2da Evaluación I Término 2019-2020, Agosto 30, 2019
Tema 3. (10 puntos) ¿Qué muestra el siguiente código? Justifique su respuesta
A = {3, 6, 7, 13, 19}
B = {13, 15, 19, 23, 29}
C = A.union(B)- B.intersection(A)
D = A.symmetric_difference(B)
if C == D:
print('Vaya a la oficina 2')
else:
print('Regrese a la oficina 5')
Nota: Asuma que este tema NO tiene errores de compilación. Si usted cree que hay algún error de compilación, consúltelo inmediatamente con su profesor.
Y el archivo estadisticas.csv con el siguiente contenido de ejemplo:
Buenos Aires, México, Budapest, ...
Ciudad,Indicador,valor
Santiago de Chile,Num_empresas,58
Guayaquil,Inversion en $,17423...
Guayaquil,Num_coworkings,5
Nota: La primera línea del archivo estadisticas.csv tiene los nombres de todas las ciudades presentes en el archivo, mientras que la segunda línea es su cabecera. Una ciudad puede estar repetida en varias líneas del archivo pero con un indicador diferente.
Escriba un programa en Python que cree el diccionario indicadores, el arreglo ciudades y la matriz M utilizados en el TEMA 1.
Rúbrica: crear diccionario ( puntos), crear arreglo ( puntos), crear matriz ( puntos) Nota: puntos detallados no indicados en el impreso del examen original.
2da Evaluación I Término 2019-2020, Agosto 30, 2019
Tema 1. (50 puntos) Asuma que tiene la matriz M cuyas filas representan ciudadesdel mundo, las columnas representan indicadores de innovacióny cada celda contiene el valor que tiene la ciudad para un indicador.
Además, cuenta con el diccionario indicadores con el siguiente formato:
Finalmente, cuenta con un arreglo ciudades con los nombres de las ciudades en el mismo orden que aparecen en las filas de la matriz M.
Implemente las siguientes funciones:
a. obtenerPuntajes(M, indicadores, indicador) que recibe la matriz M , el diccionario de indicadores , y el nombre de un indicador; y devuelve un vector con el puntaje obtenido por cada ciudad en ese indicador.
Por ejemplo: Si una ciudad, tiene un valor de 15 para el indicador 'Num empresas', obtendrá 2 como puntaje.
b. crearMatrizPuntajes(M, indicadores) que recibe la matriz M y el diccionario de indicadores; y retorna una matriz de puntajes( P) cuyas filas representan ciudades, las columnas representan indicadores y el valor de cada celda representa el puntaje obtenido por esa ciudad en ese indicador.
c. topCiudades(P, minPuntaje, ciudades, K) que recibe una matriz de puntajes P, un puntaje mínimo, el arreglo con los nombres de las ciudades y un entero K; y retorna un arreglo con los nombres de las ciudades cuyo total de puntos en los primeros K indicadores (columnas) sea al menos minPuntaje.
d. numEmpresas(M, P, indicadores, N) que recibe la matriz M ,una matriz de puntajes P, el diccionario indicadores y un entero N. Encuentre las N ciudades con mayor puntaje total y retorne el número promedio de empresas (indicador 'Num empresas') de esas ciudades.
Rúbrica: literal a (14 puntos), literal b (12 puntos), literal c (10 puntos), literal d (14 puntos)
2da Evaluación II Término 2018-2019. 2-Febrero-2019 /CCPG001
Sección 3. Función para crear diccionario
Para el siguiente numeral, asuma que tiene un diccionario con los nombres de todas las especies del ártico en el siguiente formato:
dicEspecies = {codigo_especie:nombre_especie}
5. crearDiccionario(mHielo, mAnimales, dicEspecies) que recibe una matriz de hielo, una matriz de animales y el diccionario de las especies del Ártico.
La función crea un diccionario con los datos anteriore similar al mostrado:
2da Evaluación II Término 2018-2019. 2-Febrero-2019 /CCPG001
(Editado para tarea, se manteniene el objetivo de aprendizaje) Sección 2. Descripción del Problema y funciones con matrices (pregunta 2,3,4)
Para el resto del examen considere lo siguiente:
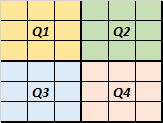
Cuadrantes de la matriz
Las matrices pueden ser divididas en cuadrantes, cuatro subregiones de igual tamaño, denominados:
Q1, Q2, Q3 y Q4
como se muestra en la gráfica:
Asuma que existen las siguientes funciones:
a. cuadrantes(matriz) que recibe una matriz y devuelve un vector con los cuadrantes de la matriz [Q1, Q2, Q3, Q4], que son a su vez matrices (arreglos).
b. poblacionEspecie(mAnimales, especie) que recibe una matriz de animales, el código de una especie y determina la cantidad total de animales de esa especie en cada uno de los cuadrantes. El resultado es un vector con el siguiente formato [pQ1, pQ2, pQ3, pQ4].
Realice las funciones:
2.densidadHielo(mHielo) que recibe una matriz de hielo y determina la densidad de hielo para cada cuadrante. El resultado es un vector con el formato [dQ1, dQ2, dQ3, dQ4].
La densidad de un cuadrante es la cantidad total de sus celdas con valor uno (1) dividido para el número total de celdas del cuadrante.
3.especieDominante(mAnimales) que recibe una matriz de animales y encuentra la especie dominante por cuadrante.
El resultado es un vector con los códigos de la especie que más se repite en cada cuadrante: [eQ1, eQ2, eQ3, eQ4]
4. migracionEspecie(mAnimales2009, mAnimales2019, especie) que recibe la matriz de animales del 2009, la matriz de animales del 2019 y el código de una especie. La función debe retornar un vector [a,b] con dos valores:
a. El primer valor corresponde al cuadrante donde hubo mayor población de animales de la especie en el 2009.
b. El segundo valor corresponde al cuadrante donde hay mayor población de animales de la especie en el 2019.
Los valores son los códigos de los cuadrantes: 'Q1', 'Q2','Q3', 'Q4'
2da Evaluación II Término 2018-2019. 2-Febrero-2019 /CCPG001
Sección 4. Programa que usa las funciones de la sección 1, 2, 3 (preguntas 6-9)
implemente un programa principal que:
6. Forme las matrices a partir del archivo 'artico2009-2019.txt'
7. Muestre por pantalla el código de las especies que en el 2019 son comunes (se repiten) para los cuadrantes Q1, Q2 y Q4 pero que no existan en Q3.
Los siguientes dos numerales se resuelven juntos.
8. Determine si ha habido migración de la especie con código 3. Existe migración si el cuadrante con mayor población en el 2009 y 2019 son diferentes .
9. Una posible explicación para la migración de una especie puede ser el deshielo. Entonces, si existió migración (de la especie con código 3) del cuadrante con mayor población en el 2009 (Qx) al cuadrante con mayor población en el 2019 (Qy), muestre la diferencia (positiva o negativa) de densidad de hielo del 2009 al 2019 para el cuadrante Qx.
Calcule la diferencia con la siguiente fórmula:
Diferencia = densidad_Qx_2019 - densidad_Qx_2009
Por ejemplo:
Si migracionEspecie retorna ('Q1', 'Q4'), la diferencia será la densidad de hielo en el 2009 del cuadrante ‘Q1’ menos la densidad de hielo en el 2019 del mismo cuadrante ‘Q1’.
Para esto dispone de información sobre la cantidad de hielo y población de animales de diversas especies durante los años 2009 y 2019 en un archivo con el siguiente formato:
Número de filas
Número de columnas
Año,fila,columna,hielo,especie
crearMatriz(nomArchivo) que recibe el nombre del archivo con los datos de la WWF y retorna una tupla que contiene las siguientes cuatro matrices:
mhielo2009: Cantidad de hielo 2009
1
0
0
1
…
0
1
1
1
…
1
0
1
0
…
1
1
1
0
…
0
1
0
1
…
1
1
1
0
…
…
…
…
…
…
mhielo2019: Cantidad de hielo 2019
1
0
0
1
…
0
1
0
1
…
1
0
1
0
…
1
0
1
0
…
0
1
0
1
…
0
0
1
0
…
…
…
…
…
…
mAnimales2009: Especies de animales 2009
1
2
4
4
…
2
5
5
3
…
1
3
9
1
…
1
1
4
2
…
4
22
4
7
…
1
1
14
4
…
…
…
…
…
…
mAnimales2019: Especies de animales 2019
3
2
4
1
…
0
11
3
5
…
1
0
67
1
…
2
22
3
2
…
13
13
2
3
…
3
0
1
0
…
…
…
…
…
…
En las matrices de hielo cada valor uno (1) en una celda representa la presencia de hielo.
En las matrices de animales cada celda representa la presencia de un animal de una especie usando una cierta codificación, como la del ejemplo:
0: No hay animal
1: Lobo ártico
2: Oso Polar
3: Reno
4: Foca
5: ...
Rúbrica: numeral 1 (15 puntos): abrir y cerrar archivo, procesar lineas de tamaño de matriz, crear matrices, procesar líneas de datos de matriz, llenar matrices.
2da Evaluación I Término 2018-2019. 31-Agosto-2018 /CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
Tema 2. (50 puntos) Una compañía, con miles de empleados y varias sucursales en el país, paga sus salarios por hora clasificadas como:
- horas regulares (HR),
- horas fuera de horario normal (HER),
- fines de semana (HFDS) y
- feriados (HF).
El registro de asistencia de los empleados contiene: dia, mes, año, cantidad de horas trabajadas, entre otros mostrados en el archivo ejemplo.
El archivo inicia con líneas del valor en dólares por hora, los factores de pago por tipo, una linea de encabezado y el detalle de las horas trabajadas por empleado. Por ejemplo:
VH,10,Valor Hora en ésta compañía
HR,1,Factor Horas Regulares
HER,1.21,Factor Horas Extras en dias Regulares (lunes-viernes)
HFDS,1.37,Factor Horas en Fin De Semana (Sabado o domingo)
HF,1.39,Factor Horas en Feriado
Fecha,dia,feriado,ID,nombre,sucursal,ciudad,horas-trabajadas
...
10-Agosto-2018,5,Si,FG848801,Fabricio Granados,River Mall,Cuenca,1
10-Agosto-2018,5,Si,GH907603,Segunda Vez Zambrano,River Mall,Cuenca,1
09-Agosto-2018,4,No,FG848801,Fabricio Granados,River Mall,Cuenca,9
...
Las horas extras en días regulares se calculan después de la 8va hora de trabajo.
Si el empleado trabajó en un dia feriado, que también es fin de semana, el factor aplicado es el más alto, es decir feriado.
Desarrolle las funciones descritas a continuación y un programa para calcular los valores a pagar para cada empleado.
a) calcularHoras(linea). Recibe una línea del archivo y determina el número de horas trabajadas para cada categoría. El resultado es una tupla con el identificador del empleado, ciudad y horas trabajadas regulares, extras, fines de semana y feriado.
>>> linea = "09-Agosto-2018,4,No,FG848801,Fabricio Granados, River Mall, Cuenca,9"
>>> calcularHoras(linea)
('FG848801','Cuenca',8,1,0,0)
b) leerData(nomA). Recibe el nombre del archivo de nómina (nomA) correspondiente a un mes de un año y retorna una tupla de tres elementos: (totales, mes, año). Totales es un diccionario con la suma en dólares de HR, HER, HFDS y HF trabajados por cada empleado con la siguiente estructura:
c) generaReporte(nomA). Recibe el nombre del archivo de nómina (nomA) correspondiente a un mes de un añoy genera un nuevo archivo reporte para cada ciudad.
Cada archivo reporte tiene como nombre "ciudadMes-Año.txt" y contiene: cabecera y la siguiente información por cada empleado: