función anterior, y el diccionario paises que tiene como clave el nombre del país y como valor la lista de ciudades para ese país. Esta función calcula el valor promedio de cada métrica por país y retorna un diccionario cuya clave es el país y cuyo valor es otro diccionario con los promedios por métrica.
paises={'Ecuador':{'Cuenca','Guayaquil'},'Colombia':{'Bogotá'}, ...}
Por ejemplo, para Guayaquil y Cuenca que pertenecen al mismo país se calcula el promedio de las métricas: "canastaBasica" y "temperatura", cuyo resultado se lo asigna al país Ecuador
{"Ecuador": {"canastaBasica":542.50, "temperatura":25.5},
"Colombia": {"canastaBasica":321, "temperatura":20},
...}
c. Escriba la función generaPaises(promedios, metrica, minimo, maximo) para buscar los paises que en su promedios cumplen con los valores entre mínimo y máximo para una métrica deseada.
Los argumentos son promedios, con la estructura del diccionario generado en la función anterior, una cadena denominado métrica que puede ser “canastaBasica” o “temperatura” y un valor mínimo y un máximo para dicha métrica. El resultado será un archivo con el nombre de la métrica”.csv” que contiene: los países y el valor de la métrica buscada separados por coma.
Usando el ejemplo anterior:
generaPaises(proms, "temperatura", 23, 26)
"temperatura.csv" tendrá el siguiente contenido:
Ecuador,temperatura, 25.5
Referencia: “Ecuador, a la cabeza de los mejores países para los jubilados“. 2 de Enero, 2015, www.eluniverso.com,
– Archivo original 2Eva_IIT2016.pdf