
Luego de hacer zapping horizontal por la web, me encontré con esto:
After immersing yourself into the field of distributed computing and large data sets you inevitably come to appreciate the elegance of Google's Map-Reduce framework. Both the generality and the simplicity of its map, emit, and reduce phases is what makes it such a powerful tool. However, while Google has made the theory public, the underlying software implementation remains closed source and is arguably one of their biggest competitive advantages (GFS, BigTable, etc). Of course, there is a multitude of the open source variants (Apache Hadoop, Disco, Skynet, amongst many others), but one can't help but to notice the disconnect between the elegance and simplicity of the theory and the painful implementation: custom protocols, custom servers, file systems, redundancy, and the list goes on! Which begs the question, how do we lower the barrier...
Plantea la excelente idea de contar con nodos "gratuitos" en la web para procesar dataset solo con contar con el navegador de un usuario, simplemente al colocar el URL de un sitio!
Funcionaría de la siguiente manera:
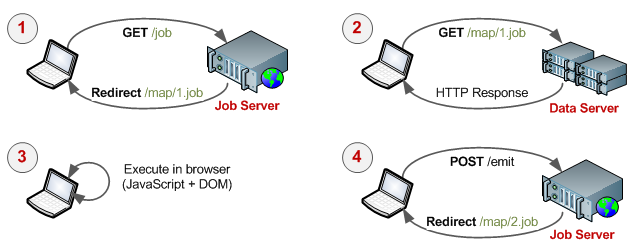
El proceso consiste en cuatro pasos:
- El Cliente se une al cluster al hacer un requerimiento al Servidor de Trabajos (server-job, que controla el proceso del trabajo).
- El trabajo es asignado al cliente, el cual consiste en un URL (Servidor de Datos) que contiene el dato a procesar y las funciones de map/reduce.
- El trabajo es procesado en el cliente.
- Una vez terminado el trabajo, el cliente envía el resultado al servidor.
Y que tiene de bueno?
Pues, conseguir nodos que procesen trabajos de map-reduce es costo (financieramente y proceso), por lo que, al proponer un modelo como este, permitirá plantear soluciones livianas y menos costosas.
En Collaborative map-reduce esboza el código para el cliente y el servidor, para un proceso simple de contar palabras.