
Aquí pueden encontrar algunos conjuntos de datos (datasets)
Python - Parte III
 En la última parte de este tutorial de Pandas, procederemos a graficar nuestros resultados. Para esto, necesitamos instalar la librería matplotlib
En la última parte de este tutorial de Pandas, procederemos a graficar nuestros resultados. Para esto, necesitamos instalar la librería matplotlib
Instalación
pip install matplotlib
Instrucciones básicas
Y, para comenzar a utilizarla, debemos importarla en nuestro programa.
import matplotlib.pyplot as plt
Ejercicio:
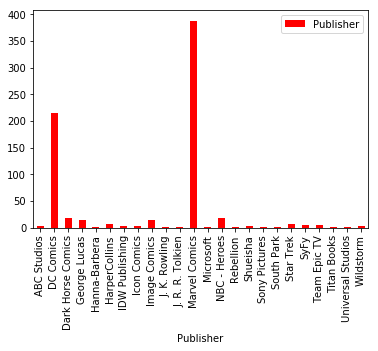
¿Cuántos superhéroes pertenecen por cada editorial?
Aquí suena a que habrá que incluir unas cuántas operaciones antes de mostrar un gráfico.
- Importa las libreríasimport pandas as pd
import matplotlib.pyplot as plt
- Lee el archivo local.superheroes = pd.read_csv( ‘heroes_information.csv’ )
- Utiliza el groupby por la o las columnas que se solicitangrupos = superheroes.groupby('Publisher')
- Seleccionar la o las columnas solicitadascolumnas = grupos[['Publisher']]
- Realizar la operación que se solicita, en este caso el número total hace referencia a contar todos los valores.resultado = columnas.count()
- Ahora, es cuestión de graficar los resultados. Aquí deberás escoger cuál representa las filas y cuál representa las columnas de nuestro gráfico. resultado.plot.bar(color='red')
plt.show()
- El gráfico que aparecerá luce así

Otros tipos de gráficos.
Ejercicios
- Por editorial, ¿Cuántos superhéroes superan los 190cm?
- Promedio de estatura por color de piel.
- Por alineación y raza, ¿Cuántos superhéroes de Marvel Comics existen?
Publicado en Varios
Deja un comentario
Python Pandas - II

Superhéroes
En la segunda parte del tutorial, revisaremos el agrupamiento de datos.
Selección de columnas
Trabajar con todas las columnas de un conjunto de datos resulta un poco incómodo por lo que puedes utilizar el subsetting al enviar una lista con el nombre de las columnas que deseas.
nuevosDatos = superheroes[['name','Publisher']]
starwars = nuevosDatos['Publisher'] == 'George Lucas'
print(nuevosDatos[starwars])
starwars = nuevosDatos['Publisher'] == 'George Lucas'
print(nuevosDatos[starwars])
En las instrucciones anteriores creamos un nuevo conjunto de datos llamado nuevosDatos con el que haremos operaciones, aplicamos condiciones, etc.
Agrupamiento
En algunas ocasiones, es necesario realizar operaciones de cálculo (count, sum, mean, max, min) para los diversos grupos de datos, por ejemplo:
"Número total de superhéroes por editorial" o "Máxima altura de superhéroes de acuerdo a su alineación y género"
![]() Para responder al "Total de superhéroes por editorial":
Para responder al "Total de superhéroes por editorial":
- Utiliza el groupby por la o las columnas que se solicitangrupos = superheroes.groupby('Publisher')
- Seleccionar la o las columnas solicitadascolumnas = grupos[['Publisher']]
- Realizar la operación que se solicita, en este caso el número total hace referencia a contar todos los valores.print(columnas.count())
El resultado es el siguiente:
| Publisher | Publisher |
|---|---|
| ABC Studios | 4 |
| DC Comics | 215 |
| Dark Horse Comics | 18 |
| George Lucas | 14 |
| Hanna-Barbera | 1 |
| HarperCollins | 6 |
| IDW Publishing | 4 |
| Icon Comics | 4 |
| Image Comics | 14 |
| J. K. Rowling | 1 |
| J. R. R. Tolkien | 1 |
| Marvel Comics | 388 |
| Microsoft | 1 |
| NBC - Heroes | 19 |
| Rebellion | 1 |
| Shueisha | 4 |
| Sony Pictures | 2 |
| South Park | 1 |
| Star Trek | 6 |
| SyFy | 5 |
| Team Epic TV | 5 |
| Titan Books | 1 |
| Universal Studios | 1 |
| Wildstorm | 3 |
![]() Para el segundo ejemplo: "Máxima altura de superhéroes de acuerdo a su alineación y género"
Para el segundo ejemplo: "Máxima altura de superhéroes de acuerdo a su alineación y género"
Las columnas a agrupar son "Alignment" y "Gender". Las columnas a escoger son "Alignment", "Gender" y "Height". Finalmente, la operación es max.
El resultado se interpreta que
- El superhéroe masculino - malo de mayor altura mide 366.0, y que
- El superhéroe femenino - malo de mayor altura mide 218.0
| Alignment | Gender | Height |
|---|---|---|
| - | - | -99.0 |
| - | Male | 229.0 |
| bad | - | 198.0 |
| bad | Female | 218.0 |
| bad | Male | 366.0 |
| good | - | 193.0 |
| good | Female | 366.0 |
| good | Male | 975.0 |
| neutral | - | -99.0 |
| neutral | Female | 183.0 |
| neutral | Male | 876.0 |
Algunos ejercicios para que practicar:
- El promedio de estatura por género. Asegúrate de eliminar los valores -99 antes de cualquier cálculo.
- Mínimo peso y estatura de los superhéroes Alien y Mutants por editorial
- ¿Cuántos superhéroes existen por color de ojos?
- ¿Cuántos superhéroes existen por color de cabello?
Python Pandas - I
Pandas

Instalación
En este corto tutorial acerca de Pandas, la librería de Python. Primero, será necesario instalar el módulo mediante pip.
pip install pandas
Pandas sirve para procesar conjuntos de datos con un formato específico. Donde el tipo de datos puede variar en cada una de las columnas. Pandas es utiliza como una herramienta para analizar y procesar datos a gran escala.
Conjunto de datos o Dataset
Siempre que trabajemos con Pandas será necesario utilizar un dataset. En este caso utilizaremos el conjunto de datos de superhéroes. Este dataset contiene la información general (nombre, género, raza, color de ojos, estatura, editorial, etc ) de cada superhéroe.
Instrucciones básicas
Ahora, escribiremos nuestro algunas instrucciones para procesar el archivo. Primero, procedemos a cargar el módulo de Pandas
import pandas as pd
Comenzamos cargando el conjunto de datos en memoria, mediante la instrucción read_csv
superheroes = pd.read_csv( 'heroes_information.csv' , encoding= 'utf-8' )
Existen otros encoding como "latin-1", "ISO-8859-1", entre otros.
Por defecto, la primera fila del conjunto de datos corresponde/contiene a los nombres de las columnas.
Para mostrar los datos, simplemente utiliza un print de la variable que contiene el conjunto de datos.
print( superheroes )
![]() ¿Qué vemos en la salida?
¿Qué vemos en la salida?
Además, podemos tener una vista previa de los datos con las instrucciones head o tail.
print( superheroes.head() )
Con head (tail) tendrá una vista previa de lo que te puedes encontrar en el conjunto de datos en las cinco primeras (últimas) filas.

Tanto head como tail permite mostrar más de las 5 filas predeterminadas, para esto podrás enviar un número como parámetro.
print( superheroes.tail(15) )
Con la línea anterior podrás ver los últimos 15 superhéroes en el conjunto de datos.
Para conocer la cantidad de filas y contiene mi conjunto de datos, utilizaremos la instrucción shape que devuelve una tupla con la cantidad de filas y columnas.
nfilas, ncolumnas = superheroes.shape
print( 'Cantidad de superhérores: ' , nfilas)
print( 'Cantidad de superhérores: ' , nfilas)
![]() ¿Cuántas filas y cuántas columnas tiene nuestro conjunto de datos?
¿Cuántas filas y cuántas columnas tiene nuestro conjunto de datos?
Si necesitamos conocer el nombre de las columnas utilizaremos la instrucción:
nombreColumnas = superheroes.columns.values
print( 'Nombres de las columnas:' , nombreColumnas )
print( 'Nombres de las columnas:' , nombreColumnas )
Para referirnos a una columna específica utilizamos su nombre, por ejemplo:
print(superheroes['Publisher'])
Y si necesitáramos saber una lista con valores únicos de Publisher, simplemente hacemos lo siguiente:
print(list(set(superheroes['Publisher'])))
Como te puedes dar cuenta, existen editoriales como 'Marvel Comics', 'DC Comics' y nan. ¿Qué es nan? Pandas utiliza este tipo de dato para representar los vacíos en el conjunto de datos.
Condicionales
A veces, es necesario contar el número de elementos que cumplen con una determinada condición, por ejemplo: ¿Cuántos superhéroes son de DC Comics?
Para resolver esta pregunta, se recurre a:
- Filtra la columna a contar, en este caso Publisher
columna = superheroes['Publisher']
- Crear la condicióncondicion = columna == 'DC Comics'
- Aplicar la condición sobre la columna y contarprint( columna[condicion].count() )
- Deben resultar en 215 superhéroes.
Más preguntas para practicar:
- ¿Cuántos superhéroes buenos existen? Utiliza la columna Alignment y el valor para es good.
- ¿Cuántos superhéroes tienen piel blanca? Utiliza la columna Skin color y el valor es white.
- ¿Cuántos superhéroes tienen los ojos amarillos? Utiliza la columna Eye color y el valor es yellow.
Condicionales complejas
Para unir dos o más condiciones utiliza:
- Cada condición entre paréntesis, y
- Los conectores & (para conjunción - and) u | (para disyunción - or)
Por ejemplo, para la pregunta: ¿Cuáles son los nombres de los superhéroes humanos que son neutrales ?
- Selecciona la columna namecolumnaNombres = superheroes['name']
- Selecciona la columna RacecolumnaRaza = superheroes['Race']
- Selecciona la columna AlignmentcolumnaAlineacion = superheroes['Alignment']
- Crea la condicióncondicion = (columnaRaza == 'Human') & (columnaAlineacion == 'neutral' )
- Filtra la columna name con la condiciónprint( columnaNombres[condicion] )
Operaciones básicas
Desde luego, Pandas tiene un conjunto de operaciones básicas, como: sum, max, min, idxmax, idxmin, mean, para responder a preguntas como:
¿Cuál es el nombre, editorial y peso del superhéroe más pesado?
- Obtén el valor del peso más grandepesoMax = superheroes['Weight'].max()
- Crea la condición con el valor obtenido.condicion = superheroes['Weight'] == pesoMax
- Obtén la fila con el índice obtenidosuperHeroeMasPesado = superheroes[condicion]
- Muestra las característicasprint(superHeroeMasPesado['name'],superHeroeMasPesado['Publisher'], pesoMax )
- Debería mostrar esta informaciónSasquatch Marvel Comics 900.0
Acá encontrarás más detalles de otras operaciones básicas.
Para los siguientes casos deberás considerar que el valor de la estatura/peso no se conoce por lo que han colocado el valor de -99.
- ¿Cuál es el nombre del alien bueno de menor estatura? columnas: name, Alignment ('good'), Race ('Alien') y Height.
- ¿Cuál es la estatura promedio de los mutantes? columnas: Race ('Mutant') y Height.
- ¿Cuántos buenos se encuentran en las editoriales 'HarperCollins' y 'George Lucas'? columnas: Alignment ('good') y Publisher ('HarperCollins' - 'George Lucas')
Python Pandas
![]() Con el propósito de introducir al uso de Pandas, en Python, te dejo un recurso con una recopilación de instrucciones para la manipulación de un conjunto de datos, o dataset.
Con el propósito de introducir al uso de Pandas, en Python, te dejo un recurso con una recopilación de instrucciones para la manipulación de un conjunto de datos, o dataset.