
Los archivos de las capturas de datos por USB-Serial que se obtienen en las campañas de medición en cada punto, se requieren: procesar, ordenar y obtener los valores representativos del comportamiento del RSSI y SNR.
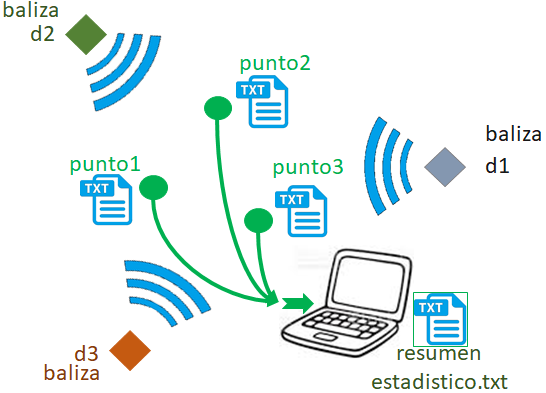
Cada archivo contiene al menos 100 lecturas a cada baliza. Los archivos se encuentran en una carpeta desde donde se procesarán y se obtendrá un archivo "resumen".
Para procesar los archivos de deben indicar los siguientes parámetros:
- medida a observar: rssi, snr
- descriptor estadistico a usar: mean, std, count, max, min, ...
- trama: rx
- una 'carpeta' donde se encuentran los archivos a procesar
- nombre del archivo de resultados
Un ejemplo de los resultados en el resumen por punto del promedio Rssi es:
resumen trama: rx medida: rssi
rssi_rx_d1 rssi_rx_d2 rssi_rx_d3 rssi_tx_d1 rssi_tx_d2 rssi_tx_d3
FCNM101 -124.396907 -129.132184 -81.620000 -98.000000 -126.632184 -78.040000
FCNM102 -114.345455 -118.917526 -92.053571 -91.000000 -118.474227 -80.482143
FCNM103 -115.459854 -124.634615 -95.453901 -91.000000 -123.173077 -76.617021
FCNM104 -115.922414 -123.678899 -110.090909 -91.000000 -122.844037 -107.933884
FCNM105 -108.239726 -124.893204 -102.007042 -91.000000 -123.582524 -99.281690
FCNM106 -128.383929 -127.910000 -117.589041 -91.000000 -127.290000 -110.082192
FCNM107 -124.429907 -123.009009 -105.078125 -91.000000 -123.225225 -102.343750
Carpeta con archivos a procesar: lectura_puntos
Archivos resultado:
para Rssi: resumen_rssimean01.txt
Para SNR: resumen_snrmean01.txt
Algortimo en Python
Para simplificar el algoritmo, se realizó una libreria de funciones, "girni_lora_libreria.py", que se debe de ubicar en la misma carpeta del algoritmo que lo usa.
Para almacenar los datos tabulados, se crea tambien el archivo de ésta tabla en formato .json, en caso de que se requiera realizar otro tipo de análisis a los datos.
''' Procesa Archivo.txt de LoRa Rssi y SNR de muestras desde un puerto Serial Girni 2020-10-07 propuesta: edelros@espol.edu.ec medida: 'rssi', 'snr' unestadistico: 'count', 'mean', 'std', 'min', '25%', '50%', '75%', 'max' modo: rx baliza a dispositivo tx difusion hacia balizas ''' import os import numpy as np import pandas as pd import girni_lora_libreria as girni # INGRESO # revisar parametros al inicio medida = 'rssi' descriptor = 'mean' trama = 'rx' # carpeta de Archivos entrada carpeta = 'Lecturas_dispositivo' # Archivos para resultados arch_rsmUnestadistico = 'resumen_'+medida+descriptor+'02.txt' arch_detalle = 'tabla_puntosdatos2.json' # PROCEDIMIENTO # lista los archivos entrada en la carpeta archivosPuntos = os.listdir(carpeta) # Lee cada archivo de un punto y tabula # las lecturas por cada trama: rx, tx # cada remitente de paquete: baliza tabula = {} for unarchivo in archivosPuntos: unpunto = girni.tabulaPunto(unarchivo,carpeta) p_nombre = unpunto['nombre'] tabula[p_nombre] = unpunto tabula = pd.DataFrame(tabula) tabula = tabula.drop(['nombre']) tabula = tabula.T # Estadistica descriptiva de cada punto tabulado descrito = {} for cadapunto in tabula.index: punto = tabula.loc[cadapunto] descrito[cadapunto] = girni.describePunto(punto) # resumen de una medida: rssi, snr rsm_medida = pd.DataFrame() for cadapunto in descrito.keys(): punto = descrito[cadapunto][trama] unafila = girni.resumen_medida(punto,medida,descriptor) rsm_medida[cadapunto] = unafila rsm_medida = rsm_medida.T rsm_medida = rsm_medida.sort_index(axis=1) # SALIDA # muestra en pantalla solo un ejemplo.head() print('resumen trama: ', trama,', medida: ', medida) print(rsm_medida.head(n=10)) # Se escribe todo el archivo a csv rsm_medida.to_csv(arch_rsmUnestadistico) # Para grabar en formato .json tabula.to_json(arch_detalle)