1ra Evaluación I Término 2018-2019, Junio 29, 2018. CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
Tema 2. (50 puntos) Dispone de una tabla con el desempeño histórico (estadística) de los jugadores equipos (país) que participan en el Mundial de Futbol:
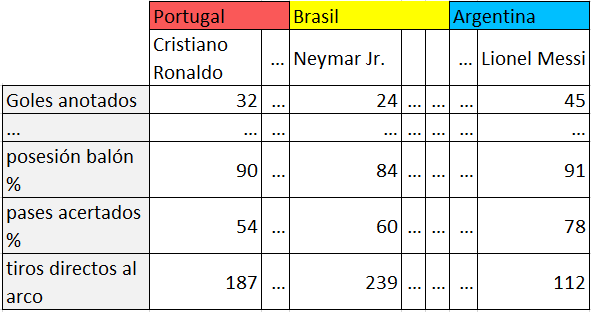
Los jugadores se encuentran ordenados por equipos siguiendo el orden del listado de países siguiente:
paises = ['Portugal', 'Brasil', … , 'Argentina']
Dispone de otra tabla con los equipos (país) y jugadores, conformada como una lista que contiene como elementos otras listas (lista de listas):
pais_jugadores = [prtgl,
brsl,
…,
argntn]
Cada elemento de la tabla pais_jugadores contiene los nombres de los jugadores registrados en cada equipo:
prtgl = ['Cristiano Ronaldo', …]
brsl = ['Neymar Jr.', … ]
…
argntn = [ …, 'Lionel Messi']
con los datos disponibles en las tablas y usando instruciones de Python, se requiere:
a. Determinar el país con el promedio de goles más alto.
\text{promedio de goles} =\frac{\text{goles anotados del país}}{\text{numero de jugadores del país}}
b. Contar cuántos jugadores españoles tienen una efectividad mayor que la efectividad promedio de España.
\text{efectividad} = \frac{\text{goles anotados}}{\text{Tiros directo al arco}}
c. Mostrar la lista con los nombres de los jugadores que tienen más del 76% de posesión del balón .
d. Mostrar el jugador con mayor porcentaje de pases acertados, indicando nombre y país al que pertenece.
e. Calcular el promedio mundial por cada una de las características.
( “Goles anotados", "...", "% posesión del balón", "% de pases acertados", "Tiros directos al arco" ).
f. Determine si cada una las características para el jugador "Lionel Messi" están por encima del correspondiente promedio mundial. Muestre el mensaje de respuesta correspondiente:
“Lionel Messi está/no está por encima del promedio mundial”
Sugerencia: Separe el trabajo de ubicar los jugadores de la tabla, del procesamiento de los datos de desempeño.
Para ubicar los jugadores realice una tabla siguiendo las siguientes instrucciones:
1. A partir de los datos pais_jugadores y las listas de jugadores, bosqueje la tabla que se forma como referencia.
2. Unifique en un vector jugadores a todos los de cada país.
3. Realice una tabla en cuyas filas ubique cada pais con el índice [desde, hasta, cuantos] que indica las posiciones desde/hasta dónde se cuentan los jugadores para cada pais, además de la cantidad de jugadores.
Ésta última tabla permitirá ubicar a los jugadores por países.
Para probar los algoritmos, puede usar los datos de las tablas simplificadas para prueba:
desempeno = np.array([[ 32, 24, 45],
[ 90, 84, 91],
[ 54, 60, 78],
[187,239,112]])
paises = ['Portugal', 'Brasil', 'Argentina']
prtgl = ['Cristiano Ronaldo']
brsl = ['Neymar Jr.' ]
argntn = ['Lionel Messi']
pais_jugadores = [prtgl, brsl, argntn]
Referencia: Archivo original 1raEvaI_Term2018.pdf