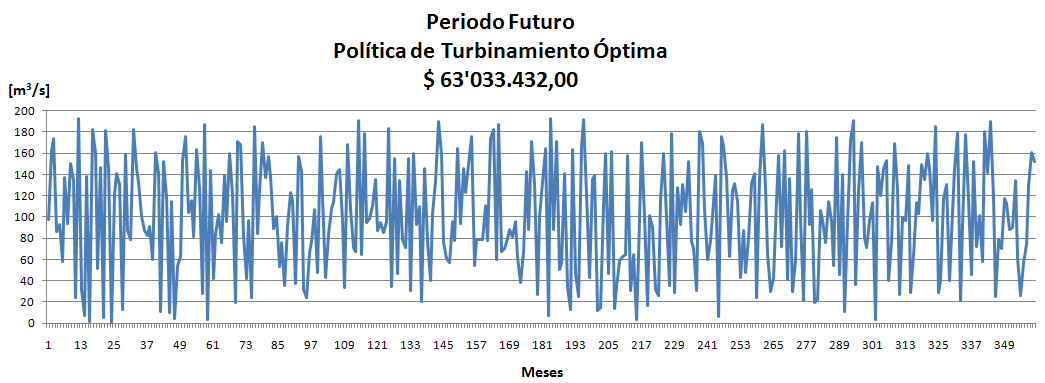
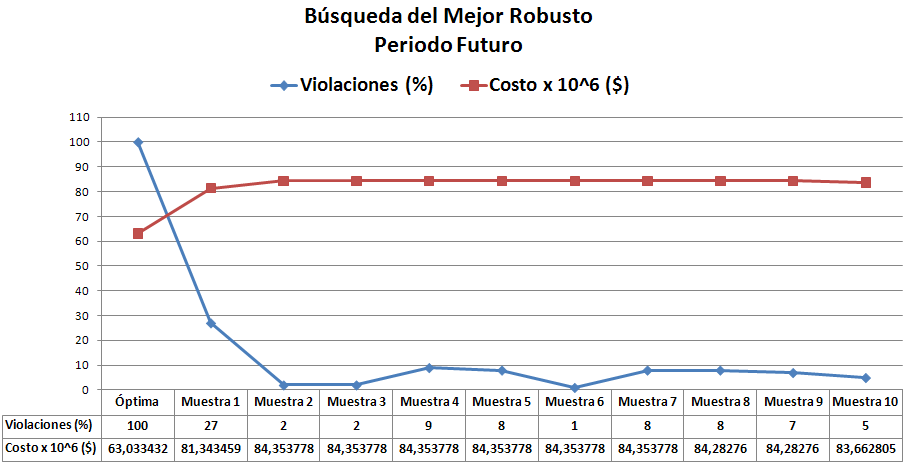
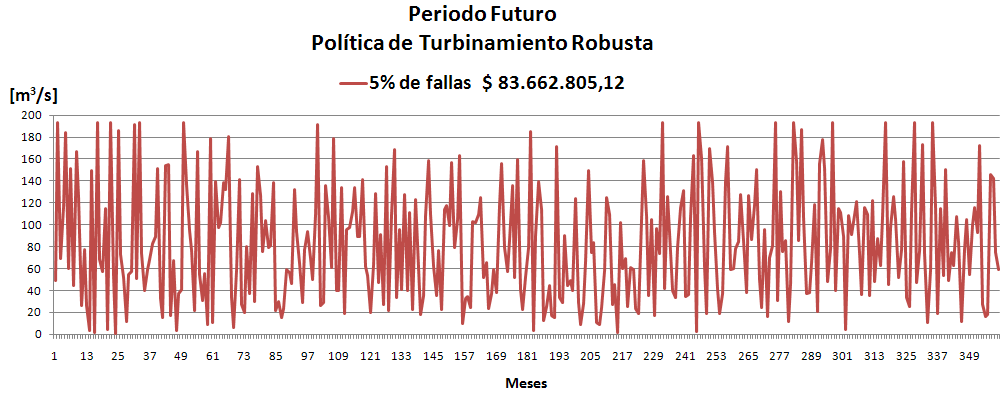
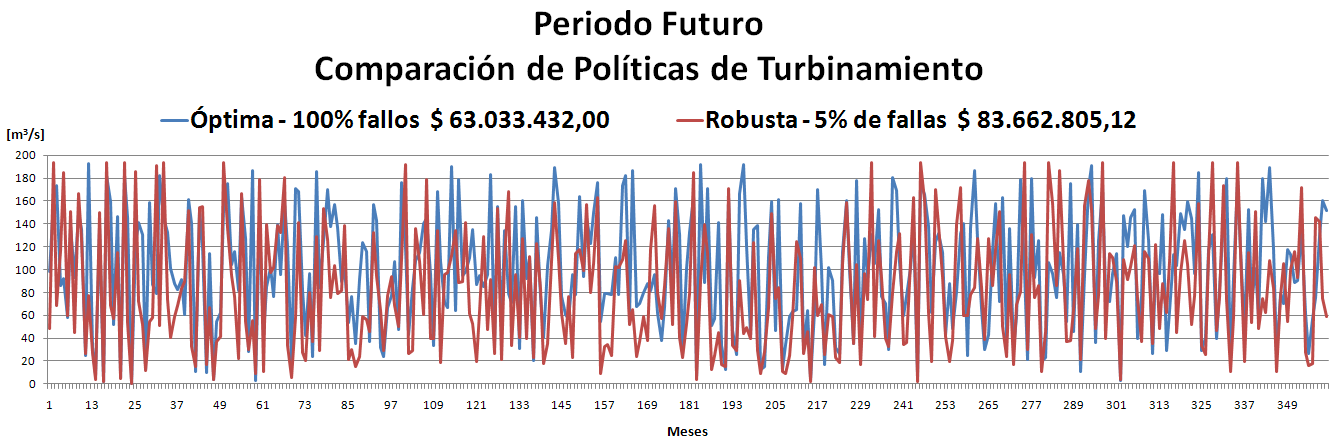
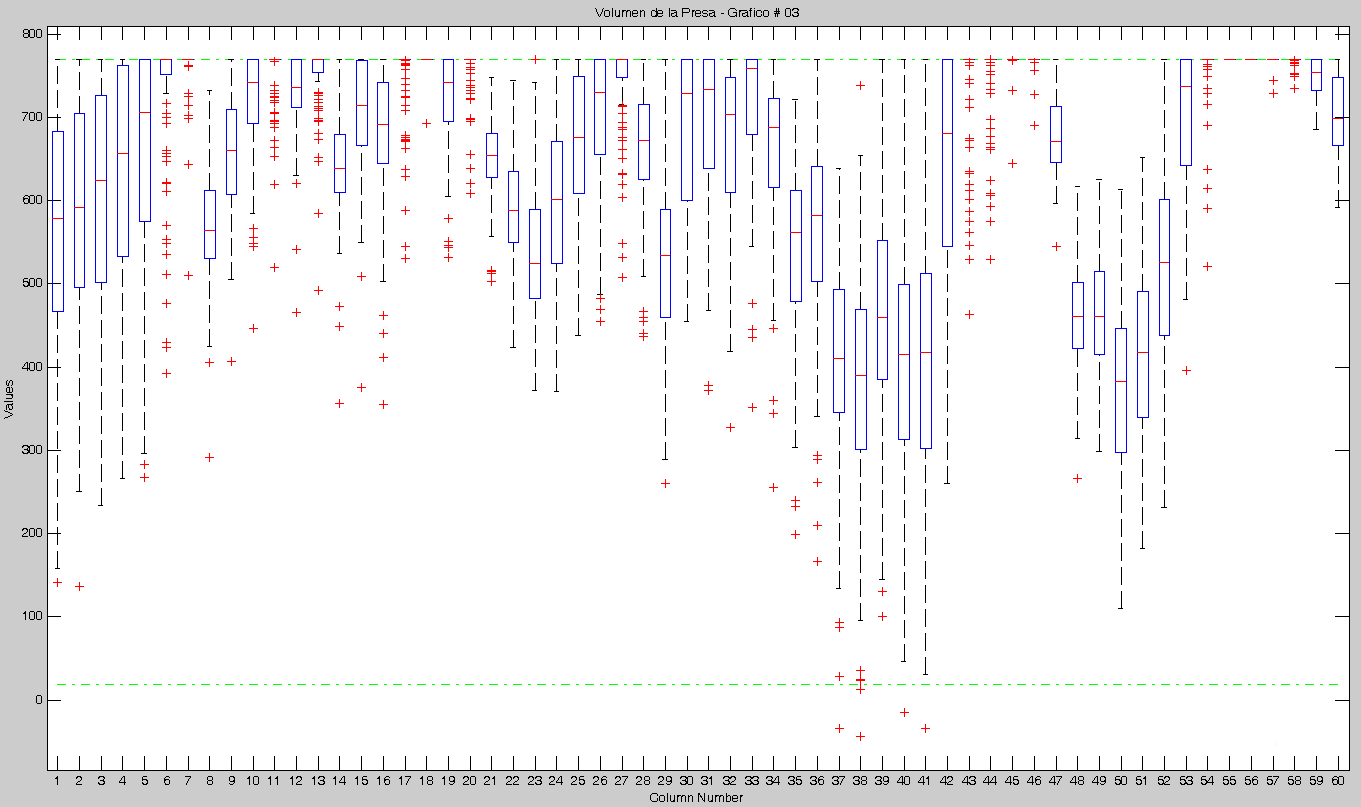
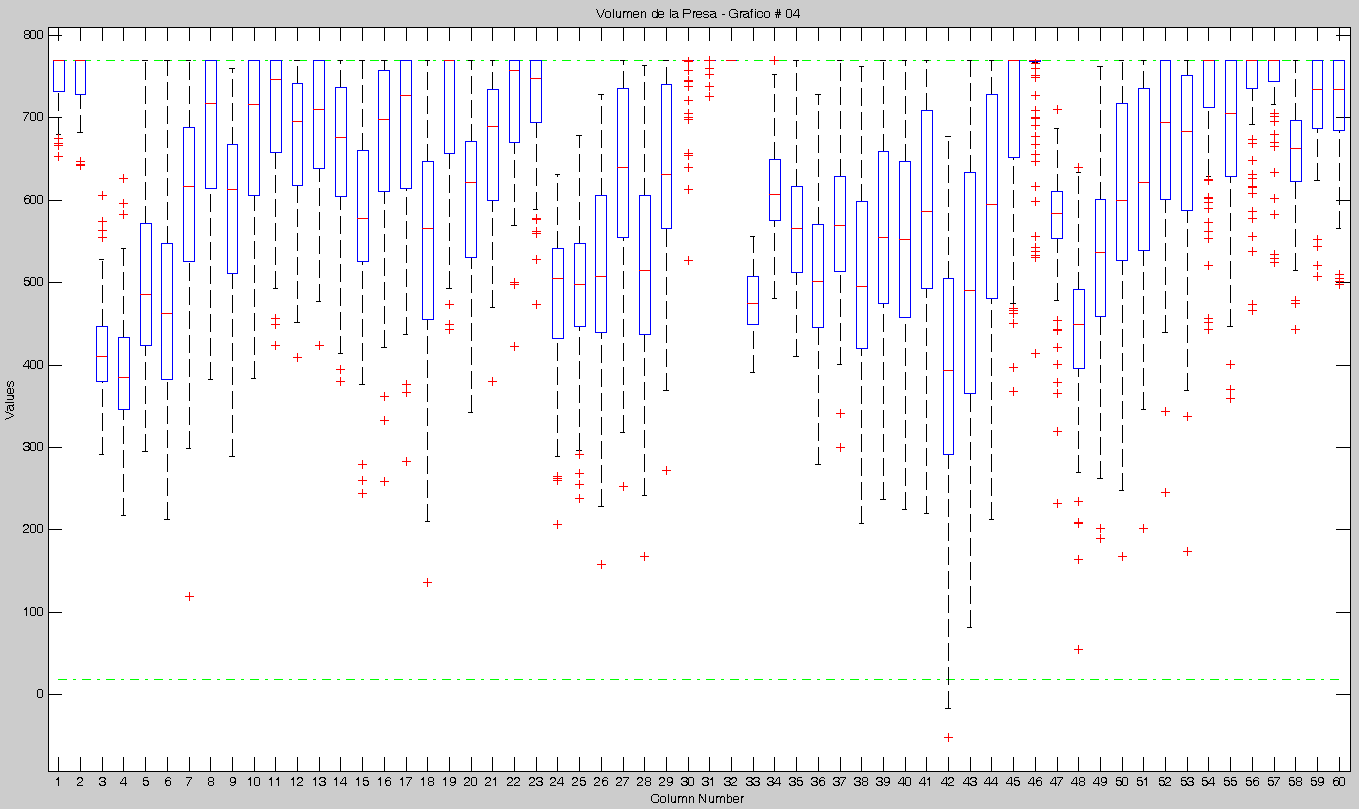
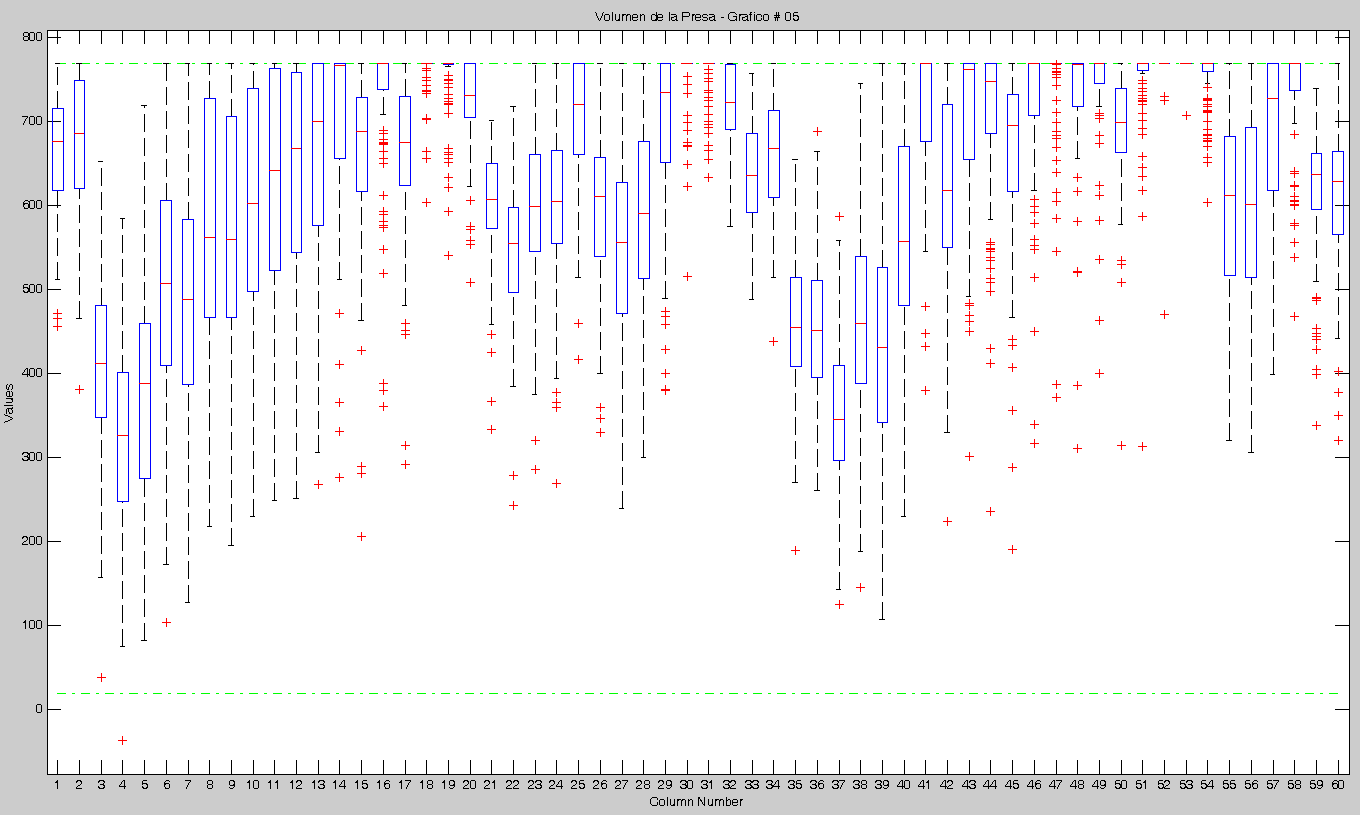
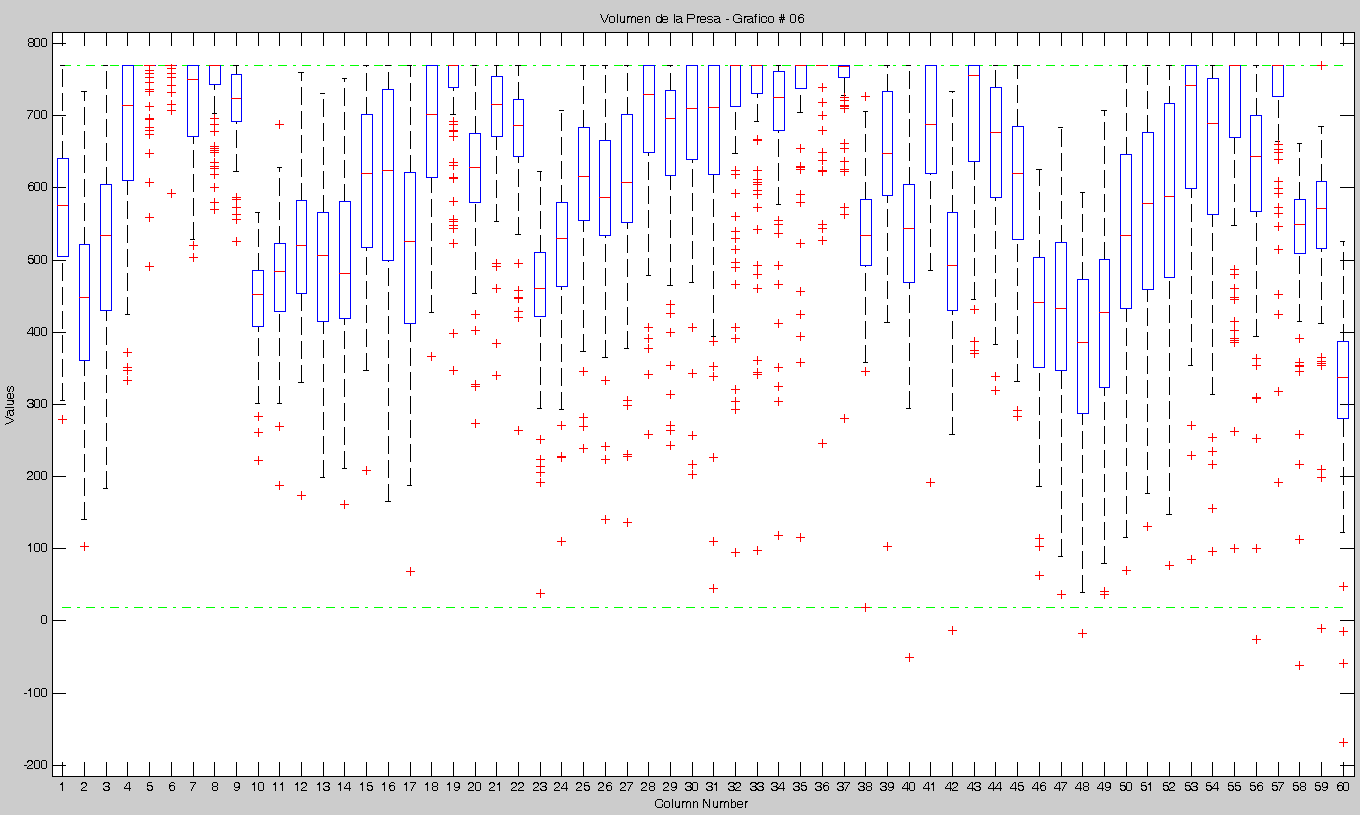
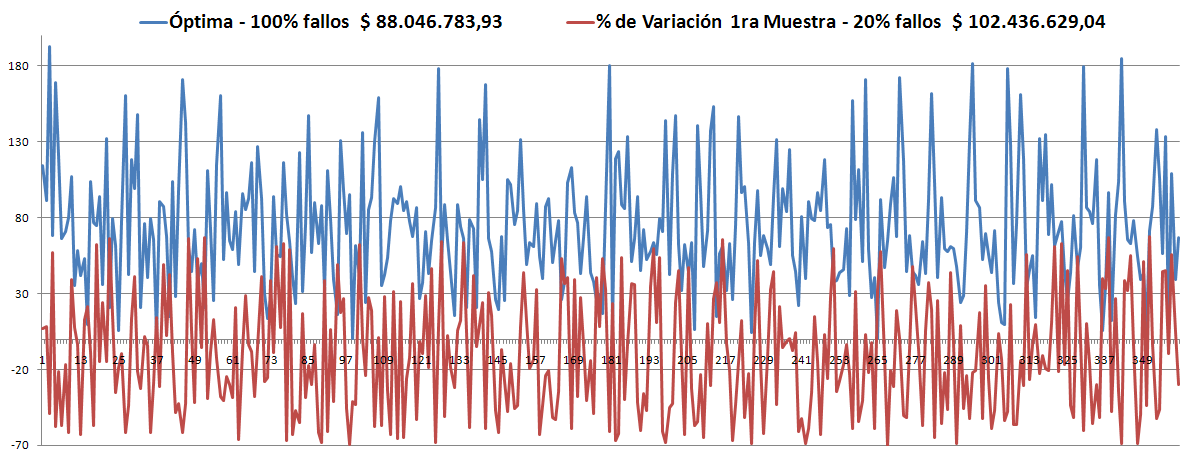
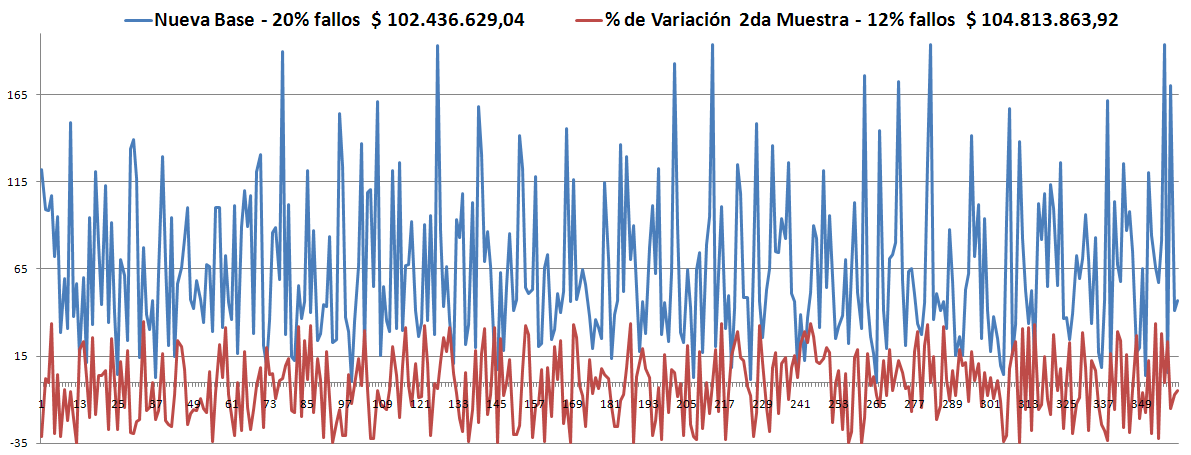
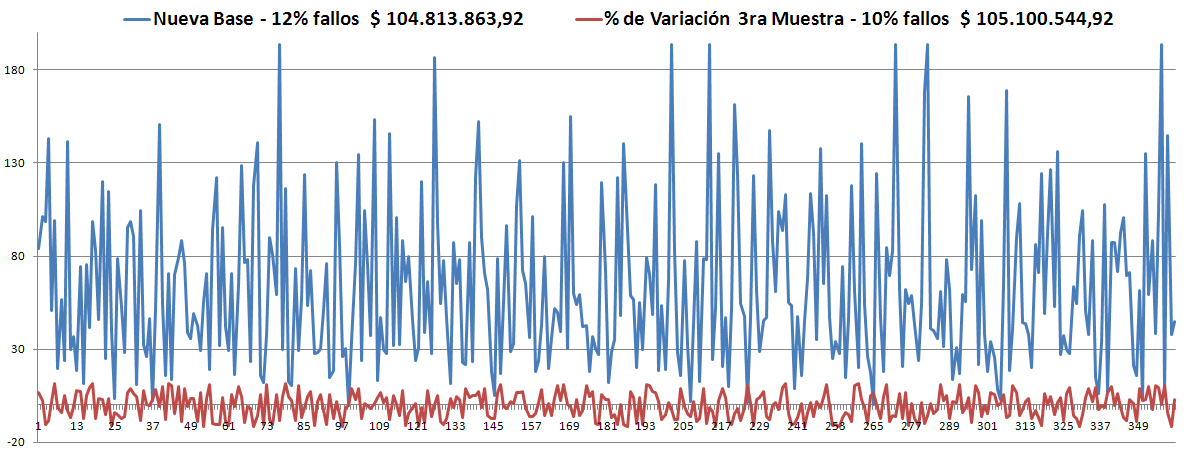
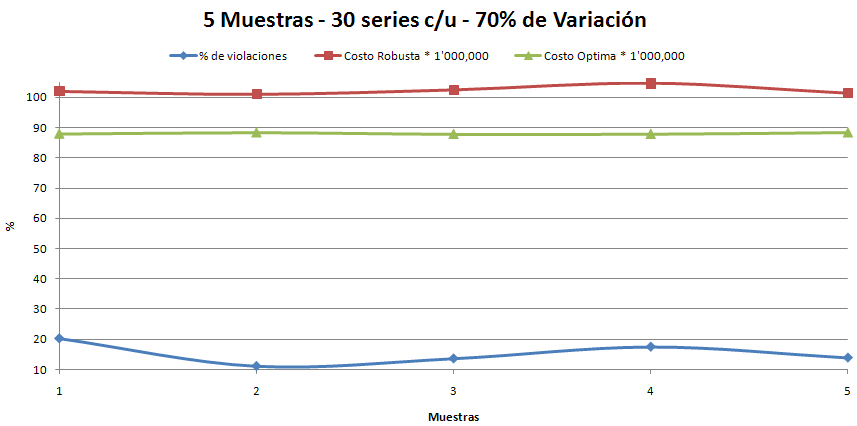
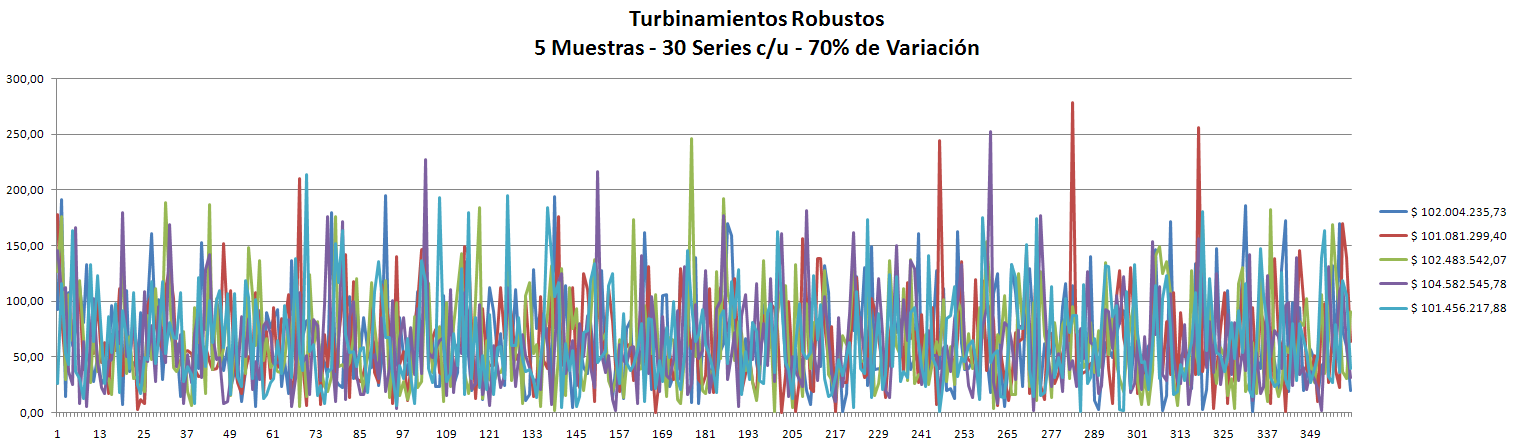
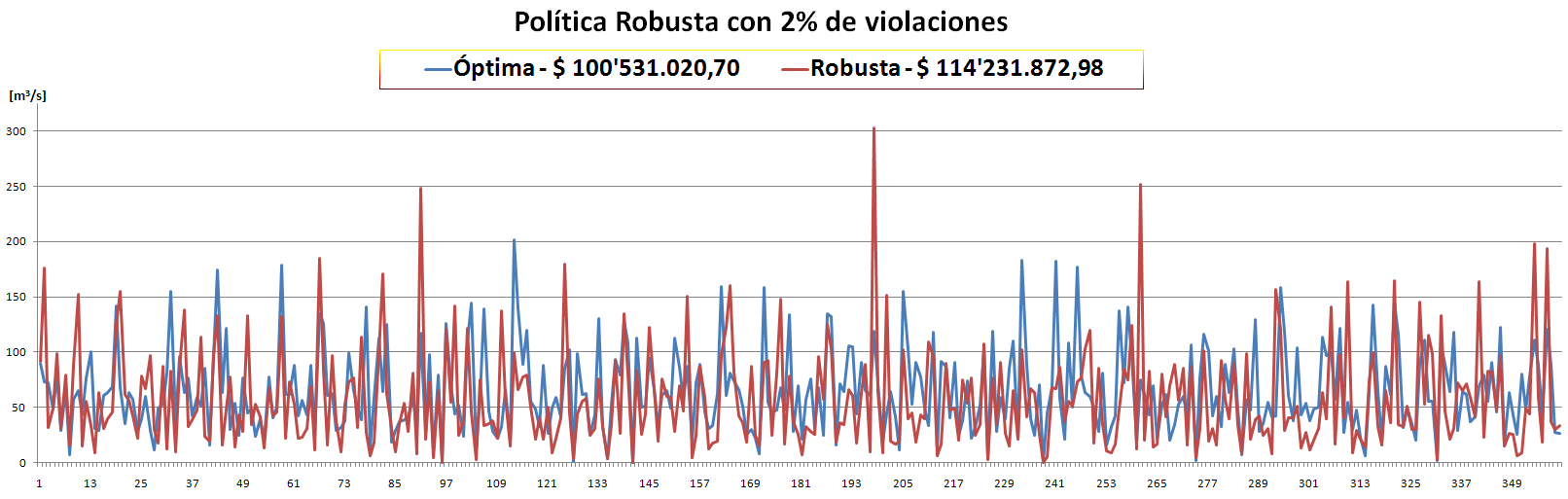
Observando los últimos dos resultados en cuanto al % de violaciones, se llegó a la conclusión de que existía un error recurrente. Este afectaba siempre a la primera Muestra y a cualquier otra que se iniciara con las mismas condiciones.
Al parecer el error era generado al momento de leer los archivos, porque el procedimiento es el siguiente:
- Hay 3 módulos: Generador aleatorio de las muestras; Generador de Política Optima usando la media de las muestras anteriores; y Buscador de Política Robusta usando la óptima y las muestras de caudales.
- El 3ro espera los resultados del 2do y el 2do espera los resultados del 1ro.
- En la primera iteración el 2do comenzaba a leer datos que todavía no eran completamente fijados en memoria y lo mismo hacía el 3ro.
Lo solucionamos utilizando la función Sleep mientras se esperaba para leer el archivo del módulo anterior.
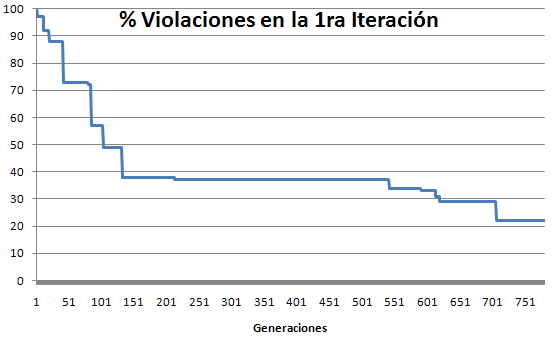
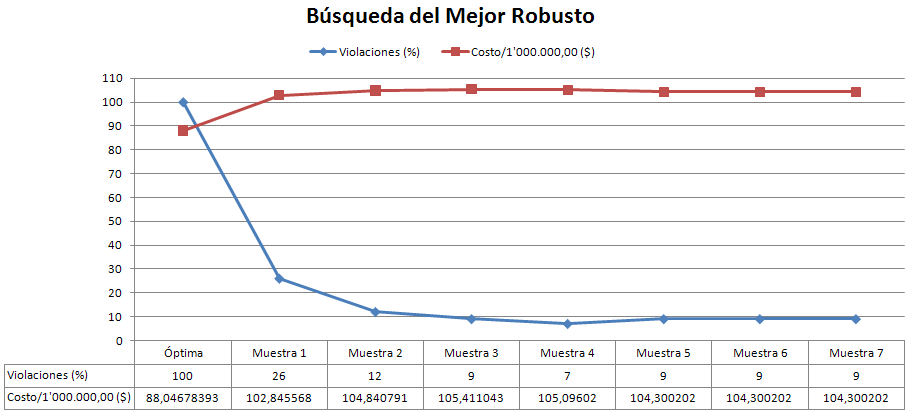
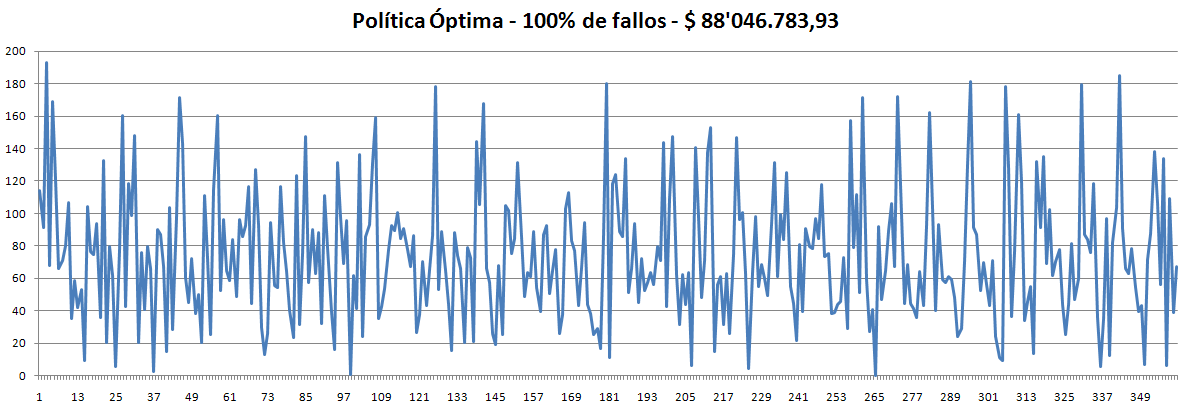
Realizamos una prueba con M=5 y N=100 y este fue el resultado.
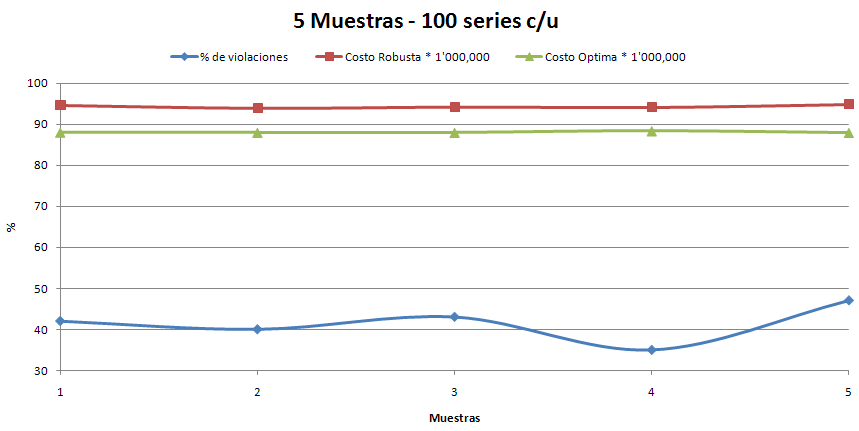
Como podemos notar, ya no tiene el error anterior, además los resultados son como los esperábamos (del 30 al 50% de violaciones).
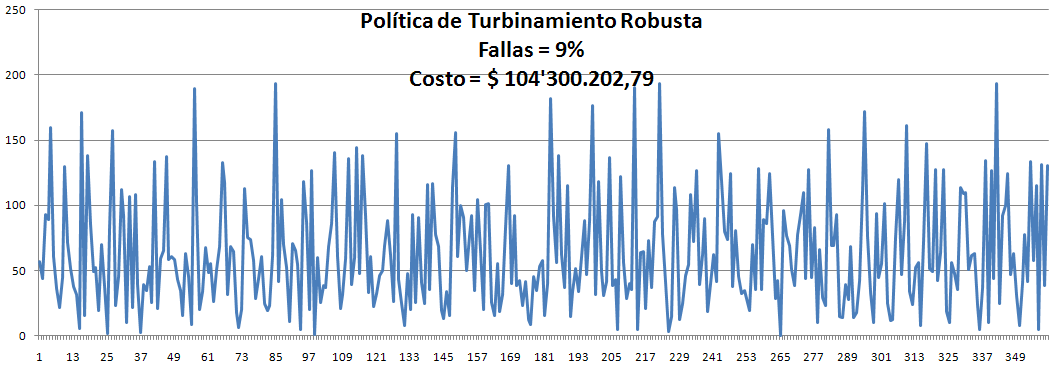
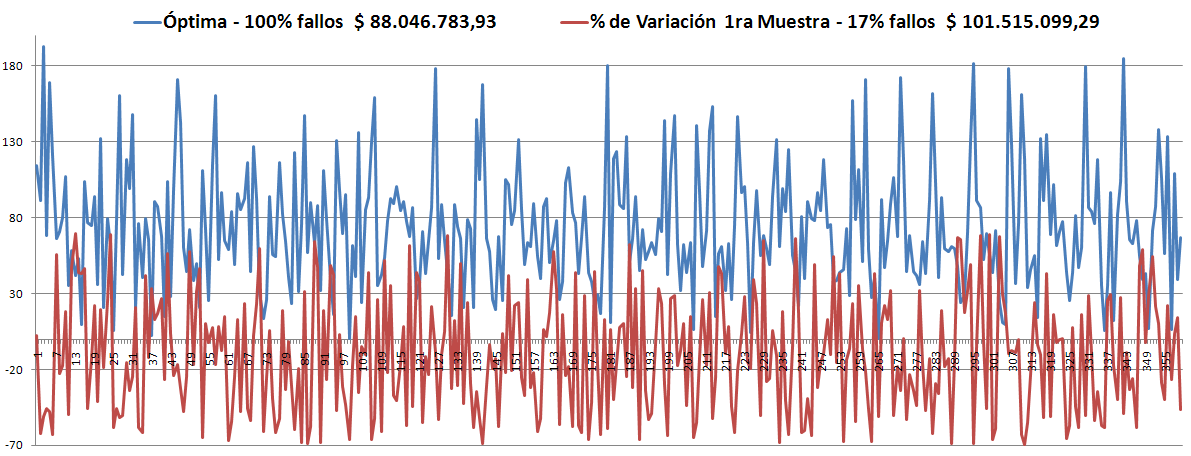
Con esto resuelto, procedimos a probar uno de las políticas cuasi robustas obtenidas (la 1ra, con 42% de violaciones)en Matlab, y como debería ser, dieron los mismos porcentajes de fallos en su muestra correspondiente.
Luego la probamos con todas las 10.000 series y obtuvimos 44% de violaciones, lo cual es muy satisfactorio porque quiere decir que con esta política satisfacemos el 56% de las 10.000 series de caudales. ¡Lo cual nos trae mucha tranquilidad y alegría!
Con esto en mente probamos la mejor de las 5 políticas encontradas (35 % de violaciones en su muestra) y nos dio 42% de violaciones en las 10.000 series, lo que representa 58% de satisfacción. Otro dato significativo es que 23 fue el número máximo de violaciones que provocó en las no pudo satisfacer y en general fueron menores de 10.
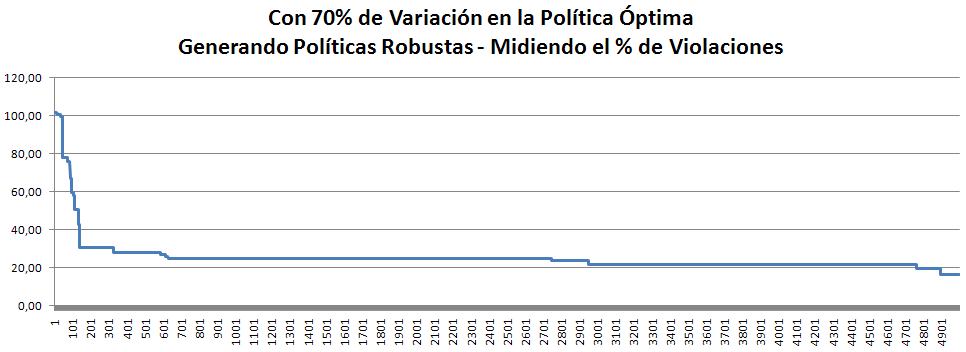
Y para hacer una última verificación, vamos a aumentar el % de variación del 30 al 50% y realizar una ejecución con M=5 y N=100, esto tomara aproximadamente 1h 20m.
Lo obtenido de esta ejecución es:
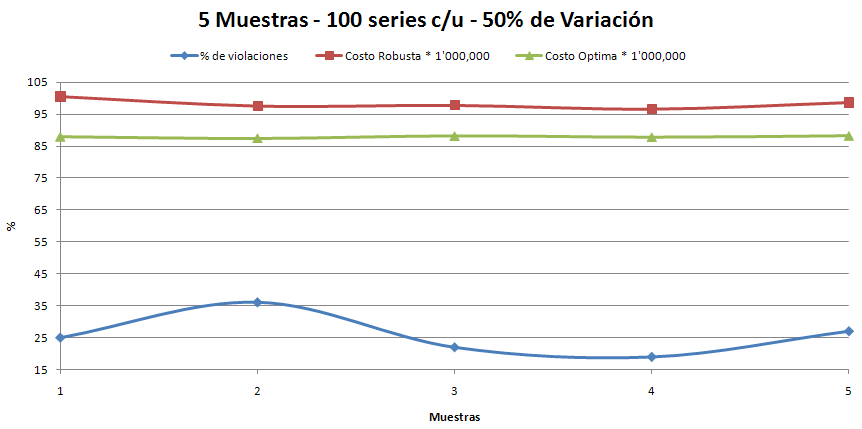
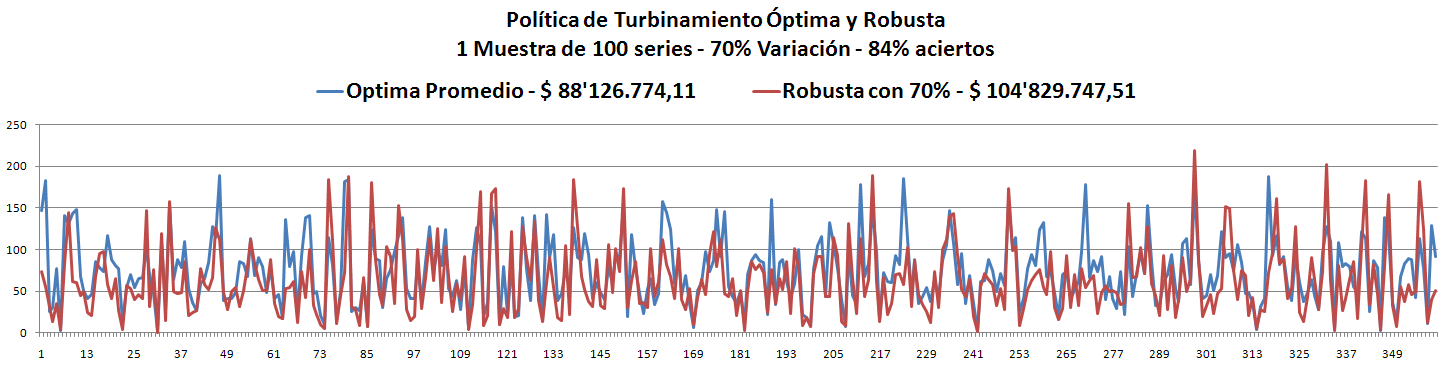
La mejor tuvo un 19% de violaciones y al probarla en la 10.000 muestras obtuvo 31% de violaciones, es decir, 69% de satisfacción y con 17 violaciones como máximo. Puede mejorar!
Lo siguiente en hacer es una variación en el módulo de búsqueda del robusto, la base actual para la búsqueda es la Política Óptima, lo que deseamos hacer ir almacenando la mejor Política Robusta y si esta es mejor que la Óptima de la Muestra actual, usarla como base para la búsqueda.
Bueno, los resultados obtenidos con este cambio no cambiaron casi nada, no porque no fuera efectivo si no que hay dos condiciones que considerar.
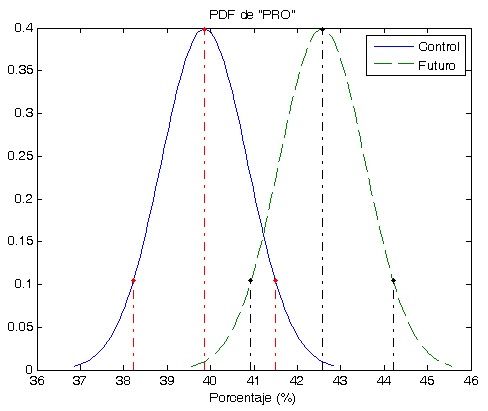
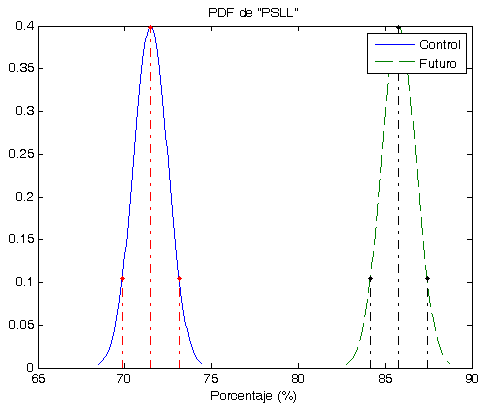
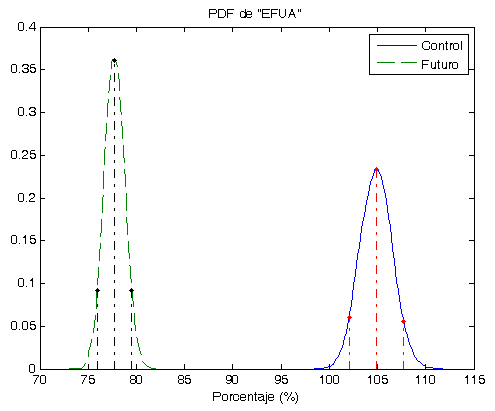
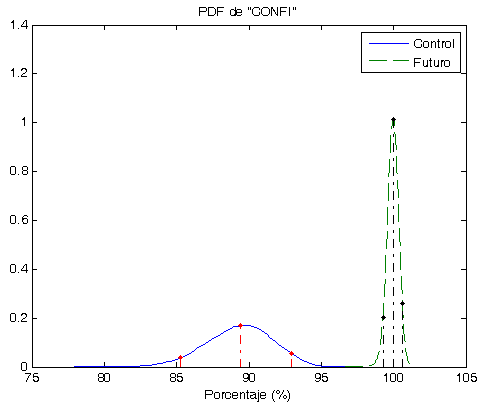
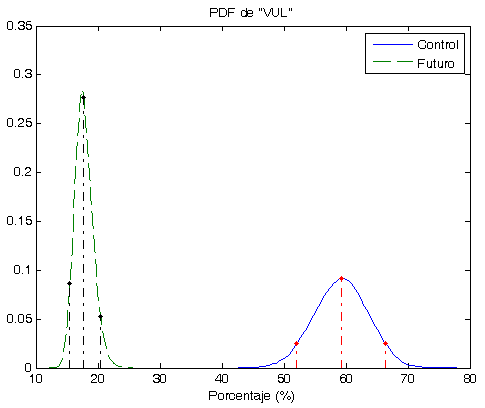
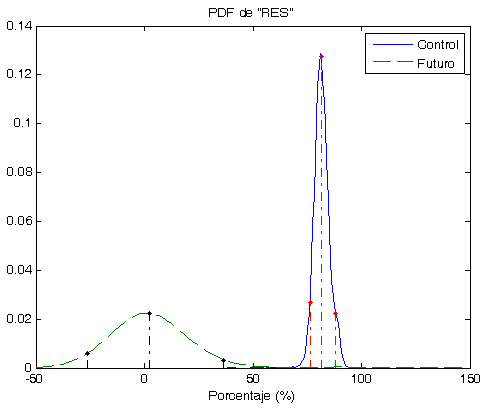
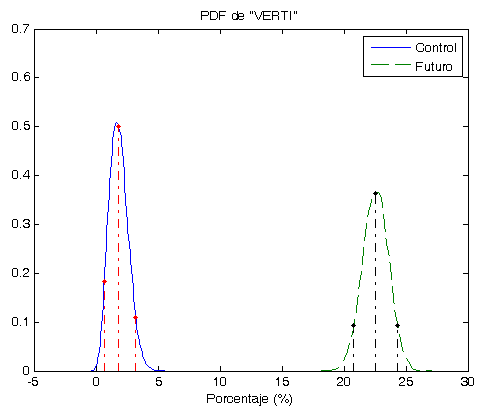
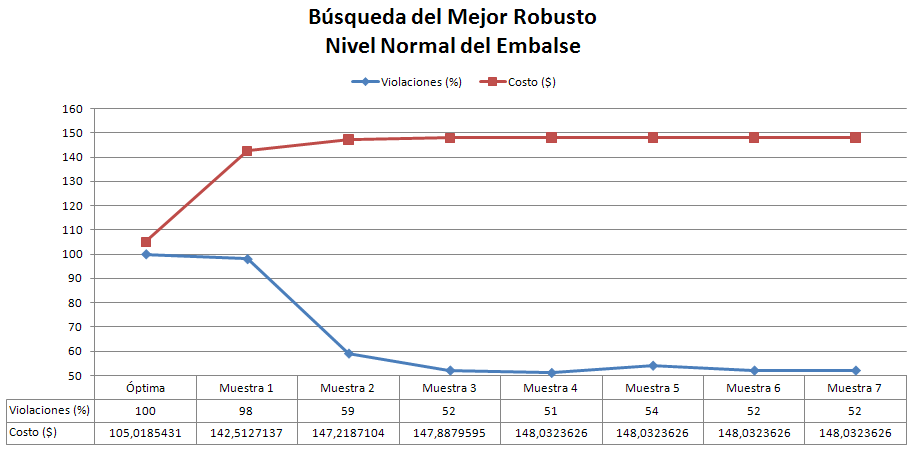
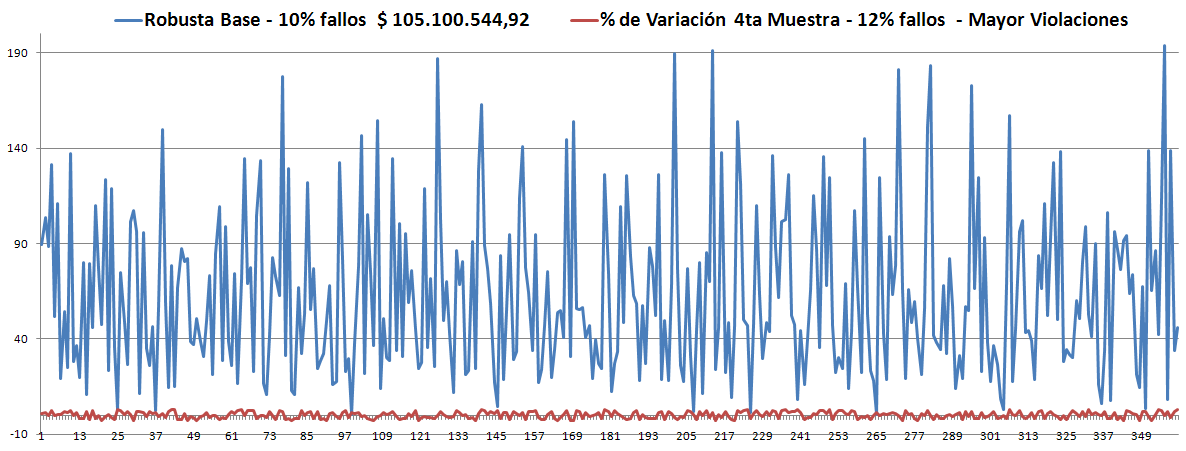
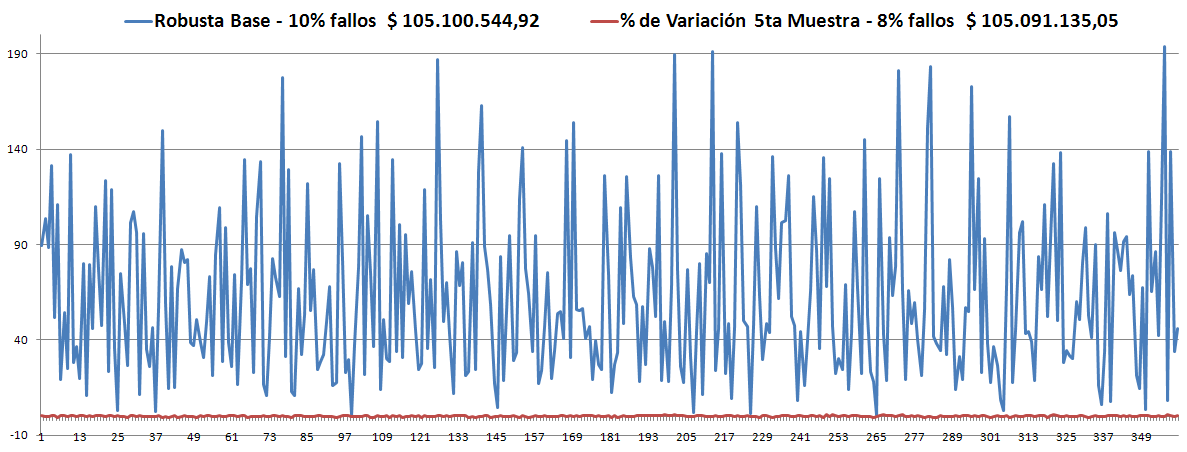
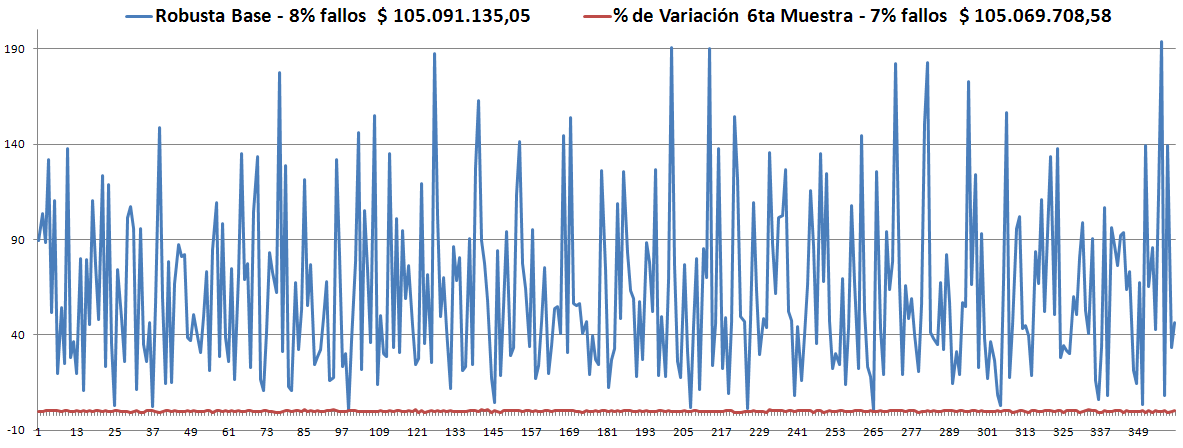
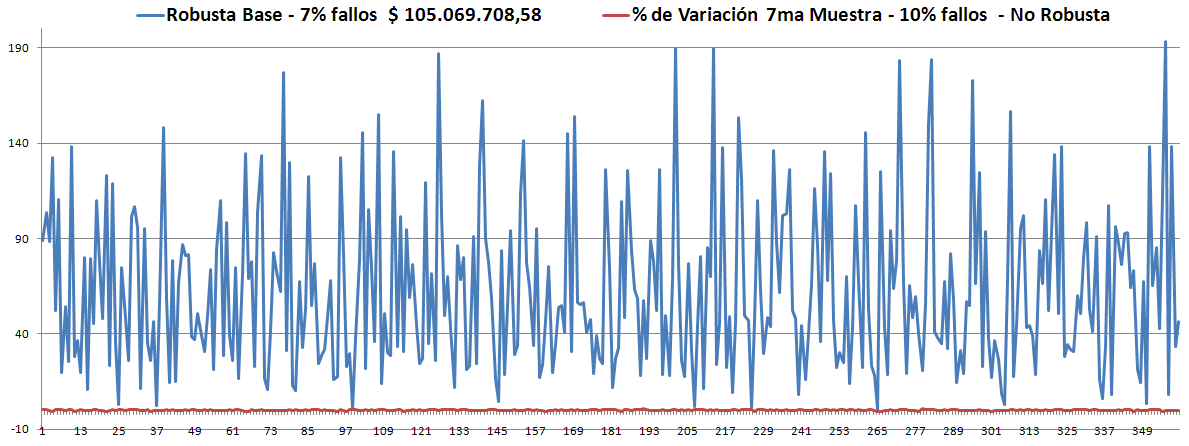
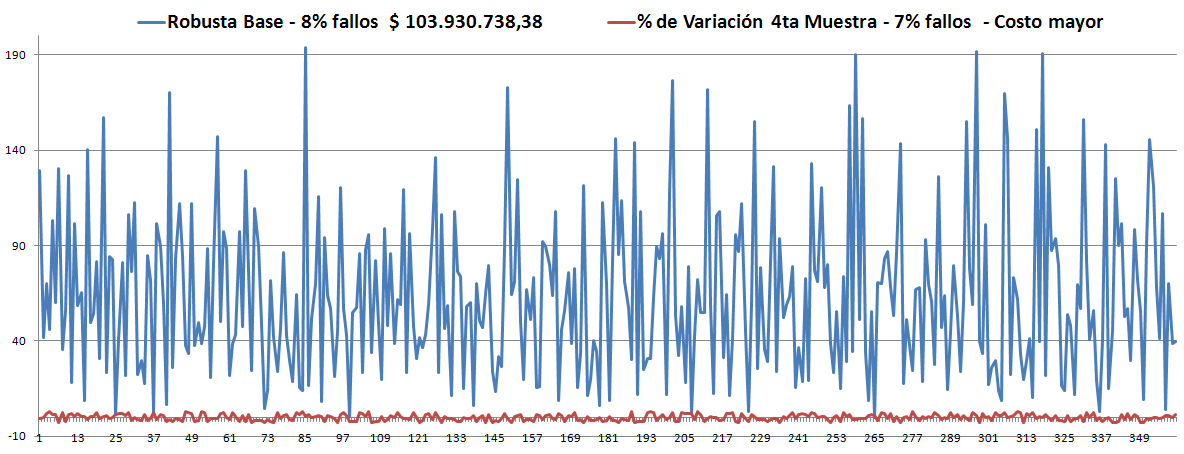
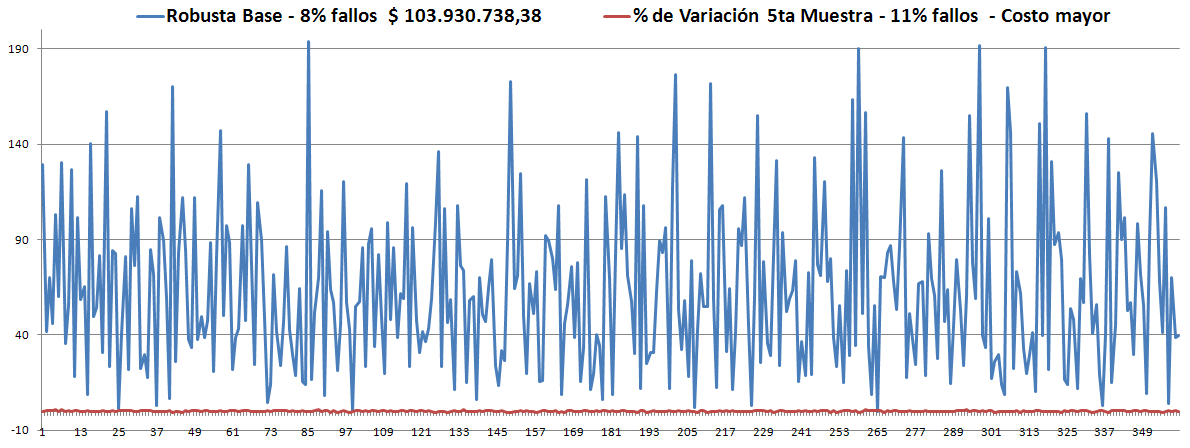
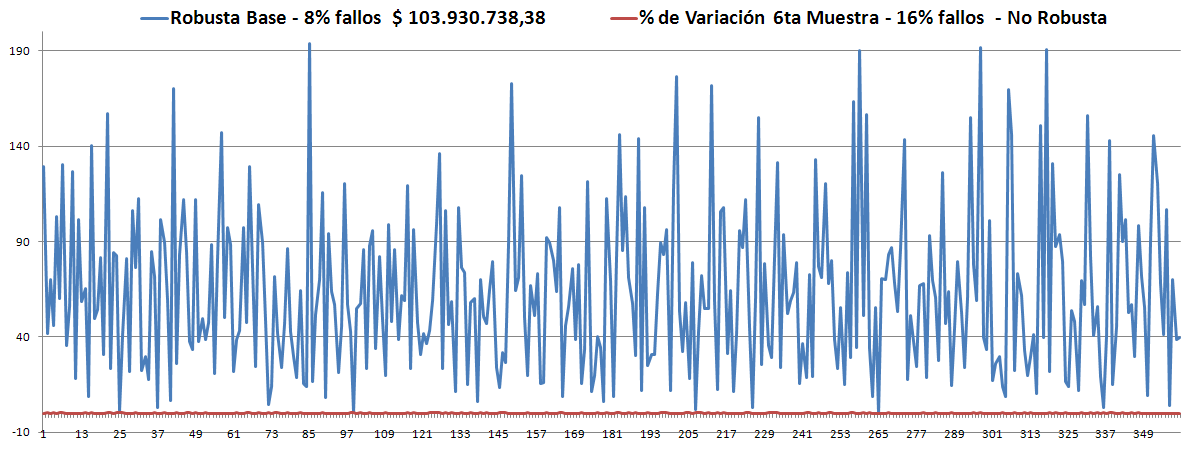
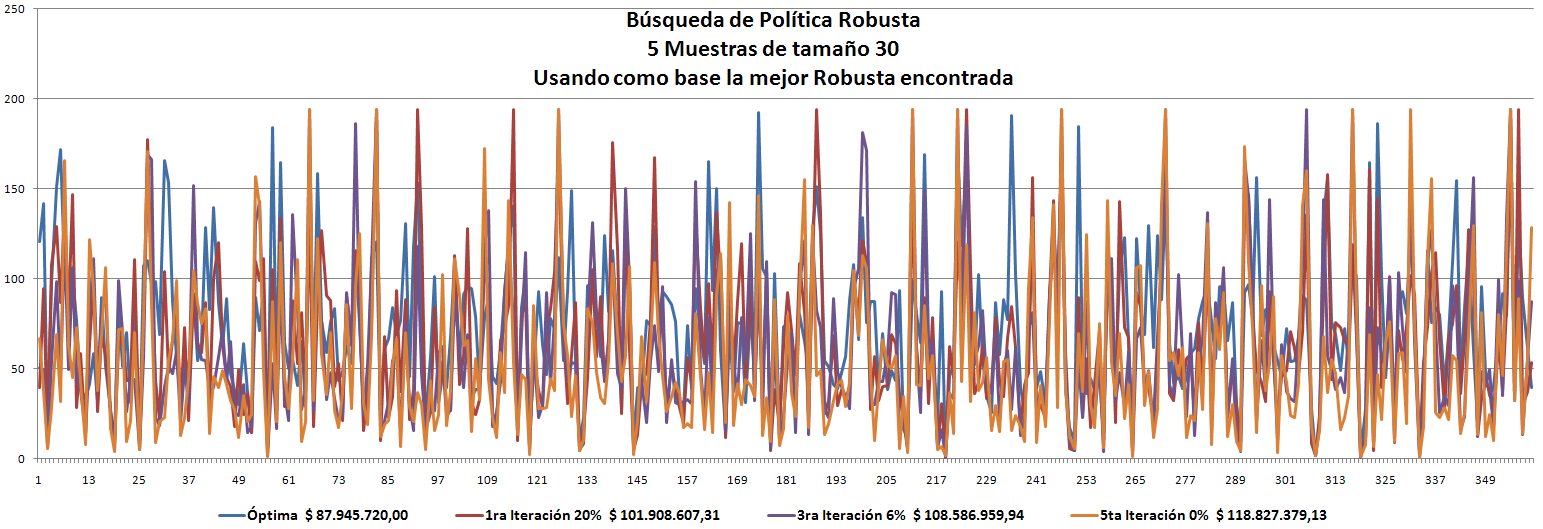
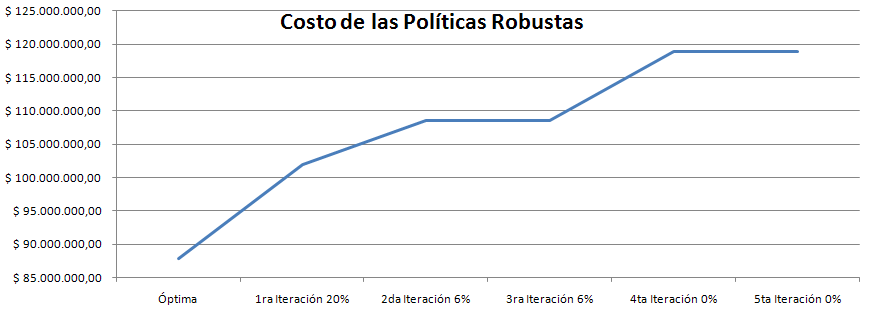
- Los Óptimos son todos muy parecidos y siempre (hasta el momento) son menores que la Robusta. ver las gráficas.
- Solo estábamos guardando como Política Robusta aquella que estuviera dentro del rango aceptable (10%), y hasta el momento no hemos obtenido ninguna.
Por estas razones estoy proponiendo lo siguiente:
- Seguir generando un número M de muestras, cada una de N series.
- Calcular una y solo una política óptima, usando la media de una de las muestras. (prácticamente todas las óptimas son iguales en cuanto a su costo)
- Usar esa política como base inicial para buscar una óptima y para las siguientes muestras usar la mejor Robusta que vayamos encontrando.
Probando lo último esperamos tener mejores resultados. En un principio vamos a considerar como mejor a aquel que tenga menor % de violaciones, en un siguiente experimento lo haremos tomando en cuenta el costo de operación que generan la políticas, luego definiremos como usar las dos al mismo tiempo.
No vamos a colocar ningún gráfico como los anteriores pero, describiré el comportamiento.
- Con la Óptima de la 1ra Muestra la búsqueda comenzó con 100% de violaciones y finalizó en 17%.
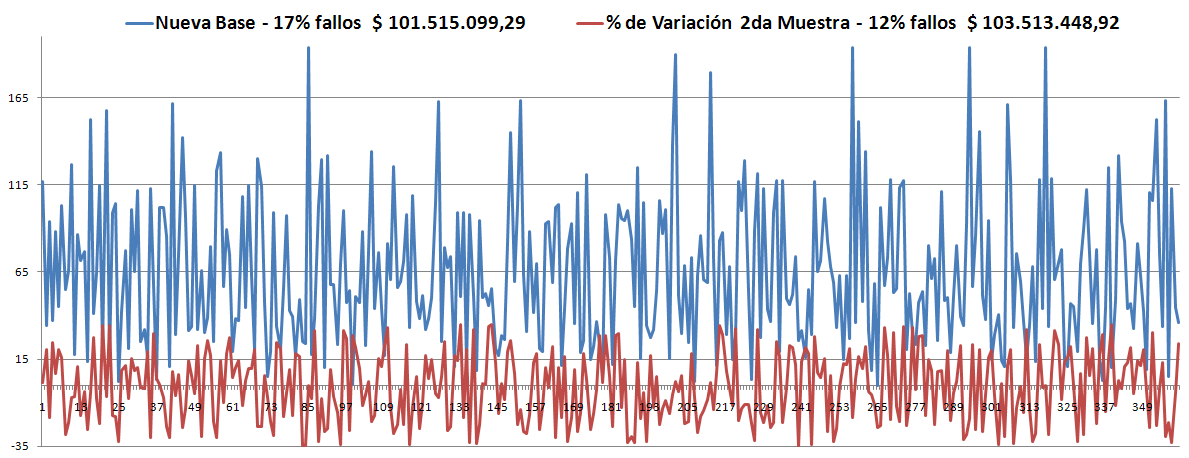
- En la 2da muestra, tomando como base la Robusta anterior, inició con 29% de violaciones, en la generación 1.700 estaba en el 13% -parece no va a mejorar- y finalizó con 13%.
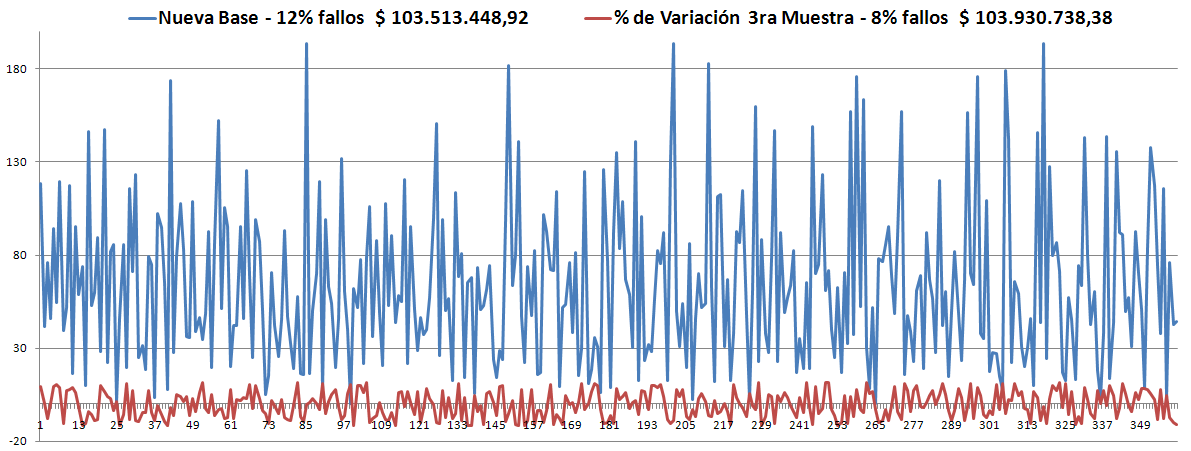
- En la 3ra muestra, tomando como base la Robusta anterior, inició con 18% de violaciones, en la generación 500 estaba en el 12%, en la generación 800 estaba en el 8% -lo más probable es que no cambie- y terminó en 8%.
- En la 4ta muestra, tomando como base la Robusta anterior, inició con 4% de violaciones -lo cual es excelente-, aunque puede significar simplemente que la misma política satisface mejor a la 4ta que a la 3ra, es muy probable que no mejore pero con esto hemos superado las expectativas que teníamos. Terminó con 4%.
- En la 5ta muestra, tomando como base la Robusta anterior, inició con 2% de violaciones lo cual es wahu. Bueno hasta el lunes
Todo esto fue trabajado con M = 5, N = 100, un 50% de variación y con 5.000 generaciones para la búsqueda del Robusto. Lo más probable es que no podamos presentar la Política Óptima casi robusta hoy por el tiempo (terminará la ejecución a las 16h30 y sola hay carros hasta las 16h00), pero el lunes estará a primera hora.