2da Evaluación I Término 2018-2019. 31-Agosto-2018 /CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)

Tema 1. (40 puntos) Para analizar los niveles de seguridad en el país, se registran los incidentes por ciudad y tipo delito en un archivo.
| robo vehículo | asalto | Escandalo vía pública | … | |
|---|---|---|---|---|
| Quito | 540 | 4523 | 24 | … |
| Guayaquil | 605 | 6345 | 5 | … |
| Cuenca | 123 | 676 | 133 | … |
| Machala | 67 | 1234 | 412 | … |
| … | … | …. | …. | … |
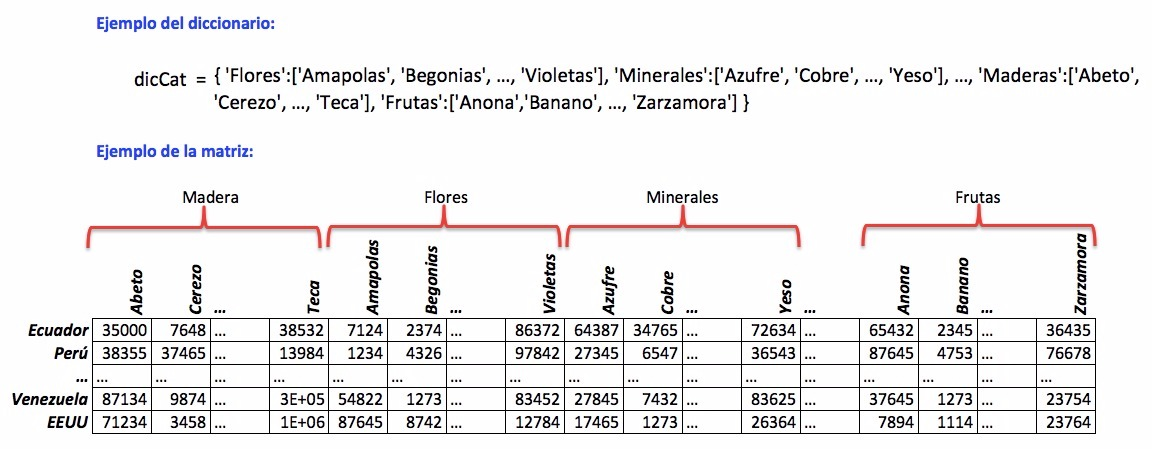
Dispone de un modulo «ecu911» con la función cargarDatos(nombrearchivo) que lee el archivo y entrega un diccionario con la las veces que se ha reportado cada tipo de delito para cada ciudad del país en el siguiente formato:
diccionario = {
'Guayaquil':{'robo vehiculo':605, 'asalto':6345, ...},
'Cuenca': {'robo vehiculo':123, 'asalto': 676, ...},
...
}
Para crear el diccionario debe importar el módulo.
Se requiere implementar lo siguiente:
a. Una función tablatitulos(diccionario) que recibe el diccionario descrito y retorna una coleccion:
titulos = (ciudad, tipodelito)
ciudad contiene las ciudades del archivo, y tipodelito contiene los tipos considerados en el diccionario, ambos sin duplicados.
b. La función crearMatriz(diccionario) que usando la información del diccionario crea una matriz con el número de incidentes por ciudad y tipo de delito. La matriz es un arreglo de numpy, semejante al ejemplo:
>>> matriz
array([[ 530, 4523, 24, ...],
[ 605, 6345, 5, ...],
[ 123, 676, 133,...],
[ 67, 1234, 412, ...],
...
])
c. Una función ciudadesMenosSeguras(matriz, titulos, untipo, poblacion) que retorna los nombres de las tres ciudades que tienen el mayor indice per capita de para untipo de delito.
\text{indice per capita} = \frac{\text{numero de incidentes reportados}}{\text{poblacion de la ciudad}}La función recibe la matriz , titulos de los literales anteriores, un tipo de delito y la población de cada ciudad del país en un vector, arreglo Numpy.
Rúbrica: literal a (10 puntos), literal b (20 puntos), literal c (10 puntos).
Referencia: Archivo original 2daEvaI_Term2018.pdf