
El procesamiento de los datos históricos de «un sensor» en una ubicación se realiza con Python desde el archivo generado en la sección anterior. Esta forma se obtiene un archivo nuevo y de menor tamaño para procesar con los datos de solo el dispositivo que se propone analizar.
El formato de la tabla es el mismo que el observado en «DB Browser».
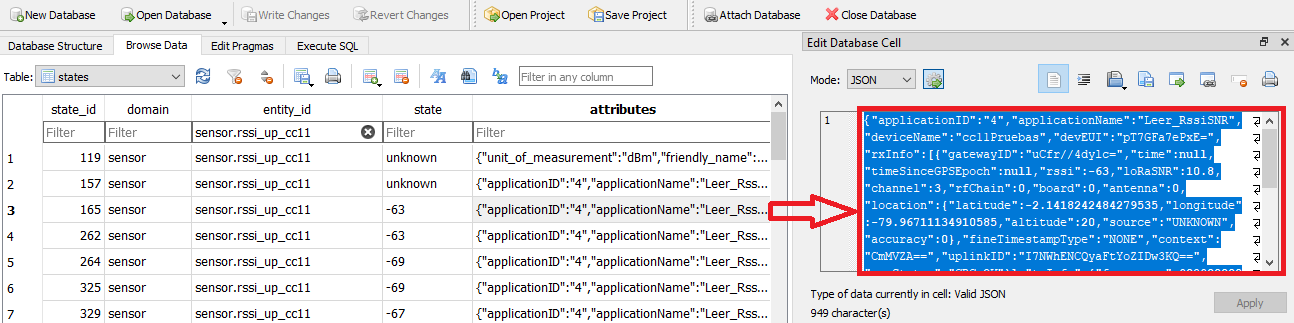
Los campos a usar son principalmente:
- «entity_id» para la selección de un sensor,
- «attributes» donde previamente se configuró para guardar el mensaje mqtt de cada transmisión
- «created» que contine la fecha y hora de creación del registro. referenciada a GMT=0.
Parametros guardados en attributes
El campo «attributes» de cada registro contiene varios parámetros posibles a usar en el formato del mensaje. Un ejemplo del contenido se indica en el recuadro en rojo mostrado en lala figura anterior, y se presenta a continuación.
{"applicationID":"4",
"applicationName":"Leer_RssiSNR",
"deviceName":"cc11Pruebas",
"devEUI":"pT7GFa7ePxE=",
"rxInfo":[{"gatewayID":"uCfr//4dylc=",
"time":null,"timeSinceGPSEpoch":null,
"rssi":-63,
"loRaSNR":10.8,
"channel":3,
"rfChain":0,
"board":0,
"antenna":0,
"location":{"latitude":-2.1418242484279535,
"longitude":-79.96711134910585,
"altitude":20,
"source":"UNKNOWN",
"accuracy":0},
"fineTimestampType":"NONE",
"context":"CmMVZA==",
"uplinkID":"I7NWhENCQyaFtYoZIDw3KQ==",
"crcStatus":"CRC_OK"}],
"txInfo":{"frequency":902900000,
"modulation":"LORA",
"loRaModulationInfo":{"bandwidth":125,
"spreadingFactor":10,
"codeRate":"4/5",
"polarizationInversion":false}
},
"adr":true,
"dr":0,
"fCnt":778,
"fPort":4,
"data":"KwcK9A8=",
"objectJSON":"{\"Down_datarate\":10,\"Down_rssi\":-43,\"Down_snr\":7,\"bateria_V\":4.08}",
"tags":{},
"confirmedUplink":true,
"devAddr":"AVqCdA==",
"publishedAt":"2021-10-21T16:28:36.265518462Z",
"unit_of_measurement":"dBm",
"friendly_name":"rssi_up_cc11"
}
El formato del ejemplo mostrado se realizó con el editor de Python para facilidad de lectura,
Procesamiento de datos para un sensor
El procesamiento de cada registro se realiza separando los campos a usar, en una tabla los campos representan las columnas a usar.
La selección del dispositivos se realiza comparando con «entity_id«.
El intervalo de fechas permite usar ventanas de tiempo de observación. La fecha y hora registrada se encuentra referenciadas a GMT=0, dado que en el pais donde se realizan las muestras usa GMT=-5, se realiza un desplazamiento en las horas para facilitar la identificación de las franjas horarias.
Los identificadores de gateways se simplifican con el diccionario gateway, que deben ser previamente identificados buscando en el archivo.json como «gatewayID». También se revisa el número de trama (fCnt) para registrar las recepción de tramas repetidas en cada gateway, registrando los valores en una lista, para posteriormente, seleccionar el valor mayor, menor, promedio).
Los parámetros de recepción en el gateway se encuentran en «rx_datos» en el siguiente orden: rssi, loRaSNR, channel, rfChain, frequency
El resultado de la selección de los datos se guarda en un nuevo archivo en formato.csv para facilitar la lectura de los datos con otros programas.
Otra forma de guardar los datos en en formato.json, que puede ser leida con la librería Pandas.
Instrucciones en Python para tabla CSV
# Lectura de archivo.json hacia una tabla0 # selecciona registros de "un sensor" # graba unreporte.csv con pandas # http://blog.espol.edu.ec/girni/ import numpy as np import json import pandas as pd import datetime as dt import os # INGRESO # archivo de entrada unarchivoDB = "states20211022.json" carpeta_DB = "BaseDatosJSON" # fecha intervalo fechainicio = "2021-10-21 11:00:00.0" fechafin = "2021-10-22 11:50:00.0" zonaGMT = -5 unsensor = "sensor.rssi_up_cc12" modelo_disp = "modulo" # capsula, modulo desarrollo ubicado = "LOS22" carpeta_rsm = "resultado_Test" # gatewayID simplifica identificador gatewayDB = {'uCfr//4dylc=':'Gw03'} # PROCEDIMIENTO ----- campos = ['domain','entity_id','state','attributes','created'] # Lectura de archivo json, cambia a formato DataFrame tabla0 = pd.DataFrame() archivo_ruta = carpeta_DB + '/' + unarchivoDB archivoexiste = os.path.exists(archivo_ruta) if archivoexiste: tabla0 = pd.read_json(archivo_ruta) tabla0 = pd.DataFrame(tabla0,columns=campos) else: print(' ERROR: NO se encuentra el archivo...') print(' revise el nombre de archivo. ') # Revisa cada registro leidos = 0 tabla = {} if archivoexiste: # Intervalo de fecha como datetime hora_desplaza = dt.timedelta(hours = abs(zonaGMT)) fechaformatoDB = '%Y-%m-%dT%H:%M:%S.%f' fechaformato = '%Y-%m-%d %H:%M:%S.%f' fechatxt = fechainicio[0:np.min([26,len(fechainicio)])] fechainicio = dt.datetime.strptime(fechatxt,fechaformato) fechatxt = fechafin[0:np.min([26,len(fechafin)])] fechafin = dt.datetime.strptime(fechatxt,fechaformato) # datos de trama for cadaregistro in tabla0.index: unatrama = tabla0['attributes'][cadaregistro] trama_mqtt = json.loads(unatrama) # selecciona registro por sensor, en fecha y con datos cualsensor = (tabla0['entity_id'][cadaregistro] == unsensor) unafecha = tabla0['created'][cadaregistro] unafecha = unafecha[0:np.min([26,len(unafecha)])] unafecha = dt.datetime.strptime(unafecha,fechaformato) unafecha = unafecha - hora_desplaza enfecha = (unafecha>=fechainicio) and (unafecha<=fechafin) condatos = 'applicationID' in trama_mqtt.keys() selecciona = cualsensor and condatos and enfecha if (selecciona == True): # datos en la mensaje MQTT publishedAt = trama_mqtt["publishedAt"] publishedAt = publishedAt[0:np.min([26,len(publishedAt)])] publishedAt = dt.datetime.strptime(publishedAt,fechaformatoDB) publishedAt = publishedAt - hora_desplaza friendly_name = trama_mqtt["friendly_name"] deviceName = trama_mqtt["deviceName"] dispositivo = friendly_name.split('_')[2] dr = trama_mqtt["dr"] fCnt = trama_mqtt["fCnt"] fPort = trama_mqtt["fPort"] freq_tx = trama_mqtt["txInfo"]["frequency"] bandwidth = trama_mqtt["txInfo"]["loRaModulationInfo"]["bandwidth"] spreadingFactor = trama_mqtt["txInfo"]["loRaModulationInfo"]["spreadingFactor"] objectJSON = trama_mqtt["objectJSON"] datosensor = json.loads(objectJSON) datostrama = {"publishedAt": publishedAt, "dispositivo": dispositivo, "fCnt": fCnt} # revisa gateway en la red LoRaWan tamano = len(trama_mqtt["rxInfo"]) i = 0 while i<tamano: gatewayID = trama_mqtt["rxInfo"][i]["gatewayID"] rssi = trama_mqtt["rxInfo"][i]["rssi"] loRaSNR = trama_mqtt["rxInfo"][i]["loRaSNR"] channel = trama_mqtt["rxInfo"][i]["channel"] rfChain = trama_mqtt["rxInfo"][i]["rfChain"] gtwNum = gatewayDB[gatewayID] # registra en tabla, incluyendo tramas repetidas datostrama['rssi_up'] = rssi datostrama['snr_up'] = loRaSNR datostrama['channel_up'] = channel datostrama['rfChain_up'] = rfChain datostrama['gtw_rx'] = gtwNum i = i + 1 # dato del sensor equivale = {'Down_datarate': 'dr_down', 'Down_rssi' : 'rssi_down', 'Down_snr' : 'snr_down', 'bateria_V' : 'bateria_V'} for undato in datosensor: if undato in equivale.keys(): datostrama[equivale[undato]] = datosensor[undato] else: datostrama[undato] = datosensor[undato] # datos, otros valores datostrama["frequency"] = freq_tx datostrama["bandwidth"] = bandwidth datostrama["spreadingFactor"] = spreadingFactor datostrama["fPort"] = fPort datostrama["dr"] = dr datostrama["created"] = unafecha leidos = leidos + 1 # revisa registro repetido repetido = False if leidos>1: trama_num = (fCnt == tabla[leidos-1]['fCnt']) fecha_pub = (publishedAt == tabla[leidos-1]['publishedAt']) gtwNum_rep = (gtwNum == tabla[leidos-1]['gtw_rx']) repetido = (trama_num and fecha_pub and gtwNum_rep) if not(repetido): tabla[leidos] = datostrama else: leidos = leidos - 1 # convierte diccionario a DataFrame if len(tabla)>0: tabla = pd.DataFrame(tabla) tabla = tabla.T # añade ubicación y modelo (capsula o modulo desarrollo) tabla.insert(1,'ubicado',ubicado) tabla.insert(2,'modelo_disp',modelo_disp) # directorio de resultados if len(carpeta_rsm) > 0: if not(os.path.exists(carpeta_rsm)): os.makedirs(carpeta_rsm) carpeta_rsm = carpeta_rsm + '/' # SALIDA print('registros leidos: ', len(tabla0)) print('registros procesados: ', leidos) print(tabla) # guarda el reporte en csv if len(tabla)>0: unreporte = carpeta_rsm+'data_'+ubicado+'.csv' tabla.to_csv(unreporte)
el resultado de puede visualiza como:
registros leidos: 7090
registros procesados: 98
publishedAt ubicado modelo_disp dispositivo ... spreadingFactor fPort dr created
1 2021-10-21 11:34:07.079188 LOS22 modulo cc12 ... 10 4 0 2021-10-21 11:34:07.105036
2 2021-10-21 11:49:07.862255 LOS22 modulo cc12 ... 10 4 0 2021-10-21 11:49:07.876219
3 2021-10-21 12:04:07.931128 LOS22 modulo cc12 ... 10 4 0 2021-10-21 12:04:07.943781
4 2021-10-21 12:19:08.489097 LOS22 modulo cc12 ... 10 4 0 2021-10-21 12:19:08.504848
5 2021-10-21 12:34:08.479274 LOS22 modulo cc12 ... 10 4 0 2021-10-21 12:34:08.494229
.. ... ... ... ... ... ... ... .. ...
94 2021-10-22 10:49:46.742877 LOS22 modulo cc12 ... 10 4 0 2021-10-22 10:49:46.756601
95 2021-10-22 11:04:47.636628 LOS22 modulo cc12 ... 10 4 0 2021-10-22 11:04:47.652299
96 2021-10-22 11:19:48.310535 LOS22 modulo cc12 ... 10 4 0 2021-10-22 11:19:48.331143
97 2021-10-22 11:34:49.209626 LOS22 modulo cc12 ... 10 4 0 2021-10-22 11:34:49.224717
98 2021-10-22 11:49:49.638194 LOS22 modulo cc12 ... 10 4 0 2021-10-22 11:49:49.651398
[98 rows x 20 columns]
>>>
y el archivo resultante se presenta como:
Instrucciones en Python para tabla JSON
# Lectura de archivo.json hacia una tabla1 # selecciona registros de "un sensor" # graba unreporte.json con pandas import numpy as np import json import pandas as pd import datetime as dt # INGRESO # archivo de entrada unarchivo = 'states20211022.json' fechainicio = '2021-10-21 19:00:00.0' fechafin = '2021-10-22 17:10:00.0' unsensor = 'sensor.rssi_up_cc22' # archivo de salida unreporte = 'tramas20211022_cc12.json' # PROCEDIMIENTO ----- # columnas o campos a usar campos = ['domain','entity_id','state', 'attributes','created'] # gatewayID simplifica identificador gateway = {'uCfr//5zvhk=':'Gw01', 'uCfr//4dylc=':'Gw03'} # Lectura de archivo json tabla0 = pd.read_json(unarchivo) # Cambia a formato DataFrame tabla0 = pd.DataFrame(tabla0,columns=campos) # Revisa cada registro leidos = 0 tabla = {} # Intervalo de fecha como datetime formato = '%Y-%m-%d %H:%M:%S.%f' fechainicio = fechainicio[0:np.min([26,len(fechainicio)])] fechainicio = dt.datetime.strptime(fechainicio,formato) fechafin = fechafin[0:np.min([26,len(fechafin)])] fechafin = dt.datetime.strptime(fechafin,formato) # datos de trama for cadaregistro in tabla0.index: unatrama = tabla0['attributes'][cadaregistro] trama_mqtt = json.loads(unatrama) # selecciona registro por sensor, en fecha y con datos cualsensor = (tabla0['entity_id'][cadaregistro] == unsensor) unafecha = tabla0['created'][cadaregistro] unafecha = unafecha[0:np.min([26,len(unafecha)])] unafecha = dt.datetime.strptime(unafecha,formato) enfecha = (unafecha>=fechainicio) and (unafecha<=fechafin) condatos = 'applicationID' in trama_mqtt.keys() selecciona = cualsensor and condatos and enfecha if (selecciona == True): leidos = leidos + 1 # datos en la mensaje MQTT publishedAt = trama_mqtt["publishedAt"] friendly_name = trama_mqtt["friendly_name"] deviceName = trama_mqtt["deviceName"] dr = trama_mqtt["dr"] fCnt = trama_mqtt["fCnt"] fPort = trama_mqtt["fPort"] objectJSON = trama_mqtt["objectJSON"] datosensor = json.loads(objectJSON) frequency = trama_mqtt["txInfo"]["frequency"] bandwidth = trama_mqtt["txInfo"]["loRaModulationInfo"]["bandwidth"] spreadingFactor = trama_mqtt["txInfo"]["loRaModulationInfo"]["spreadingFactor"] datostrama = {"publishedAt":publishedAt, "fPort":fPort, "dr": dr,"fCnt": fCnt, "frequency": frequency, "bandwidth": bandwidth, "spreadingFactor": spreadingFactor, "datosensor":datosensor} # revisa por cada gateway en la red LoRaWan tamano = len(trama_mqtt["rxInfo"]) i = 0 while i<tamano: gatewayID = trama_mqtt["rxInfo"][i]["gatewayID"] rssi = trama_mqtt["rxInfo"][i]["rssi"] loRaSNR = trama_mqtt["rxInfo"][i]["loRaSNR"] channel = trama_mqtt["rxInfo"][i]["channel"] rfChain = trama_mqtt["rxInfo"][i]["rfChain"] gtwNum = gateway[gatewayID] i = i+1 # registra en tabla, incluyendo tramas repetidas rx_datos = [rssi, loRaSNR, channel, rfChain,frequency/1e6] if not(gtwNum in datostrama.keys()): datostrama[gtwNum] = [rx_datos] else: if not(rx_datos in datostrama[gtwNum]): datostrama[gwNum].append(rx_datos) dispositivo = friendly_name.split('_')[2] # revisa registro repetido disp_existe = dispositivo in tabla if not(disp_existe): tabla[dispositivo] = {leidos:datostrama} else: trama_num = (fCnt == tabla[dispositivo][leidos-1]['fCnt']) fecha_pub = (publishedAt == tabla[dispositivo][leidos-1]['publishedAt']) repetido = (trama_num and fecha_pub) if not(repetido): tabla[dispositivo][leidos] = datostrama else: leidos = leidos - 1 # convierte diccionario en DataFrame tabla = pd.DataFrame(tabla) # SALIDA print('registros leidos: ',len(tabla0)) print('registros procesados: ', leidos) # guarda el reporte en json tabla.to_json(unreporte)
El procesamiento de los datos se puede realizar con librerias como Pandas.
En el procesamiento de registros, se descarta el registro de «join».
Una muestra del reporte es:
registros leidos: 7090
registros procesados: 98
>>> tabla.keys()
Index(['cc12'], dtype='object')
>>> tabla['cc12'].keys()
Int64Index([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34,
35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68,
69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85,
86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98],
dtype='int64')
>>> tabla['cc12'][2].keys()
dict_keys(['publishedAt', 'fPort', 'dr', 'fCnt',
'frequency', 'bandwidth', 'spreadingFactor', 'datosensor',
'Gw03'])
>>>
>>> tabla['cc12'][2]['datosensor'].keys()
dict_keys(['Down_datarate', 'Down_rssi', 'Down_snr',
'bateria_V'])
>>> tabla['cc12'][2]['Gw03']
[[-84, 8.5, 1, 0, 902.5]]
Esta forma se obtiene un nuevo y mas pequeño archivo para procesar con los datos de solo el dispositivo que se propone analizar.
Referencia: Archivos.json – Pandas en blog de Fundamentos de Programación