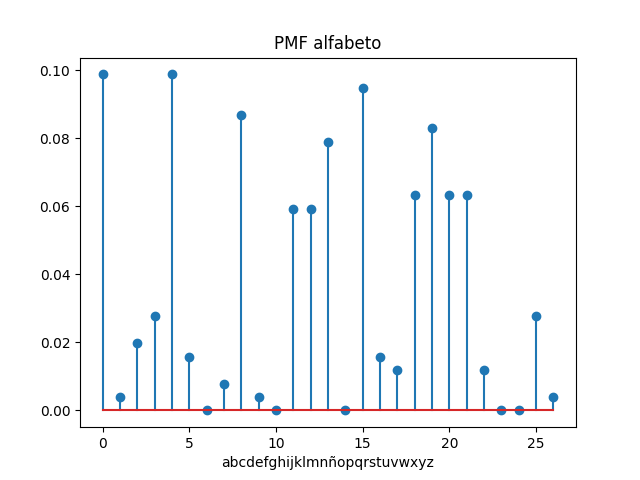
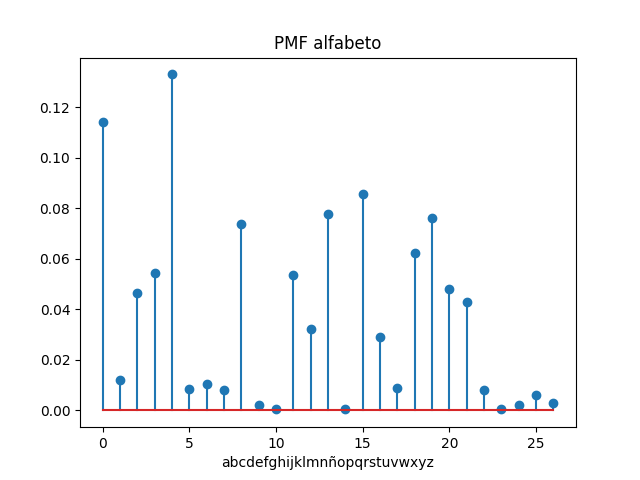
Referencia: Teclado Qwerty Wikipedia
Uso del teclado QWERTY

El nombre del teclado QWERTY proviene de las primeras seis letras de su fila superior, fue diseñado y patentado por Christopher Sholes en 1868 y vendido a Remington en 1873.
La distribución QWERTY se diseñó con objetivo de separar las letras más usadas de la zona central del teclado, para evitar que se atascaran las máquinas de escribir de primera generación. Actualmente, ésta propiedad no es más requerida, sin embargo se ha heredado la distribución en los teclados de computadora.
A partir de la frecuencia de uso de las letras del alfabeto, se requiere conocer la frecuencia de uso de cada fila del teclado. Los valores de frecuencia para cada letra se encuentran en el archivo: usoletras.txt que por cada línea registra la letra y frecuencia relativa separadas por una coma ','.
archivo: usoletras.txt:
a, 0.11422682511
b, 0.0118959769969
c, 0.0464006717728
d, 0.0543525280541
...Algoritmo en Python
# Analiza teclado QWERTY
# Datos desde Archivo 'usoletras.txt'
import numpy as np
# Ingreso
narchivo = input('Nombre del archivo:')
veces = []
archivo = open(narchivo,'r')
linea = archivo.readline()
while not(linea == ''):
partes = linea.split(',')
letra = partes[0]
frecuencia = float(partes[1])
veces.append([letra,frecuencia])
linea = archivo.readline()
archivo.close()
# PROCEDIMIENTO
superior = 'qwertyuiop'
media = 'asdfghjklñ'
inferior = 'zxcvbnm'
k = len(veces)
usofila = np.zeros(3,dtype=float)
for i in range(0,len(veces),1):
if (veces[i][0] in superior):
usofila[0] = usofila[0]+veces[i][1]
if (veces[i][0] in media):
usofila[1] = usofila[1]+veces[i][1]
if (veces[i][0] in inferior):
usofila[2] = usofila[2]+veces[i][1]
# SALIDA
print(usofila)
resultado:
[ 0.48999975 0.32815084 0.18184941]
La gráfica para pmf se obtiene al añadir las instrucciones:
# GRAFICA
import matplotlib.pyplot as plt
plt.stem([0,1,2],usofila)
plt.title('PMF filas teclado QWERTY')
plt.xlabel('fila superior, media e inferior')
plt.show()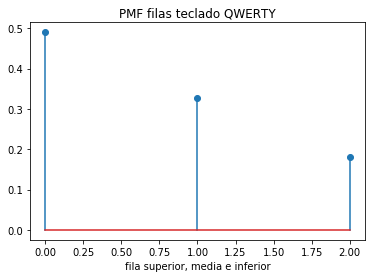
Tarea: En cada caso, realice la gráfica de funciones de probabilidad de masa (pmf) y la función de probabilidades acumulada (cdf)
Encuentre la frecuencia de uso de cada mano, presente la división propuesta de el teclado en dos partes: izquierda y derecha.
Realice el ejercicio para determinar la frecuencia de uso de cada dedo de cada mano. Presente un modelo gráfico de cada tecla, para mostrar de mejor forma la medida a obtener
con los resultados de éste ejercicio, considere llenar la siguiente tabla:
| mano izquierda | mano derecha | total fila | |
|---|---|---|---|
| superior | |||
| media | |||
| inferior | |||
| total mano |