Referencia: Ross 8.17 p.571
Los clientes llegan a una sucursal de dos servidores según a un proceso de Poisson con tasa de dos por hora.
Si al llegar el cliente el servidor 1 esta libre, se atiende con éste.
Si al llegar el cliente el servidor 1 esta ocupado y el servidor 2 esta libre, inicia con el servidor 2.
Clientes que al llegar encuentran los dos servidores ocupados se retiran.
Un cliente que fué atendido por el servidor 1, pasa a ser atendido por el servidor 2 siempre que esté libre, caso contrario sale de la sucursal.
Un cliente al completar el servicio con el servidor 2 sale de la sucursal.
Los tiempos de servicio en los servidores 1 y 2 son variables aleatorias exponenciales con tasas de cuatro y seis por hora.
a) ¿Qué fracción de clientes no entran a la sucursal?
b) ¿Cuál es el valor promedio de tiempo que un cliente que entra, permanece en el sistema?
c) ¿Cuál fracción de los clientes que entraron son atendidos por el servidor 1?
Solución:
Se definen los estados como (servidor1,servidor2), ocupado=0, ocupado=1:
Estado (0,0)
Estado (0,1)
Estado (1,0)
Estado (1,0)

con lo que se contruye el diagrama de estados y transiciones:
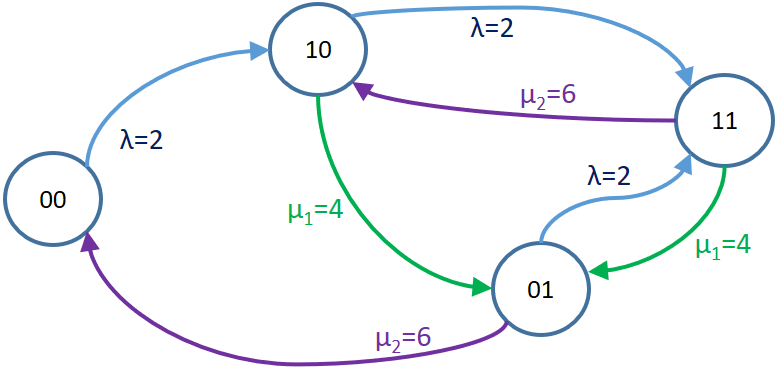
Usando los valores del enunciado se ubican los valores para las tasas de llegada y atención
El siguiente paso consiste en escribir son las ecuaciones de balanceo:
λ P00 = μ2 P01
(μ2 + λ) P01 = μ1 P10 + μ1 P11
(μ1 + λ) P10 = λ P00 + μ2 P11
(μ2 + μ1) P11 = λ P01 + λ P10
1 = P00 + P01 + P10 + P11
usando los valores para λ, μ1 y μ2:
2 P00 = 6 P01
8 P01 = 4 P10 + 4 P11
6 P10 = 2 P00 + 6 P11
10 P11 = 2 P01 + 2 P10
1 = P00 + P01 + P10 + P11
de la ecuación(1)
P01 = (2/6) P00 = (1/3) P00
P01 = (1/3) P00
usando (2) (1/4) y reordenando
2 P01 = P10 + P11
P11 = 2 P01 - P10
sumando con (4)
P11 = 2 P01 - P10
5 P11 = P01 + P10
6 P11 = 3 P01
2 P11 = P01
usando (1)
2 P11 = (1/3) P00
P11 = (1/6) P00
usando (4)
5 P11 = P01 + P10
5 (1/6) P00 = (1/3) P00 + P10
P10 = [(5/6) - (1/3)]P00 = [(5-2)/6] P00 = (3/6) P00 = (1/2) P00
P10 = (1/2) P00
usando (5) con los resultados dependientes de P00:
1 = P00 + (1/3) P00 +(1/2) P00 + (1/6) P00
1 = [(6+2+3+1)/6] P00 = [12/6] P00 = 2 P00
P00 = 1/2
quedando:
P00 = 1/2
P01 = 1/6
P10 = 1/4
P11 = 1/12
usando numpy de python, se reorganiza las ecuaciones y se crean las matrices:
2 P00 - 6 P01 = 0
8 P01 - 4 P10 - 4 P11 = 0
2 P00 - 6 P10 + 6 P11 = 0
2 P01 + 2 P10 - 10 P11 = 0
P00 + P01 + P10 + P11 = 1
import numpy as np
A=np.array([
[2,-6,0,0],
[0,8,-4,-4],
[2,0,-6,6],
[1,1,1,1]])
B=np.array([0,0,0,1])
P=np.linalg.solve(A,B)
print(P)
[ 0.5 0.16666667 0.25 0.08333333]
que son los resultados anteriores encontrados:
P00 = 0.5
P01 = 0.16666667
P10 = 0.25
P11 = 0.08333333
a) ¿Qué fracción de clientes no entran a la suscursal?
solo ocurre cuando ambos servidores estan ocupados (1,1)
P11 = 1/12 = 0.08333333
b) ¿Cuál es el valor promedio de tiempo que un cliente que entra, permanece en el sistema?
W = L/λ
= (valor esperado)/(proporcion de los clientes que si entran)
= [0*P00 + 1*P01 + 1*P10 + 2*P11]/ [λ(1-P11)]
= [0*(1/2) + 1*(1/6) + 1*(1/4) + 2*(1/12)]/ [2(1-(1/12)]
= [(0+3+2+2)/12]/[22/12] = (7/12)/(22/12) = 7/22
c) ¿Cuál fracción de los clientes que entraron son atendidos por el servidor 1?
(atiende el servidor 1 cuando esta libre) / (los que entraron)
[P00 + P01] / [1 - P11] = [1/2 + 1/6]/[1 - 1/12]
= [(3+1)/6] / [11/12] = (4/6)/(11/12) = 8/11