
Actualizar data.frame utilizando como referencia otro data.frame
Escribo este post como respuesta a una pregunta de un colega y además porque sirve muy bien como ejemplo para entender un poco más del indexado de R.
Problema
Supongamos que tenemos las calificaciones de un curso en un data.frame, algo así como:
# Declarar una semilla para reproducibilidad del ejemplo set.seed(5) # crear un data.frame base df_base <- data.frame(Alum = LETTERS[1:6], Mat = sample(x = 1:10, size = 6, replace = TRUE), Len = sample(x = 1:10, size = 6, replace = TRUE)) # presentar data.frame df_base ## Alum Mat Len ## 1 A 3 6 ## 2 B 7 9 ## 3 C 10 10 ## 4 D 3 2 ## 5 E 2 3 ## 6 F 8 5
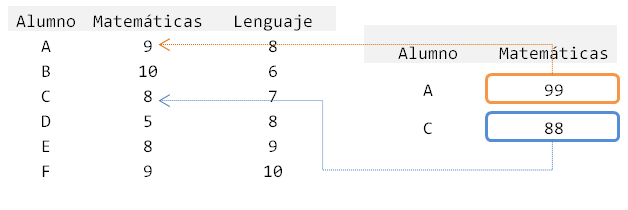
Pero luego de una recalificación debemos cambiar las notas de matemáticas a los alumnos C, E y F según lo siguiente:
# crear un data.frame que contendra los valores a modificar df_modificatorio <- data.frame(Alum = c("E", "C"), Mat = c(99, 88)) # presentar data.frame df_modificatorio ## Alum Mat ## 1 E 99 ## 2 C 88
¿Que opciones hay para hacerlo en R?
Soluciones
Reemplazo uno a uno
Bueno, si fuesen pocos elementos lo más sencillo es hacerlo observación a observación filtrando en este caso el alumno y la variable que se va a modificar, en R sería:
Pero obviamente esto no es una opción a considerar si son muchos reemplazos a la vez o si lo que se quiere es realizar un script donde el data.frame df_modificatorio cambiará a cada ejecución del script, por lo que pasamos a la siguiente opción
Reemplazo por conjunto de valores y filtrando por una sóla variable (esta solución tiene limitantes)
¡¡¡Peligro, No usar el operador %in%!!!
Normalmente cuando se desea hacer un filtro para varios elementos se usa el operador %in%, pero en este caso este oprador nos puede llevar a cometer errores puesto que %in% devuelve todos los valores coincidentes pero en el orden del data.frame original y si por un lado tenemos los valores en el orden original (df_base) y por el otro los valores ordenados de otra forma (df_modificatorio) entonces asignaremos erroneamente los valores, lo explico mejor en el bloque de código
# Creamos nuevamente el data.frame df_base set.seed(5) df_base <- data.frame(Alum = LETTERS[1:6], Mat = sample(x = 1:10, size = 6, replace = TRUE), Len = sample(x = 1:10, size = 6, replace = TRUE)) df_base ## Alum Mat Len ## 1 A 3 6 ## 2 B 7 9 ## 3 C 10 10 ## 4 D 3 2 ## 5 E 2 3 ## 6 F 8 5 # que pasa si usamos la funcion %in%? Pues se nos devuelven los valores # que queremos pero en el orden original, osea C,D df_base[df_base$Alum %in% df_modificatorio$Alum, ] ## Alum Mat Len ## 3 C 10 10 ## 5 E 2 3 # utilizar %in% para realizar la asignación: df_base[df_base$Alum %in% df_modificatorio$Alum, "Mat"] <- df_modificatorio[df_modificatorio$Alum %in% df_base$Alum, "Mat"] # Presentar df_base, se puede ver el error que involucra usar %in% pues en # lugar de asignar 88 al C y 99 al E, hizo lo contrario df_base ## Alum Mat Len ## 1 A 3 6 ## 2 B 7 9 ## 3 C 99 10 ## 4 D 3 2 ## 5 E 88 3 ## 6 F 8 5 # Paso a Paso la operacion anterior: Filtrar los alumnos de df_base que # estan en df_modificatorio df_base[df_base$Alum %in% df_modificatorio$Alum, ] ## Alum Mat Len ## 3 C 99 10 ## 5 E 88 3 # Paso a Paso la operacion anterior: Filtrar los alumnos de df_base que # estan en df_modificatorio mostrando sólo los valores de la variable # 'Mat' df_base[df_base$Alum %in% df_modificatorio$Alum, "Mat"] ## [1] 99 88 # Paso a Paso la operacion anterior: Filtrar los alumnos de # df_modificatorio que estan en df_base mostrando sólo los valores de la # variable 'Mat' df_modificatorio[df_modificatorio$Alum %in% df_base$Alum, "Mat"] ## [1] 99 88 # Se puede ver entonces, el porque el uso de %in% nos lleva a cometer # errores.
Solucion parcial: función match
En este caso nos sirve bien la función match, en resumen la funcion match devuelve los valores en orden que contienen cada uno de los valores buscados; esta función tiene otras restricciones que se comentarán luego
# Creamos nuevamente el data.frame df_base set.seed(5) df_base <- data.frame(Alum = LETTERS[1:6], Mat = sample(x = 1:10, size = 6, replace = TRUE), Len = sample(x = 1:10, size = 6, replace = TRUE)) df_base ## Alum Mat Len ## 1 A 3 6 ## 2 B 7 9 ## 3 C 10 10 ## 4 D 3 2 ## 5 E 2 3 ## 6 F 8 5 # filtrar usando de la función match(), nótese respeta el orden original # del data.frame baseicamente, se le está diciendo buscame los valores del # df_modificatorio variable Alum en la tabla df_base variable Alum se hace # df_modificatorio[ df_modificatorio$Alum %in% df_base$Alum, 'Alum' ]) en # lugar de df_modificatorio$Alum para asegurar que sólo se tome en cuenta # los valores de df_modificatorio$Alum tiene algun valor que no esta en # df_base$Alum df_base[match(x = df_modificatorio[df_modificatorio$Alum %in% df_base$Alum, "Alum"], table = df_base$Alum, nomatch = FALSE), ] ## Alum Mat Len ## 5 E 2 3 ## 3 C 10 10 # utilizar match para realizar la asignación, la parte izquierda de la # asignacion (<-) se utiliza match pues queremos los elementos de df_base # en el orden de df_modifcatorio mientras que para la parte derecha de la # asignacion (<-) se utiliza %in% pues queremos conservar el orden de # df_modifcatorio df_base[match(x = df_modificatorio[df_modificatorio$Alum %in% df_base$Alum, "Alum"], table = df_base$Alum, nomatch = FALSE), "Mat"] <- df_modificatorio[df_modificatorio$Alum %in% df_base$Alum, "Mat"] # presentar data.frame con valores modificados df_base ## Alum Mat Len ## 1 A 3 6 ## 2 B 7 9 ## 3 C 88 10 ## 4 D 3 2 ## 5 E 99 3 ## 6 F 8 5
Problemas/Limitaciones de la función match.-
Los principales problemas son:
- Identificadores no repetidos.- La función
matches util cuando se tienen identificadores únicos (en el ejemplo, los alumnos), pero cuando estos elementos no son únicos no se debe usar match pues esta función devuelve el índice del primer elemento coincidente, por lo tanto sólo reemplazará al primer elemento coincidente del data.frame dejando a los demas sin actualizar el valor.
- Sólo filtra para una variable.- No es posible enviar más de una variable a la función
match, es decir, si por ejemplo deseamos filtrar los Alumnos por dos variables, por ejemplo Codigo y Mes, entonces la función match nos devolvería un error
Se ilustra el primer punto a continuación
# Creamos nuevamente el data.frame df_base set.seed(5) df_base <- data.frame(Alum = LETTERS[1:6], Mat = sample(x = 1:10, size = 6, replace = TRUE), Len = sample(x = 1:10, size = 6, replace = TRUE), stringsAsFactors = FALSE) # aumentaremos una fila con Alum repetido para ilustrar el error df_base <- rbind(df_base, c("E", 1, 1)) df_base ## Alum Mat Len ## 1 A 3 6 ## 2 B 7 9 ## 3 C 10 10 ## 4 D 3 2 ## 5 E 2 3 ## 6 F 8 5 ## 7 E 1 1 # actualizar valores df_base[match(x = df_modificatorio[df_modificatorio$Alum %in% df_base$Alum, "Alum"], table = df_base$Alum, nomatch = FALSE), "Mat"] <- df_modificatorio[df_modificatorio$Alum %in% df_base$Alum, "Mat"] # presentar data.frame con valores modificados df_base ## Alum Mat Len ## 1 A 3 6 ## 2 B 7 9 ## 3 C 88 10 ## 4 D 3 2 ## 5 E 99 3 ## 6 F 8 5 ## 7 E 1 1 # ERROR: Se puede ver que sólo al primer 'E' se le actualizó el valor
Para evitar este error modificaremos nuestra forma de asignar de la siguiente manera:
- En la parte izquierda de la asignación se va a realizar el filtro usando %in% (en
df_base), recuerde que esto implica que se mantendrá el orden del data.frame cuyos valores van a ser modificados - Ahora se debe filtrar el data.frame que contiene los nuevos valores siguiendo el orden del otro data.frame, para ello usamos match()
De la siguiente manera:
# Creamos nuevamente el data.frame df_base set.seed(5) df_base <- data.frame(Alum = LETTERS[1:6], Mat = sample(x = 1:10, size = 6, replace = TRUE), Len = sample(x = 1:10, size = 6, replace = TRUE), stringsAsFactors = FALSE) # aumentaremos una fila con Alum repetido para ilustrar el error df_base <- rbind(df_base, c("E", 1, 1)) df_base ## Alum Mat Len ## 1 A 3 6 ## 2 B 7 9 ## 3 C 10 10 ## 4 D 3 2 ## 5 E 2 3 ## 6 F 8 5 ## 7 E 1 1 # se ilustra el filtro a usar en la parte izquierda de la asignación df_base[df_base$Alum %in% df_modificatorio$Alum, ] ## Alum Mat Len ## 3 C 10 10 ## 5 E 2 3 ## 7 E 1 1 # se ilustra el filtro a usar en la parte derecha de la asignación df_modificatorio[match(x = df_base[df_base$Alum %in% df_modificatorio$Alum, "Alum"], table = df_modificatorio$Alum, nomatch = FALSE), ] ## Alum Mat ## 2 C 88 ## 1 E 99 ## 1.1 E 99 # asignar usando %in% y match() df_base[df_base$Alum %in% df_modificatorio$Alum, "Mat"] <- df_modificatorio[match(x = df_base[df_base$Alum %in% df_modificatorio$Alum, "Alum"], table = df_modificatorio$Alum, nomatch = FALSE) , "Mat"] # presentar data.frame con valores modificados df_base ## Alum Mat Len ## 1 A 3 6 ## 2 B 7 9 ## 3 C 88 10 ## 4 D 3 2 ## 5 E 99 3 ## 6 F 8 5 ## 7 E 99 1 # Se puede ver como los dos 'E' han sido acrtualizados
Para el segundo punto (imposibilidad de utilizar varias variables como filtro) usaremos el comando merge
Solución general utilizando merge (ie. join, buscarv, lookup)
En la segunda parte de esta entrada se explica este punto =).