SCM
Posted by lismabor | Filed under Uncategorized

gestión de la cadena de suministro (SCM) es la gestión de una red interconectada de las empresas que participan en la disposición final de productos y servicios de los paquetes requeridos por los clientes finales (Harland, 1996). de suministro se extiende por gestión de la cadena todo el movimiento y almacenamiento de materias primas , trabajos en proceso de inventario, y productos terminados desde el punto de origen hasta el punto de consumo ( la cadena de suministro ).
Otra definición es proporcionada por el diccionario de APICS cuando SMC define como el «diseño, planificación, ejecución, control y seguimiento de las actividades de la cadena de suministro con el objetivo de crear valor neto, la construcción de una infraestructura competitiva, aprovechando la logística de todo el mundo, la sincronización de la oferta con la demanda y medir el desempeño a nivel mundial. «
Definiciones
Las definiciones más comunes y aceptadas de la gestión de la cadena de suministro son:
- gestión de la cadena de suministro es el, estratégica, la coordinación sistémica de las funciones tradicionales de negocios y las tácticas a través de estas funciones de negocios dentro de una empresa en particular ya través de empresas de la cadena de suministro, a los efectos de mejorar el rendimiento a largo plazo de las empresas individuales y el suministro la cadena en su conjunto (Mentzer et al. , 2001).
- Una centrada en el cliente definición viene dada por Hines 2004: P76) «Suministro de estrategias requieren cadena de un total de vista de los sistemas de los vínculos en la cadena que trabajar juntos con eficacia para crear la satisfacción del cliente al final del punto de entrega al consumidor. (Como consecuencia de los costes debe reducirse a lo largo de la cadena por la expulsión de los costes innecesarios y concentrar la atención sobre el valor añadido. eficiencia de rendimiento debe ser mayor, eliminado los cuellos de botella y la medición del desempeño debe centrarse en la eficiencia total del sistema y la distribución equitativa recompensa a los de la cadena de valor de la adición de la oferta. La oferta sistema de la cadena deben responder a las necesidades del cliente. »
- cadena de suministro en el foro mundial – gestión de la cadena de suministro es la integración de procesos de negocio clave en toda la cadena de suministro con el propósito de crear valor para los clientes y partes interesadas (Lambert, 2008) .
- De acuerdo con el Consejo de Supply Chain Management Professionals (CSCMP), gestión de la cadena de suministro abarca la planificación y gestión de todas las actividades involucradas en la contratación , adquisición , conversión ygestión de la logística . También incluye los componentes fundamentales de la coordinación y colaboración con los socios de canal , que pueden ser proveedores , intermediarios , proveedores de servicios externos de sesiones, y los clientes . En esencia, la gestión de la cadena de suministro integra la oferta y la demanda de gestión dentro y fuera de las empresas. Más recientemente, el acoplamiento flexible, auto-organización de la red de empresas que cooperan para proporcionar ofertas de productos y el servicio se ha denominado la empresa extendida .
Una cadena de suministro, a diferencia de la cadena de suministro, es un conjunto de organizaciones que están directamente vinculados por uno o más de los flujos de aguas arriba y aguas abajo de los productos, servicios, finanzas, y la información de una fuente a un cliente. La gestión de una cadena de suministro es «la cadena de suministro (Mentzer et al. , 2001).
software de gestión de la cadena de suministro incluye herramientas o módulos utilizados para ejecutar las operaciones de la cadena de suministro, gestión de relaciones con los proveedores y el control de procesos de negocio asociados.
la cadena de suministro de gestión de eventos (abreviado como SCEM) es un examen de todos los eventos posibles y los factores que pueden interrumpir una cadena de suministro. Con escenarios SCEM posibles pueden ser creados y las soluciones desarrolladas.
Los problemas abordados por gestión de la cadena de suministro
gestión de la cadena de suministro debe abordar los siguientes problemas:
- Distribución de configuración de red :, la ubicación y la red de misiones número de proveedores, instalaciones de producción, centros de distribución, almacenes, entre los muelles y los clientes.
- Estrategia de distribución : las cuestiones de control de funcionamiento (centralizada, descentralizada o compartida); plan de entrega, por ejemplo, la expedición directa , punto de embarque de billar, cross docking , DSD (entrega directa en tienda), cerró el envío de bucle, el modo de transporte, por ejemplo, de autotransporte , incluyendo camión, LTL , parcela , del ferrocarril , el transporte intermodal, incluyendo TOFC (trailer en batea) y COFC (contenedor en batea), flete marítimo, flete aéreo, estrategia de reposición (por ejemplo, tirar, empujar o híbridos), y control de transporte (por ejemplo, operados por sus propietarios, transportista privado , de transporte público , portador de contrato, o3PL ).
- Comercio-Offs de Actividades Logísticas : Las actividades mencionadas deben estar bien coordinados para lograr el menor costo total de logística. Las compensaciones pueden aumentar el costo total si sólo una de las actividades se ha optimizado. Por ejemplo, camión completo (FTL) de las tarifas son más económicas en un costo por la plataforma de menos de camión (LTL) los traslados. Sin embargo, si un camión lleno de un producto es la orden de reducir los costos de transporte, habrá un aumento en la celebración de los costos de inventario que puede aumentar los costos logísticos totales. Por tanto, es imperativo tener un enfoque de sistemas en la planificación de las actividades logísticas. Estos intercambios son esenciales para el desarrollo de la forma más eficiente y efectiva estrategia de Logística y SCM.
- Información : La integración de los procesos a través de la cadena de suministro para compartir información valiosa, incluyendo señales de demanda, pronósticos, inventario, el transporte, la posible colaboración, etc
- Gestión de inventario : cantidad y ubicación de las existencias, incluidas las materias primas, el trabajo en curso (WIP) y productos terminados.
- Cash-Flow : Organizar las condiciones de pago y metodologías para el intercambio de fondos entre entidades dentro de la cadena de suministro.
ejecución de la cadena de suministro mediante la gestión y coordinación del movimiento de materiales, información y fondos a través de la cadena de suministro. El flujo es bidireccional.
La cadena de suministro de negocio de integración de procesos
El éxito de SMC requiere un cambio de gestión de las funciones individuales a las actividades de integración en los procesos clave de la cadena de suministro. Un escenario de ejemplo: el departamento de compras realiza pedidos como los requisitos de ser conocido. El departamento de marketing, respondiendo a la demanda del cliente, se comunica con varios distribuidores y minoristas, ya que trata de determinar la manera de satisfacer esta demanda. La información compartida entre los socios de la cadena de suministro sólo puede ser aprovechado al máximo a través de la integración de procesos .
la cadena de suministro de integración empresarial proceso implica el trabajo colaborativo entre compradores y proveedores, desarrollo conjunto de productos, sistemas de información comunes y compartidos. Según Lambert y Cooper (2000), que opera una cadena de abastecimiento integrada requiere un flujo continuo de información. Sin embargo, en muchas empresas, la gerencia ha llegado a la conclusión de que la optimización de los flujos de producto no se puede lograr sin la implementación de un enfoque basado en procesos para el negocio. La cadena de suministro procesos clave indicado por Lambert (2004) [son los siguientes:
- Gestión de las relaciones
- De gestión de clientes de servicios
- Gestión de la demanda
- Cumplimiento de la orden
- Fabricación de gestión del flujo de
- Proveedor de gestión de las relaciones
- Desarrollo de producto y comercialización
- Gestión de las devoluciones
Mucho se ha escrito sobre la gestión de la demanda. Mejor en las empresas de clase tienen características similares, que incluyen los siguientes: a interior) y la colaboración externa b) las iniciativas de reducción de plomo tiempo c) la retroalimentación más estrictos de la demanda de los clientes y el mercado previsión d) el nivel del cliente
Se podría sugerir otros procesos clave de negocio críticos de suministro que se combinan estos procesos declaró por Lambert, tales como:
- Cliente de gestión de servicios
- Adquisiciones
- Desarrollo de producto y comercialización
- Fabricación de la gestión del flujo / support
- Distribución física
- Outsourcing / sociedades
- Medición del desempeño
- a) el Cliente de servicios de gestión de procesos
Customer Relationship Management se refiere a la relación entre la organización y sus clientes. Atención al cliente es la fuente de información de los clientes. También proporciona al cliente información en tiempo real sobre la programación y disponibilidad del producto a través de interfaces con la producción de la empresa y las operaciones de distribución. Las organizaciones exitosas utilice los pasos siguientes para construir relaciones con los clientes:
- determinar las metas mutuamente satisfactoria para la organización y los clientes
- establecer y mantener relaciones de los clientes
- producen sentimientos positivos en la organización y los clientes
- b) proceso de contratación
Los planes estratégicos se elaboran con los proveedores para apoyar el proceso de gestión de flujo de fabricación y el desarrollo de nuevos productos. En las empresas donde las operaciones se extienden a nivel mundial, el abastecimiento debe ser gestionada a nivel mundial. El resultado deseado es una relación ganar-ganar donde ambas partes se benefician, y una reducción en el tiempo requerido para el ciclo de diseño y desarrollo de productos. Además, la función de compras desarrolla sistemas de comunicación rápidos, como el intercambio de datos electrónicos (EDI) y la vinculación a Internet para transmitir los requisitos más rápidamente posible. Las actividades relacionadas con la obtención de productos y materiales a proveedores externos implica la planificación de recursos, el suministro de abastecimiento, la negociación, la realización de pedidos, transporte de entrada, almacenamiento, manipulación y control de calidad , muchas de las cuales incluyen la responsabilidad de coordinar con los proveedores en materia de programación, la continuidad del suministro, de cobertura, y la investigación sobre nuevas fuentes o programas.
- c) Desarrollo de producto y comercialización
Aquí, los clientes y proveedores deben integrarse en el proceso de desarrollo de productos con el fin de reducir el tiempo de comercialización. Como acortar los ciclos de vida del producto, los productos adecuados se deben desarrollar y lanzado con éxito con cada vez más cortos los calendarios previstos para seguir siendo competitivos. Según Lambert y Cooper (2000), los gestores del desarrollo del producto y el proceso de comercialización deberá:
- coordinar con la administración de relaciones con clientes para identificar las necesidades de los clientes articulado;
- seleccionar materiales y proveedores, en relación con la contratación, y
- desarrollar tecnología de producción en la fabricación de flujo para la fabricación e integración en el flujo de suministro de la mejor cadena para el producto de combinación de mercado.
- d) El flujo de los procesos de fabricación de gestión
El proceso de fabricación produce y suministra productos a los canales de distribución basados en las previsiones anteriores. Los procesos de fabricación deben ser flexibles para responder a los cambios del mercado y deben adaptarse a la personalización masiva. Los pedidos son los procesos que operan en un «justo a tiempo (JIT) en tamaños de lote mínimo. Además, los cambios en el proceso de flujo de fabricación conducir a tiempos de ciclo más corto, es decir, la capacidad de respuesta y eficiencia de la demanda de los clientes. Actividades relacionadas con la planificación, programación y apoyo a las operaciones de fabricación, tales como trabajos en proceso de almacenamiento, manipulación, transporte, y el tiempo de eliminación de los componentes, el inventario en los sitios de fabricación y la máxima flexibilidad en la coordinación de aplazamiento conjuntos geográficos y final de las operaciones de distribución física .
- e) Distribución física
Esto se refiere a movimiento de un producto terminado o servicio para los clientes. En la distribución física, el cliente es el destino final de un canal de comercialización, y la disponibilidad del producto o servicio es una parte vital del esfuerzo de comercialización de cada participante del canal. Es también a través del proceso de distribución física de que el tiempo y el espacio de servicio al cliente a ser parte integrante de la comercialización, por lo que vincula un canal de comercialización con sus clientes (por ejemplo, los fabricantes de enlaces, mayoristas, minoristas).
- f) La contratación externa y las asociaciones
Esto no es sólo la externalización de la adquisición de materiales y componentes, sino también la externalización de los servicios que tradicionalmente han sido proporcionadas por la ciudad. La lógica de esta tendencia es que la compañía se centrará cada vez más en las actividades en la cadena de valor donde se tiene una ventaja distintiva, y todo lo que externalizar más. Este movimiento ha sido particularmente evidente en la logística , donde de transporte, almacenamiento y control de inventario es cada vez más la disposición de subcontratación a los especialistas o los socios de logística. Además, la gestión y el control de esta red de socios y proveedores requiere una mezcla de ambos y participación local central. Por lo tanto, las decisiones estratégicas deben ser tomadas a nivel central, con el seguimiento y control de rendimiento de los proveedores y, a día de enlace día con socios de la logística se gestionan mejor a nivel local.
- g) La medición del rendimiento
Los expertos encontraron una fuerte relación de los más grandes arcos de la integración de proveedores y clientes a cuota de mercado y rentabilidad. Aprovechando las capacidades de los proveedores y haciendo hincapié en la perspectiva de la cadena de suministro a largo plazo en relación con el cliente puede tanto ser correlacionado con los resultados empresariales. Como la competencia de logística se convierte en un factor más crítico en la creación y el mantenimiento de ventajas competitivas, la medición de la logística se convierte cada vez más importante porque la diferencia entre operaciones rentables y no rentables se vuelve más estrecho. Los consultores de AT Kearney (1985) señala que las empresas que realizan la medición del desempeño global se dio cuenta de las mejoras en la productividad general. Según los expertos, las medidas internas son generalmente recogidos y analizados por la misma, incluidos
- Costo
- Atención al cliente
- Productividad medidas
- medición de activos y
- De calidad.
medición del desempeño externo se examina a través de medidas de la percepción del cliente y » mejores prácticas «de referencia, e incluye 1) la percepción de la medida del cliente, y 2) las mejores prácticas de evaluación comparativa.
h) la gestión de almacenamiento: En caso de reducción de costos y gastos de empresa, gestión de almacenamiento está llevando a la valiosa función frente a las operaciones. En caso de almacenamiento perfecta y oficina con todas las facilidades convenientes en las empresas, reducir los costos de mano de obra, el envío de la autoridad con el tiempo de entrega, carga y descarga de las instalaciones con un área adecuada, área de la estación de servicio, un sistema de gestión de existencias, etc
Componentes de la gestión de la cadena de suministro son las siguientes: 1. Normalización 2. Aplazamiento 3. Personalización

|
|||||||||||



CRM
Posted by lismabor | Filed under Uncategorized
")
gestión de relaciones con clientes (CRM) es una estrategia ampliamente implementadas para la gestión de una empresa interacciones con los clientes , los clientes y las perspectivas de ventas. Se trata de utilizar la tecnología para organizar, automatizar y sincronizar los procesos de negocios-principalmente las ventas de las actividades, sino también los de marketing , servicio al cliente y soporte técnico . Los objetivos generales son para encontrar, atraer y ganar nuevos clientes, cultivar y retener a los de la empresa ya tiene, atraer a los antiguos clientes de vuelta al redil, y reducir los costes de marketing y servicio al cliente. de gestión de relaciones con los clientes describe una empresa -estrategia de negocio de ancho incluyendo la interfaz departamentos-cliente, así como otros departamentos.
Los beneficios del CRM
El uso de un sistema CRM se reunirán una serie de ventajas a una empresa:
- Calidad y eficiencia
- Disminución de los costos
- Apoyo a las decisiones
- La agilidad de la empresa
Desafíos
Herramientas y flujos de trabajo pueden ser complejas, sobre todo para las grandes empresas. Anteriormente, estas herramientas se limita generalmente a la gestión de contactos : control y registro de las interacciones y las comunicaciones. Las soluciones de software luego se amplió para abarcar el seguimiento de acuerdo, los territorios, las oportunidades, y en el flujo de ventas propia. Luego vino el advenimiento de las herramientas para otras funciones de la interfaz de negocio-cliente, como se describe a continuación. Estas herramientas han sido y siguen siendo, ofrece como en las instalaciones de software que las empresas de compra y ejecutar en su propia infraestructura de TI.
A menudo, las implementaciones son iniciativas aisladas, fragmentadas por los distintos departamentos para hacer frente a sus propias necesidades. Sistemas que se inician desunidos suelen permanecer de esa manera: el pensamiento silos procesos de decisión que con frecuencia conducen a separar incompatibles sistemas y procesos y disfuncionales y.
reputación de negocio se ha convertido en un reto cada vez mayor. El resultado de la fragmentación interna que es observado y comentado por los clientes ahora es visible para el resto del mundo en la era del cliente sociales, donde en el, sólo los empleados pasados o socios eran conscientes de ello. Abordará la fragmentación requiere un cambio en la filosofía y la mentalidad dentro de una organización para que todo el mundo considera el impacto en el cliente de la política, las decisiones y acciones. La respuesta humana a todos los niveles de la organización puede afectar a la experiencia del cliente para bien o para mal. Incluso un cliente insatisfecho puede dar un duro golpe para un negocio.
Tipos / variaciones
automatización de la fuerza de ventas
automatización de la fuerza de ventas (SFA) consiste en utilizar el software para agilizar todas las fases del proceso de venta, minimizando el tiempo que los representantes de ventas necesitan para gastar en cada fase. Esto permite a los representantes de ventas para buscar más clientes en un corto período de tiempo que de otro modo sería posible. En el corazón de la SFA es un sistema de gestión de contactos para el seguimiento y registro de todas las etapas del proceso de venta para cada cliente potencial, desde el contacto inicial hasta la disposición final. Muchas de las aplicaciones SFA también incluyen ideas en oportunidades, los territorios, las previsiones de ventas y automatización de flujo de trabajo, generación de cotizaciones, y el conocimiento del producto. Módulos para la Web 2.0 e-comercio y los precios son nuevas, emergentes intereses en SFA.
Marketing
Los sistemas de CRM para la comercialización de ayudar a la empresa identificar y apuntar a clientes potenciales y generar oportunidades para el equipo de ventas. Una capacidad clave de marketing es el seguimiento y medición de campañas multicanal, incluyendo correo electrónico, búsqueda, medios de comunicación social, teléfono y correo directo. Métricas de seguimiento incluyen los clics, las respuestas, clientes potenciales, ventas e ingresos. Esto ha sido sustituida por la automatización de marketing y Prospect Relationship Management (PRM) soluciones que siguen el comportamiento del cliente y criarlas desde el primer contacto a la venta, a menudo eliminando el proceso de venta activa total.
Atención al cliente y soporte Reconociendo que el servicio es un factor importante para atraer y retener a los clientes, las organizaciones están cada vez más a la tecnología para ayudarles a mejorar sus clientes su experiencia, mientras que el objetivo de aumentar la eficiencia y minimizar los costos. Sin embargo, un estudio de 2009 reveló que sólo el 39% de los ejecutivos de las empresas creen que sus empleados tengan las herramientas adecuadas y la autoridad para resolver los problemas del cliente «..
Google Analytics
análisis pertinentes de las capacidades se han entretejido en las aplicaciones de ventas, marketing y servicio. Estas características pueden ser complementada y aumentada con enlaces a las aplicaciones independientes, construidos expresamente para el análisis e inteligencia de negocios. análisis de ventas permiten a las empresas monitorizar y comprender las acciones y preferencias del cliente, a través de pronóstico de ventas y calidad de los datos.
aplicaciones de marketing en general, vienen con el análisis predictivo para mejorar la segmentación y selección de beneficiarios, y las características para medir la eficacia de, fuera de línea en línea, y la campaña de marketing en buscadores. análisis Web han evolucionado significativamente desde su punto de partida de sólo el seguimiento de clics de ratón en los sitios Web. Mediante la evaluación de «señales de compra», los vendedores pueden ver que las perspectivas son más propensos a realizar transacciones y también identificar a aquellos que están empantanados en un proceso de ventas y necesita ayuda. Personal de comercialización y las finanzas también utilizan análisis para evaluar el valor de los programas multi-facetas en su conjunto.
Este tipo de análisis están aumentando en popularidad como las empresas exigen una mayor visibilidad del rendimiento de los centros de llamadas y otros servicios y canales de soporte, con el fin de corregir los problemas antes de que afecten los niveles de satisfacción. centrado aplicaciones de apoyo suelen incluir paneles similares a los de las ventas, además de funciones para medir y analizar los tiempos de respuesta, calidad de servicio, desempeño de los agentes, y la frecuencia de los diferentes temas.
integrada de colaboración
Departamentos dentro de las empresas – especialmente las grandes empresas – para funcionar con poco. Colaboración tienden Más recientemente, el desarrollo y la adopción de estas herramientas y servicios han fomentado una mayor fluidez y la cooperación entre las ventas, servicio y marketing. Esto encuentra su expresión en el concepto de los sistemas de colaboración que utiliza la tecnología para construir puentes entre los departamentos. Por ejemplo, la regeneración de un apoyo técnico del centro puede iluminar a los comerciantes acerca de los servicios específicos y los clientes las características del producto está pidiendo. Representantes, a su vez, quiero ser capaz de desempeñar estas oportunidades sin la carga de volver a entrar en los registros y datos de contacto en un sistema separado de SFA.
La pequeña empresa
Para la pequeña empresa , servicio al cliente de base se puede lograr mediante un sistema gestor de contactos: una solución integrada que permite a las organizaciones e individuos de manera eficiente y registrar las interacciones pista, incluyendo correos electrónicos, documentos, trabajos, faxes, programación y mucho más. Estas herramientas se centran generalmente en las cuentas y no en los contactos individuales. También suelen incluir una visión oportunidad para el seguimiento de las tuberías de venta más el añadido funcionalidad para la comercialización y servicio. Al igual que con las grandes empresas, las pequeñas empresas están descubriendo el valor de las soluciones en línea, especialmente para móvil y teletrabajo trabajadores.
Los medios sociales
Los medios sociales sitios como Twitter , LinkedIn y Facebook están amplificando la voz de la gente en el mercado y están teniendo ya efectos de gran alcance profundo en las formas en que la gente compra. Los clientes ahora pueden investigar las compañías en línea y luego pedir recomendaciones a través de los canales de medios de comunicación social, por lo que su decisión de compra, sin entrar en contacto con la empresa.
La gente también utiliza los medios de comunicación social para compartir opiniones y experiencias de empresas, productos y servicios. Como los medios de comunicación social no es la forma más amplia moderado o censurados como principales medios de comunicación, las personas pueden decir lo que quieran acerca de una empresa o marca, positivo o negativo.
Cada vez más, las empresas están buscando para acceder a estas conversaciones y participar en el diálogo. Más de unos pocos sistemas son la integración de los sitios de redes sociales. Los medios sociales promotores de citar una serie de ventajas comerciales, tales como el uso de comunidades en línea como una fuente de calidad alta y conduce un vehículo para multitud de abastecimiento de soluciones a problemas de apoyo de cliente. Las empresas también pueden aprovechar los hábitos de los clientes declaró y preferencias de «hiper-objetivo» de sus ventas y comunicaciones de marketing.
Algunos analistas consideran que a empresa de marketing de negocios debe proceder con cautela al tejer las redes sociales en sus procesos de negocio. Estos observadores recomiendan cuidadosa investigación de mercado para determinar si, y donde el fenómeno puede proporcionar beneficios medibles para las interacciones del cliente, ventas y soporte. Se dice que las personas sienten que sus interacciones son de igual a igual entre ellos y sus contactos, y resienten la participación de la empresa, a veces respondiendo con negativos sobre la empresa.
sin fines de lucro y basada en la afiliación
Sistemas de sin fines de lucro y las organizaciones basadas en la afiliación ayudar a los mandantes de pista y su participación en la organización. Capacidades típicamente incluyen el seguimiento de los siguientes: recaudación de fondos, la demografía, niveles de afiliación, directorios de miembros, el voluntariado y las comunicaciones con los individuos.
Muchas incluyen herramientas para la identificación de los posibles donantes sobre la base de donaciones anteriores y la participación. A la luz del crecimiento de las redes sociales, puede haber cierta superposición entre las herramientas sociales de la comunidad / impulsada y herramientas non-profit/membership.
Estrategia
Para las empresas de mayor escala, un plan completo y detallado es necesario para obtener la financiación, los recursos y el apoyo de toda la compañía que pueden hacer que la iniciativa de elegir y aplicar un sistema exitoso. Los beneficios se deben definir, evaluar riesgos y costes cuantificados en tres áreas generales:
- Procesos: Si bien estos sistemas tienen muchos componentes tecnológicos, procesos de negocio se encuentran en su núcleo. Puede ser visto como un cliente-céntrica forma más de hacer negocios, gracias a la tecnología que consolida y distribuye de forma inteligente la información pertinente sobre los clientes, ventas, efectividad del marketing, la capacidad de respuesta, y las tendencias del mercado. Por lo tanto, la empresa debe analizar sus flujos de trabajo y procesos de negocio antes de elegir una plataforma tecnológica, algunos probablemente necesitará re-ingeniería para servir mejor a la meta global de ganar y la satisfacción de los clientes. Por otra parte, los planificadores deben determinar los tipos de información del cliente que son más relevantes, y la mejor manera de emplearlos.
- Gente: Por una iniciativa para ser eficaz, una organización debe convencer a sus servicios para que las nuevas tecnologías y flujos de trabajo beneficiará a los empleados, así como clientes. Los altos ejecutivos deben ser visibles y firmes defensores de que claramente se puede afirmar y apoyar la justificación del cambio. Colaboración, trabajo en equipo y la comunicación de dos vías debe fomentarse a través de fronteras jerárquicas, especialmente con respecto a la mejora de procesos.
- Tecnología: En la evaluación de la tecnología, los factores clave son la alineación con la compañía de negocio de proceso de la estrategia y objetivos, incluyendo la capacidad de entregar la información correcta a los empleados adecuados y suficientes facilidad de adopción y uso. Plataforma es la mejor selección realizada por un grupo cuidadosamente seleccionado de los ejecutivos que entienden los procesos de negocio a automatizar, así como los problemas de software. Dependiendo del tamaño de la empresa y la amplitud de los datos, la elección de una aplicación puede tardar desde unas semanas a un año o más.
Aplicación
Cuestiones de aplicación
El aumento de los ingresos, tasas más altas de satisfacción del cliente, y un significativo ahorro en los costos de operación son algunos de los beneficios a una empresa. Los defensores destacan que la tecnología debería aplicarse sólo en el contexto de los estratégicos y operativos de una planificación cuidadosa. Las puestas en práctica casi siempre se quedan cortos cuando uno o más aspectos de esta prescripción se tienen en cuenta:
- La mala planificación: puede fallar fácilmente cuando los esfuerzos se limitan a la elección e implementación de software, sin acompañamiento, razón contexto, y el apoyo a la fuerza de trabajo. Iniciativas. En otros casos, las empresas simplemente automatizar fallas de cara al cliente en lugar de re diseñar los procesos de acuerdo a las mejores prácticas.
- integración de los pobres: Para muchas empresas, integraciones parciales son iniciativas que responden a una necesidad evidente: un determinado proceso orientado hacia el cliente o dos o automatización de un favor o ventas de sus clientes del canal. respalde la mejora Estas «soluciones puntuales» oferta o no poca integración o la alineación con la estrategia global de una empresa. Ofrecen una menos de vista de cliente completa ya menudo conducen a una experiencia de usuario satisfactoria.
- Hacia una solución: pensar la superación de silos. Los expertos aconsejan a las organizaciones para reconocer el inmenso valor de la integración de sus operaciones de cara al cliente. En este punto de vista, a nivel interno-enfocada, centrada en puntos de vista-departamento debe ser descartada en favor de la reorientación de los procesos hacia el intercambio de información a través de marketing, ventas y servicio. Por ejemplo, representantes de ventas que necesitas saber sobre temas de actualidad y comercialización de las promociones pertinentes antes de intentar la venta cruzada a un cliente específico. el personal de comercialización deberá ser capaz de aprovechar la información del cliente de las ventas y el servicio a las campañas de destino mejor y ofertas. Y agentes de apoyo requieren y completo acceso rápido a las ventas de un cliente y servicio de la historia.
Aprobación cuestiones
Históricamente, el paisaje está lleno de casos de bajas tasas de adopción. En 2003, un informe de Gartner estima que más de $ 1 millones se habían gastado en software que no se estaba utilizando. Una investigación más reciente indica que el problema, aunque tal vez menos grave, está muy lejos de estar resuelto. De acuerdo con CSO Insights, menos del 40 por ciento de 1.275 empresas participantes-las tasas de adopción de usuario final por encima del 90 por ciento.
En una encuesta de 2007 del Reino Unido, las cuatro quintas partes de los altos ejecutivos informaron que su mayor reto es conseguir su personal para utilizar los sistemas que había instalado. Además, el 43 por ciento de los encuestados dijeron que usan menos de la mitad de la funcionalidad de su sistema existente, el 72 por ciento indicaron que el comercio funcionalidad para facilitar su uso, el 51 por ciento citó la sincronización de datos como una cuestión importante, y el 67 por ciento dijo que encontrar tiempo para evaluar sistemas es un problema importante. Con los gastos previstos para superar los $ 11 mil millones en 2010, las empresas necesitan para afrontar y superar los desafíos persistentes adopción. Los especialistas ofrecen estas recomendaciones para aumentar las tasas de adopciones y persuadir a los usuarios combinar estas herramientas en su trabajo diario:
- Elegir un sistema que es fácil de usar: no todas las soluciones son iguales, algunos proveedores ofrecen aplicaciones que son más fácil de usar – un factor que debe ser tan importante para la decisión es la funcionalidad.
- Elija las capacidades apropiadas: los empleados necesitan saber que el tiempo que invierten en el aprendizaje y en el uso del nuevo sistema no será en vano, en efecto, que se producirá personales ventajas, de lo contrario, se pasará por alto o eludir el sistema.
- Proporcionar capacitación: cambiar la forma de trabajar no es tarea fácil, para tener éxito, algunas de familiarización y apoyo de servicio de asistencia suelen ser necesarios, incluso con los sistemas más útiles de hoy.
- Predicar con el ejemplo: la alta gerencia debe utilizar la nueva aplicación de sí mismos, mostrando así a los empleados que los principales líderes apoyan plenamente la aplicación – o bien se inclinará el curso final de la iniciativa al fracaso, por el riesgo de una reducción de la tasa de adopción en gran medida por los empleados.
La privacidad y seguridad de datos del sistema
Una de las funciones principales de estas herramientas es recoger información sobre los clientes, por lo que una empresa debe tener en cuenta el deseo de privacidad y seguridad de los datos , así como las normas legislativas y culturales.Algunos clientes prefieren la seguridad de que sus datos no serán compartidos con terceras partes sin su consentimiento previo y que se den las garantías para evitar el acceso ilegal por parte de terceros.
VISIÓN DEL CRM




ERP
Posted by lismabor | Filed under Uncategorized

Esta noche he tenido una pequeña crisis de insomnio y me he dedicado a dar vueltas por el blog (todos tenemos nuestros vicios). Me he dado cuenta de que aunque os hemos comentado algunas soluciones ERP, no hemos tratado a fondo el concepto de qué es un ERP y cómo está el mercado de estos productos. Muchos de vosotros lo tendréis claro, pero quizá otros no tanto, así que vamos a por ello.
Un ERP es un software de gestión integral que cubre todas las áreas en las que trabaja un empresa. La ventaja de estas soluciones es que la información sólo se introduce una vez y, con ello, ya está disponible para todos los que deben tratarla de una u otra forma. Cuando el departamento de compras introduce los datos de una factura, éstos ya están disponibles para contabilidad, control presupuestario y gerencia, que los tratarán según sus necesidades de información.
Está compuesto por diferentes módulos que cubren cada una de las actividades que realizamos, aunque el que utilicemos un software ERP no quiere decir que tengamos que utilizar todos sus módulos, pero sí que todos ellos deben estar disponibles en caso necesario. Todos estos sistemas disponen de una serie de características que los definen, sobre las que destacaría las siguientes:
SISTEMAS EMPRESARIALES DEL NEGOCIO

ERP

Más que programas de ordenador son sistemas de información que integran aplicaciones informáticas para gestionar todos los departamentos y funciones de una empresa: contabilidad financiera y analítica, finanzas, producción, mantenimiento, logística, recursos humanos, materiales, gestión de activos, compras y pagos, ventas y cobros, bancos y efectos, tesorería, cartera, gestión de proyectos, etc.
Por tanto la característica principal que distingue a un ERP es la integración, es decir:
 Está de moda Está de moda
Está de moda tener un ERP y todos los empresarios -y los fabricantes de software- presumen de que su programa es un ERP, de forma que a un mero programa de contabilidad le llaman ERP. Un truco para saber si es de verdad un ERP es preguntar:
|
2) ¿Qué componentes tiene un ERP?
Como podemos apreciar en la imagen de la derecha, tomada del libro «Sistemas de Información Integrados, (ERP)«, Documento AECA Nuevas Tecnologías y Contabilidad, los ERP incluyen varios componentes:
1) El hardware, en el que el requerimiento mínimo es un servidor, pero son frecuentes las llamadas granjas de servidores multiprocesador con requerimientos de seguridad, tolerancia a fallos, redundancia, etc.
2) El software. Los sistemas operativos predominantes hoy en día son Windows, Unix, en distintas versiones, AS/400 y Linux.
3) Gestor de base de datos. Suele ser común entre los fabricantes de software ofrecer la posibilidad de escoger entre distintos motores de base de datos. Ejemplos son Oracle o MySQL.
4) Aplicación. Este componente es el corazón del sistema, ya que proporciona la funcionalidad requerida por el usuario, reflejando los procesos internos de la empresa. En cuanto a qué módulos contiene un ERP, de nuevo el abanico de posibilidades es amplio. En la figura se muestran diversos módulos que suelen aparecer:
- Gestión Financiera (agrupa típicamente las funciones de Contabilidad, Tesorería, Presupuestos y Activos Fijos).
- Ventas/Compras/SCM (incluye la funcionalidad referida a la gestión de la cadena de suministro, aprovisionamientos, gestión del ciclo de ventas desde la presentación de ofertas hasta la facturación, etc).
- Fabricación (control y gestión de los procesos de fabricación);
- Gestión de Almacenes/Logística (permite al usuario la gestión de almacenes en sus distintas variantes);
- Gestión de Proyectos (Control y gestión de los proyectos en sus distintas fases.)
- CRM (Gestión de la empresa con sus clientes, como clientes potenciales, gestión documental,
datos e informes, referencias, marketing, ofertas, pedidos, etc.);- Recursos Humanos (Gestión de la empresa con sus empleados, como datos personales, carreras, control de presencia, etc).
5) Interfaz de Usuario. Todos los componentes anteriores no servirían de nada sin una adecuada interfaz que permita al usuario trabajar con la aplicación. Hoy en día es cada vez más habitual que sea el propio navegador web, es decir el Explorer o Firefox.
3) Todo es «multi»
Una característica fundamental de estos programas es su potencia y versatilidad. En ellos todo es «multi», pues permiten utilizar diferentes idiomas, monedas, planes y prácticas contables. Además pueden operar en diferentes plataformas informáticas y sistemas operativos como son IBM AS/400 o Digital Alpha, con Windows NT, unix, etc. En cuanto a las prestaciones de los módulos de contabilidad, destacan las posibilidades de análisis de la información contable, auditoría, asignación de presupuestos, generación de informes, consolidación.
En la figura vemos un volcado de pantalla del ERP Openbravo. (http://demo1.openbravo.com/openbravo/security/Menu.html) y sus diferentes módulos. [Ir a: Financial management -> accounting -> transactions -> G/ Journal]
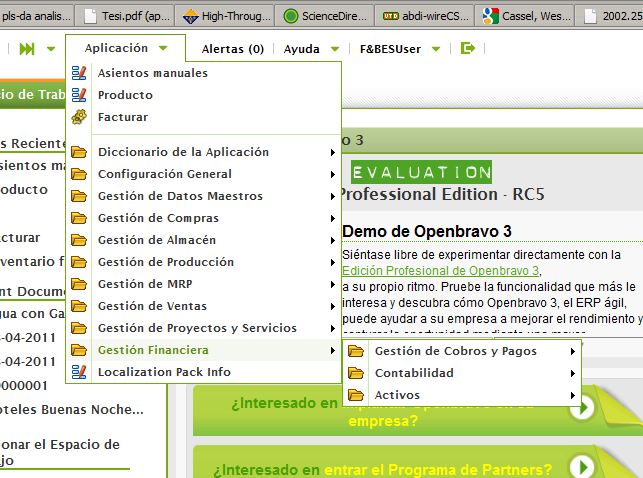
4) Los fabricantes de ERP
Algunos de los principales proveedores de ERP son: SAP (R/3), Oracle (Oracle 8), J.D.Edwards (OneWorld), PeopleSoft, Baan, Computer Associates (Unicenter TNG) y System Software Associates (SSA).
SAP, multinacional del software especializada en ERP fue creada en 1972, en Alemania, tiene varios miles de empleados en todo el mundo. Es el líder mundial en ERP, con sus aplicaciones instaladas en la mitad de las 500 mayores empresas del mundo. Es el cuarto fabricante de software del mundo. SAP permite llevar la gestión de varias compañías, en distintas monedas, con base en más de un país. Tiene una filosofía horizontal, en el sentido de que la misma aplicación se puede adaptar a todo tipo de negocio. Sin embargo, SAP, consciente de que cada negocio tiene unas particularidades, desde 1995 también ha desarrollado soluciones verticales. Por ejemplo, una compañía eléctrica tiene miles de clientes y su sistema de facturación debe estar muy desarrollado. En cambio, unos astilleros, reciben muy pocos pedidos. Por esta razón está desarrollando soluciciones informáticas específicas para cada sector. |
- Oracle-J.D. Edwards-PeopleSoft, (http://www.oracle.com).
- Navision, (http://www.microsoft.com/dynamics/default.mspx) orientada a empresas más pequeñas [adquirida por Microsoft en mayo 2002]
- SSA Global (Infor) (http://www.ssaglobal.com).
Muchos empresas grandes no pueden pagar los precios de los anteriores productos, pero sí necesitan de las prestaciones de un ERP. En este caso acuden a fabricantes nacionales que ofrecen productos con la misma filosofía pero a un precio mucho menor. Por ejemplo, son empresas especializadas en ERP:
- EON, (http://www.eon.bs)
- OpenBravo (http://demo.openbravo.com/openbravo/security/Login_FS.html) Software libre, ASP, demo online
- IberAccess, (http://www.iberacces.com)
WEB 2.0
Posted by lismabor | Filed under Uncategorized

Sin perjuicio de definiciones más elaboradas, podemos referirnos a la Web 2.0 como aquelconjunto de tecnologías y aplicaciones de Internet que hacen mucho más sencilla la tarea de publicar contenidos en la Red.
Uno de sus primeros referentes lo constituye Youtube. El más famoso portal de vídeos de Internet basa su éxito en la enorme facilidad para subir cualquier vídeo a su sistema por parte de los propios usuarios, compartiéndolo de modo casi instantáneo con el mundo.
En la Web 2.0 el internauta se libera de su tradicional papel pasivo, como mero “consumidor” de la Red, para convertirse en un activo “creador” de contenidos para el medio.
Esto, tal y como hemos visto anteriormente, supone una verdadera revolución con grandes consecuencias culturales, sociales y políticas que aún estamos empezando a vislumbrar.
Sin embargo, me preocupan ahora, por razón del tema de mi charla, sus especiales consecuencias jurídicas.
Es la nueva forma de aprovechar la red, permitiendo la participación activa de los usuarios, a través de opciones que le dan al usuario voz propia en la web, pudiendo administrar sus propios contenidos, opinar sobre otros, enviar y recibir información con otras personas de su mismo estatus o instituciones que así lo permitan. La estructura es más dinámica y utiliza formatos más modernos, que posibilitan más funciones.
Importancia
La interacción de los usuarios es fundamental, el hecho de que las personas puedan participar de los contenidos les hace sentirse parte de la red, aumenta el interés por la misma y permite que los contenidos originales de ciertas páginas sean alimentados por particulares, que se abran discusiones, se comparta acerca de temas comunes entre personas de toda clase, entre otras posibilidades. Todo esto le da a la web un valor adicional, el usuario no esta solo para buscar y recibir información sino para emitirla, construirla y pensarla.
Características
- Las páginas son dinámicas, integran recursos multimedia como videos, sonidos, que se pueden compartir.
- Los formatos utilizados para diseñarlas son java script, PHP, u otras similares, que permiten más funcionalidad.
- Emplean interfaces de fácil entendimiento para la interacción del usuario.
- La información se puede presentar en varias formas ( escrita, audiovisual), y que esta se comparta entre los usuarios o entre estos y los dueños de las páginas.
- Permite que el usuario cree su propio contenido.
- La información se puede transmitir unidireccional o bidireccionalmente.
Y sobre todo… estimula y aprovecha la inteligencia colectiva en beneficio de internet.

aqui le adjunto descripción sobre la pagina de web.
ILWIS GIS
Posted by lismabor | Filed under Uncategorized

Que es ILWIS?
the Integrated Land and Water Information System.
Integración de SIG y herramientas para el procesamiento y análisis de productos generados por sensores remotos.
Desarrollado por ITC.
Diseñado originalmente en 1985 para un proyecto de zonificación de uso del suelo y manejo de cuencas en Sumatra.
Desde 1989 ± 5000 sistemas instalados en > 100 países.
Usado extensivamente en cursos dictados en y por fuera del ITC, proyectos e investigación.
El sistema incluye:
– Procesamiento de imágenes
– Análisis espacial
– Preparación de mapas
Fácil de aprender y usar:
– Ayuda completa “en-linea” (online)
– Tutoriales para uso directo en los cursos
– 25 “estudios de caso” que incluyen varias disciplinas.
Que se puede hacer con ILWIS?
Entrada de datos.
Administración de datos.
Análisis de datos.
Preparación de resultados: mapas (data output)
– Los datos son geográficamente referenciados: La información es identificada de acuerdo a su localización.
Instalación de ILWIS

ILWIS es un acrónimo para la gestión integrada de Tierras y Aguas del Sistema de Información, un independiente integrado paquete de SIG desarrollado en el Instituto Internacional de Geoinformación de Ciencia y Observación de la Tierra (ITC), Enschede, Holanda. ILWIS fue construido originalmente para los propósitos educativos y aplicaciones de bajo costo en los países en desarrollo. Su desarrollo comenzó en 1984 y la primera versión (DOS versión 1.0) fue lanzado en 1988. ILWIS 2.0 para Windows fue lanzado a finales de 1996, y un compacto y estable versión más 3.0 (Win 95) fue lanzado a mediados de 2001. A partir de 2004, ILWIS fue distribuido exclusivamente por el CCI como shareware a un precio nominal. Desde julio de 2007, ILWIS cambiado con el código abierto y el CCI no proporcionará apoyo para su desarrollo futuro. Un mayor desarrollo de ILWIS puede ser seguido a través de todo el Norte de la iniciativa 52 ya través de la lista de correo ILWIS .
ILWIS (3.5) ofrece una gama de procesamiento de imágenes, vectoriales, raster, estadística, bases de datos geoestadísticas y operaciones similares. Además, un usuario puede crear nuevos guiones, modifica los menús de operación e incluso construir Visual Basic, Delphi, C + + o aplicaciones que se ejecutarán en la parte superior de ILWIS y el uso de sus funciones internas. La ventaja real de ILWIS es que todas las operaciones se pueden ejecutar desde línea de comandos mediante la sintaxis de ILWIS ; lista de comandos a continuación, se pueden combinar en ILWIS scripts para automatizar el procesamiento de datos. Para obtener más información sobre ILWIS, su diseño, las operaciones y la sintaxis, tratar de obtener algunos de los estudios siguientes:
- Hengl, T., Maathuis, BHP, Wang, L., 2008. Geomorphometry en ILWIS . En: T. Hengl y Reuter, (Eds), Geomorphometry HI: Geomorphometry: Conceptos, Software, Aplicaciones. La evolución de la Ciencia del Suelo, vol. 33, Elsevier, pp 309-330
- Geo Unidad de Desarrollo de Software, 2001. ILWIS Académico Guía del usuario 3.0 . Instituto Internacional para la Ciencia de la Información Geo y Observación de la Tierra (ITC), Enschede, 530 pp
- ILWIS documentación de ayuda .
La> versión 3.5 de ILWIS (una instalación pueden ser obtenidos a partir de aquí ) se desarrolla como un proyecto de MS Visual 2008. la interfaz de usuario ILWIS y ILWIS funcionalidad de análisis han sido completamente separado lo que es más fácil escribir lado las aplicaciones de servidor de ILWIS. Esto nos permite controlar ILWIS también de R, por ejemplo, estableciendo la ubicación de ILWIS en su máquina:
> ILWIS <- «C: \ \ Progra ~ 1 \ \ N52 \ \ Ilwis35 \ \ IlwisClient.exe-C «
Tipos de datos en ILWIS: Tele-detección
Teledetección es la disciplina que se ocupa de adquirir información acerca de los sistemas terrestres sin entrar, de manera directa en, contacto con ellos.
Objetos espaciales
Puntos: Definido por un único par de coordenadas X y Y
» Estaciones pluviométricas, puntos de muestreo.
Líneas: Objetos lineales; conjunto de coordenadas X y Y
» drenaje, curvas de nivel.
Área: Objetos que ocupan una cierta área
» Unidades geológicas, uso del suelo.
Concepto en ILWIS:
Que hay de nuevo en la versión 3?
")
• Aplicación 32-bit
– Full compatibilidad con Windows 95/98/NT4 y 2000
– Limitaciones en la asignación de memoria removidos
– Se pueden asignar nombres largos a los archivos (sin dejar
espacios entre palabras)
• Capacidad para importar/exportar extendidas
– Conversiones a través de PCI’s GeoGateway®, reconoce mas de 100 formatos de tablas y mapas.
• Supresión de limitaciones
– Nueva estructura de datos para los mapas de puntos, segmentos y polígonos, que se traduce en mayor exactitud para la localización de datos en formato vectorial
– Limitación de número máximo de puntos por segmento ha sido
removida.
– Limitación de número máximo de segmentos y polígonos por mapa ha sido removida.
– Limitación de número máximo de columnas en un mapa raster ha sido removida.
• Interface del usuario
modernizada
– Lista de operaciones (operation-list) tambien
disponible como “tree view”
– Ventana de manejo de los datos como un
catálogo en forma de “tree view”, incluyendo leyenda
– Ventanas acoplables
– Propiedades de los datos tabuladas

Administración de datos ha sido mejorada
– Catálogos multiples en la ventana principal
– Es posible seleccionar, copiar y borrar objetos multiples
– Colección de objetos “object collection”:
contenedor de objetos relacionados
– Organización y visualización de detalles de los diferentes objetos
• Aplicaciones de ayuda al usuario “Userfriendly”
– Inicio de tabla digitalizadora
– Importar tablas ASCII
– Anexar columnas
• Interface preparación de mapas mejorada “Map Layout”
– WISIWYG interface con multiples mapas y anotaciones en la escala especificada.
• Herramientas para visión estereoscópica
– Crear pares estereoscópicos a partir de fotografias aéreas.
– Pares estereoscópicos pueden visualizarse como anaglifos o usando un estereoscopio adaptado a la pantalla.
Ayuda en línea mejorada
– HTML-ayuda brindada a través de una interfaces moderna
– Contenidos mejorados, capacidad de búsqueda .
PANTALLA DE ILWIS
")
y si kiere saber mas sobre este GIs viste a : www.ilwis.org
GEOSERVER-GIS
Posted by lismabor | Filed under Uncategorized
![]()
GeoServer es un servidor de software de código abierto escrito en Java que permite a los usuarios compartir y editar los datos geoespaciales. Diseñado para la interoperabilidad, que publica los datos de cualquier fuente de datos espaciales importantes utilizando estándares abiertos.
Al ser un proyecto impulsado por la comunidad, GeoServer es desarrollar, probar, y apoyado por un grupo diverso de individuos y organizaciones de todo el mundo.
GeoServer es la implementación de referencia del Open Geospatial Consortium (OGC) Web Feature Service (WFS) y Web Coverage Service (WCS) las normas, así como un alto rendimiento certificado de cumplimiento Web Map Service (WMS). GeoServer forma un componente básico de la Web Geoespacial.
GEOserver permite el intercambio y la edición de los datos que se utiliza para generar los mapas, incorporar sus datos y aplicaciones en sus sitios web
Geoserver es software libre, reduce significativamente las barreras financieras a la entrada en comparación a los productos de SIG, no sólo es gratuita, también es de código abierto. Correcciones de errores y mejoras en el software por parte de la comunidad.
La comunidad GeoServer se complace en anunciar que la primera versión candidata de GeoServer 2.1 ya está disponible para descarga .El equipo ha estado ocupado trabajando en algunos de los nuevos grandes mejoras y características desde 2.1-beta3.
Lo primero es la integración GeoWebCache , permitiendo a los clientes disfrutar de los beneficios del almacenamiento en caché del azulejo a través de la regular WMS extremo GeoServer. Esto permite a GeoWebCache transparente de proxy para el WMS GeoServer sin la necesidad de un extremo de servicio independiente. Aprovechando la reciente agregó disco del contingente funcionalidad, GeoWebCache ahora ofrece la posibilidad de establecer límites en la cantidad de espacio en disco utilizado para los azulejos de almacenamiento, permitiendo a los usuarios controlar y limitar el tamaño de la cache de bloques en el disco. Muchas gracias a Gabriel Roldán para el gran mejora GeoWebCache.
Esta versión también trae algunas mejoras en RESTConfig , que ahora está disponible con GeoServer de forma predeterminada para que los usuarios ya no necesitan instalar como un plugin separado. Las mejoras a la API de incluir el archivo de operación de carga que ahora permite subir archivos a un almacén de datos existente. Este añadido permite a los usuarios cargar un archivo de forma y lo han convertido automáticamente en una base de datos PostGIS, publicarlo como una capa PostGIS y no como una capa Shapefile. Por último, la API también apoya las operaciones DELETE recursiva, por lo que es más conveniente para eliminar los recursos que contienen otros recursos como las tiendas o áreas de trabajo. Gracias a David Winslow y Justin Deoliveira de OpenGeo de estas mejoras.
Gracias a un gran trabajo de la gente de Geosolutions , reproyección rendimiento trama ha mejorado considerablemente mediante el uso de appoximations lineal de funciones de transformación. Esta mejora se ha añadido inicialmente en el punto 2.1-beta3, pero ha seguido siendo la mejora de 2.1-RC1. Los interesados deberán pago de este artículo que vincula a un papel blanco con los detalles técnicos completos.
pero ciertamente no, por lo menos gracias a Andrea Última Aime para la adición de un Web Coverage Service constructor de solicitud, una herramienta práctica para la construcción gráfica peticiones WCS para poner a prueba un servicio de cobertura. Como clientes de WCS ha sido siempre escasa, esta herramienta va un largo camino para hacer el servicio más útil.
Nos complace informar de la contribución de otra traducción de la web de administración especial, gracias a la interfaz de Oscar Fuentes para la presentación de una traducción al catalán y al Geodatos Sistemas para la financiación de la obra.
También es digno de agradecimiento esta ronda es Iván Grcic que ha presentado algunos parches excelentes, incluyendo correcciones de errores para la funcionalidad de capa WMS.
Abrir y compartir sus datos espaciales
GeoServer le permite mostrar la información espacial para el mundo. Aplicación de la Web Map Service (WMS) estándar, GeoServer puede crear mapas en una variedad de formatos de salida. OpenLayers , una colección de mapas gratuitos, está integrada en GeoServer, por lo que la generación de mapas rápida y fácil. GeoServer se basa en GeoTools , un conjunto de herramientas de código abierto de Java GIS.
Hay mucho más para GeoServer de estilo mapas muy bien, sin embargo. GeoServer también se ajusta a la Web Feature Service (WFS) estándar, que permite la participación real y edición de los datos que se utiliza para generar los mapas. Otros pueden incorporar sus datos en sus sitios web y aplicaciones, liberando sus datos y que permita una mayor transparencia.
El uso de software libre y de código abierto
GeoServer es software libre . Esto reduce significativamente las barreras financieras a la entrada en comparación con los tradicionales productos de SIG. Además, no sólo es disponible de forma gratuita, también es de código abierto. Corrección de errores y mejoras de características en el software de código abierto son muy acelerado en comparación con soluciones de software tradicionales. GeoServer Aprovechamiento de la organización también impide que el software de bloqueo-en, el ahorro de costosos contratos de apoyo en el camino.
Se integra con las API de Mapas existentes
GeoServer puede mostrar los datos en cualquiera de las aplicaciones populares, tales como la cartografía de Google Maps ,Google Earth , Yahoo Maps y Microsoft Virtual Earth . Además, GeoServer puede conectar con las tradicionales arquitecturas de SIG como ESRI ArcGIS .
Únase a la comunidad
GeoServer tiene una comunidad vibrante y grande que consiste de usuarios y desarrolladores de todo el mundo. El soporte está disponible a través de una variedad de fuentes, tales como listas de correo electrónico y de IRC (este último con acceso en tiempo real a los desarrolladores de software). Además, apoyo comercial está disponible en una variedad de proveedores.Con GeoServer, tú siempre estás en buena compañía.
Características principales
•
-
- Vector
-
- Shapefiles, CMA externos
- ArcSDE PostGIS, DB2, Oracle Spatial, el servidor MySQL, SQL
-
- Raster
-
- GeoTiff, JPG y PNG (con el archivo de mundo), pirámide de imágenes, en formato GDAL, la imagen del mosaico, Oracle GeoRaster

Implementación de Normas
- Apoyo de numerosas Open Geospatial Consortium (OGC) las normas
- WMS, WFS transaccional, WCS, Filter Encoding, SLD, GML
Base de datos que usa GEOserver
La naturaleza incrustada de H2 la hace ideal para la navegación con GeoServer fuera de la caja. Con soporte completo para transacciones atómicas, H2 es una buena alternativa a los formatos de archivo basados en GML como Shapefile y que no son formatos ideales para los datos que deben someterse a actualizar con frecuencia
H2, base de datos SQL Java. Las principales características de H2 son los siguientes:
* Muy rápido, de código abierto, API de JDBC
* Insertar y los modos de servidor, bases de datos en memoria
* Navegador basado en aplicación de consola
* Tamaño reducido: alrededor de 1 MB de tamaño de archivo jar
Geoserver un diseño de configuración
La configuración basada en Web de documentos de diseño proporciona una serie de objetivos de diseño
para la actualización del GeoServer de configuración del sistema:
- Separar el modelo de configuración de la aplicación GeoServer
- Construir una Struts Interfaz Web en contra de la configuración del modelo
- Permita que la persistencia XML del estado GeoServer de configuración de aplicaciones
- Mantener el formato de archivo de configuración existentes
Para cumplir con estos requisitos, la arquitectura en capas, se propuso 
Éxitos de diseño
El diseño para el sistema de configuración de GeoServer tiene:
- Logrado cumplir nuestros requisitos.
- Ha sucedido en la separación de la aplicación GeoServer, configuración y
subsistemas de la persistencia - Ha sucedido en permitir que las pruebas unitarias de base componentes GeoServer
- Logrado mantener una separación clara entre GeoServer y el
Validación Marco
Extensiones de Diseño
El anterior documento de configuración basada en Web Diseño indica la capa
estructura de la aplicación GeoServer.
La tabla 1 recoge las clases GeoServer tanto por paquete y subsistema (interfaces
están marcados en cursiva):
| GeoTools | Mundial | DTO | Config | Forma |
|---|---|---|---|---|
| Geoserver Póngase en contacto con |
Geoserver Póngase en contacto con DTO |
GeoserverCongfig | GeoserverCongfiguration Formulario | |
| WMS | WMSDTO | WMSConfig | WMSDescriptionForm WMSContent Formulario |
|
| CMA | WFSDTO | WFSConfig | WFSDescriptionForm WFSContent Formulario |
|
| UAB | Datos | DataDTO | DataConfig | |
| NamespaceInfo | NamespaceDTO | NamespaceConfig | DataNamespacesForm | |
| DataStoreInfo | DataStoreInfoDTO | DataStoreInfoConfig | DataDataStoresEditorForm DataDataStoresNewForm DataDataStoresSelectForm |
|
| FeatureTypeInfo | FeatureTypeInfoDTO | FeatureTypeInfoConfig | DataFeatureTypesEditorForm DataFeatureTypesNewForm DataFeatureTypesSelectForm DataAttributeTypesNewForm DataAttributeTypesSelectForm |
|
| Estilos | StyleDTO | StyleConfig | DataStylesFormForm |
Tabla 1 – Datos GeoServer Matrix
El módulo de datos GeoTools se ha ampliado con el catálogo y metadatos
interfaces. El uso de interfaces GeoTools2 por clases en la capa global permite
el procesador de validación para ser escrito de una manera independiente de la aplicación.
1.2.1 Validación de Extensión Marco
La extensión de nuestro diseño para el procesador de validación para dar cabida a una web
interfaz de usuario basada llevó a cabo sin incidentes.
Tabla 2 se enumeran las clases e interfaces de validación por paquete (interfaces
marcados en cursiva):
| Validación | Validación DTO | Config | Forma |
|---|---|---|---|
| ValidationProcessor | ValidationConfig | ||
| PlugIn | PlugInDTO | PlugInConfig | |
| TestSuite | TestSuiteDTO | TestSuiteConfig | ValidationTestSuiteNewForm ValidationTestSuiteSelectForm |
| Validación | TestDTO | TestConfig | ValidationTestEditorForm ValidationTestNewForm ValidationTestSelectForm |
Tabla 2 – Validación de datos del procesador de matriz
Instalación y Configuracion de Geoserver
El presente manual tiene como objetivo, guiar al usuario durante la instalación del servidor Geoserver (v 1.4.0 RC4), sobre el sistema operativo Linux, en la distribución Fedora Core 7.
Requisitos
- Instalar Java JDK, preferentemente un JDK versión 5.0 o superior.
- Instalar contenedor de servlets, preferentemente ApacheTomcat , versión 5.5.20
Procedimiento
- Crear y validar las siguientes variables de ambiente.
Cree el archivo /etc/profile.d/geoserver.sh con el siguiente contenido:$ export GEOSERVER_HOME=/opt/geoserver $ export GEOSERVER_DATA_DIR=$GEOSERVER_HOME/webapps/geoserver/conf $ export PATH=$PATH:$GEOSERVER_HOME/bin
- Descargar el siguiente software:
- geoserver-1.4.0-RC4-war.zip
- geoserver-1.4.0-RC3-oracle-plugin.zip
- Detener el servicio del contenedor de servlets Tomcat.
$ Tomcat stop
- Descomprimir el archivo geoserver-1.4.0-RC4-war.zip en la carpeta que contenga las aplicaciones del contenedor de servlets Tomcat
$ unzip geoserver-1.4.0-RC4-war.zip
- Iniciar Tomcat
$ tomcat start
Al finalizar esto, se habrá creado un directorio con el nombre de geoserver, el cual contiene todos los archivos propios de la aplicación.
Instalación del agregado de Oracle (Oracle plugin).
Para instalar el agregado de Oracle que habilita la compatibilidad con bases de datos de Oracle, será necesario lo siguiente. Descomprimir el contenido del archivo.
unzip geoserver-1.4.0-RC3-oracle-plugin.zip
Esto, crea varios archivos, siendo los más importantes:
- gt2-oracle-spatial-2.2.2-SNAPSHOT.jar
- ojdbc14.jar
Ambos archivos deberán ser movidos al siguiente directorio [directorio del contenedor de servlets]/webapps/geoserver/WEB-INF/lib/ de la siguiente forma:
$mv gt2-oracle-spatial-2.2.2-SNAPSHOT.jar ojdbc14.jar [directorio del contenedor de servlets]/webapps/geoserver/WEB-INF/lib/
Por ultimo hay que reiniciar Tomcat
$ Tomcat restart
Tomcat restart
Configuración post instalación
Posterior a la instalación, se recomienda ampliamente llevar a cabo las siguientes tareas.
Editar los archivos para ejecutar y parar el servicio de geoserver
Agregar la siguiente línea al principio del archivo $GEOSERVER_HOME/bin/startup.sh de tal manera que quede lo siguiente:
#!/bin/sh # -------------------------------------------------------- # Start Script for GEOSERVER # # $Id: startup.sh 4434 2006-05-25 19:22:14Z jdeolive $ # -------------------------------------------------------- GEOSERVER_HOME=/opt/geoserver
Sustituya la siguiente línea del archivo
exec "$_RUNJAVA" -DGEOSERVER_DATA_DIR=$GEOSERVER_DATA_DIR -Djava.awt.headless=true -jar start.jar
Por lo siguiente:
exec "$_RUNJAVA" -DGEOSERVER_DATA_DIR=$GEOSERVER_DATA_DIR -Djava.awt.headless=true -jar start.jar &
Agregue la siguiente línea al archivo $GEOSERVER_HOME/shutdown.sh de tal manera que quede así:
#!/bin/sh
# --------------------------------------------------------------
# Start Script for GEOSERVER
#
# $Id: shutdown.sh 4434 2006-05-25 19:22:14Z jdeolive $
# --------------------------------------------------------------
GEOSERVER_HOME=/opt/geoserver
Sustituya la última línea del archivo anterior
exec "$_RUNJAVA" -jar stop.jar
Por lo siguiente:
exec "$_RUNJAVA" -jar stop.jar --stop &
Para crear el servicio para que oracle que inicie cuando se prenda la computadora, hay que crear el archivo /etc/init.d/geoserver con el siguiente contenido:
#!/bin/sh
#
# chkconfig: 5 99 16
# description: Geoserver
# This init.d script is used to start geoserver
# It just calls $GEOSERVER_HOME/bin/startup.sh or shutdown.sh
export JAVA_HOME=/opt/jdk1.5.0_09
export CATALINA_HOME=/opt/jakarta-tomcat-5.0.30
GEOSERVER_HOME=/opt/geoserver
geoserver_stop() {
$GEOSERVER_HOME/bin/shutdown.sh
}
geoserver_start() {
$GEOSERVER_HOME/bin/startup.sh
}
case $1 in
start)
echo -n "Starting Geoserver server:"
geoserver_start
echo "."
;;
stop)
echo -n "Stopping Geoserver server:"
geoserver_stop
echo "."
;;
reload)
echo -n "Reloading Geoserver server config..."
geoserver_stop
geoserver_start
echo "done."
;;
restart | force-reload)
echo -n "Forcing reload of Geoserver server:"
geoserver_stop
geoserver_start
echo "."
;;
*)
echo "Usage: /etc/init.d/geoserver start|stop|restart|reload|force-reload"
;;
esac
Para agregar el servicio hay que ejecutar los siguientes comandos:
$ cd /etc/init.d $ chmod 750 geoserver $ chkconfig --level 5 geoserver on $ chkconfig --add geoserver $ chkconfig --level 5 geoserver on
Con lo anterior, ahora es posible iniciar y detener el servicio de geoserver de la siguiente forma.
Iniciar el servicio de geoserver
$ /etc/init.d/geoserver start
Detener el servicio de geoserver
$ /etc/init.d/geoserver stop
Ventajas de Geoserver
En el mes próximo lanzaremos Geoserver en Inglés e introducimos el servicio de geo-codificación de direcciones on-line,así como el cálculo de rutas e isócronas en todo el territorio Español. Con este servicio no solamente es más económico el uso de la información geográfica,sino que también ganan los usuarios en flexibilidad.a tambien no usa bloc de notasPantalla Principal del Software
EL FUTURO DE GEOserver
El Geospatial Data es una implementación Java(J2EE) que estara disponible proximamente mente.Es totalmente transaccional de la especificaciónWeb Feature Server y Web Coverage Server del OpenGIS Consortium,con un Web Map Server integradoEstá basado en dos APIs GeoTools:Brinda conectividad a fuentes de datos geográficas heterogeneas(Shapefile,Oracle Spatial,PostGIS entre otras)Utilizada por los proyectos gvSig, GeoAPI, UDig.JTS Topology Suite: Base para la representación de geometría.Usada tambien en los proyectos gvSig y JUMPCon la adición de soporte Xlink a GeoNetwork, otro caso de uso para una mayor integración entre GeoNetwork y GeoServer podría ser el componentizing de registros de metadatos en fragmentos de metadatos proporcionados por un CMA. La motivación para este caso de uso proviene de la necesidad de adaptar GeoNetwork en las organizaciones que ya gestionan metadatos en una o más bases de datos. Se enfoca en la facilidad de uso y soporte para estándares abiertos con el fin de asegurar la interoperabilidad.

MAPSERVER- GIS
Posted by lismabor | Filed under Uncategorized

MapServer es un Código abierto(es un método de desarrollo de software que aprovecha el poder de revisión por pares distribuidos y la transparencia del proceso.) motor de procesamiento de datos geográficos por escrito en C. Más allá de la navegación de datos SIG, MapServer permite crear «mapas de imágenes geográficas», es decir, mapas que pueden dirigir a los usuarios a los contenidos. Por ejemplo, el Minnesota DNR Recreación de Compass proporciona a los usuarios con más de 10.000 páginas web, informes y mapas a través de una sola aplicación. La misma aplicación sirve como un «motor de mapas» para otras partes del sitio, proporcionando contexto espacial donde sea necesario.
MapServer fue desarrollado originalmente por la Universidad de Minnesota (UMN) proyecto ForNet en cooperación con la NASA y el Departamento de Recursos Naturales de Minnesota (MNDNR). Más tarde fue organizada por el proyecto TerraSIP, un proyecto patrocinado por la NASA entre la UMN y un consorcio de intereses de gestión de la tierra.
MapServer es ahora un proyecto de OSGeo que es Creado para apoyar y potenciar la calidad de código abierto más alto de software geoespacial. Nuestro objetivo es fomentar la colaboración y el desarrollo de proyectos de uso de LED-comunidad. , y es mantenido por un número creciente de desarrolladores (punto 20) de todo el mundo. Es apoyado por un grupo diverso de organizaciones que los accesorios de fondos y mantenimiento, y se administra dentro de OSGeo por el MapServer Comié Directivo del Proyecto integrado por los desarrolladores y otros colaboradores.
Avanzada la producción cartográfica
- Escala de dibujo función que depende de la aplicación y ejecución
- Función de etiquetado etiqueta con la mediación de colisión
- Totalmente personalizable plantilla, la producción impulsada
- Fuentes TrueType
- Mapa de automatización de elementos (barra de escala, mapa de referencia, y la leyenda)
- Cartografía temática con clases de expresión de la lógica-o regular
Soporte para secuencias de comandos populares y entornos de desarrollo
- PHP, Python, Perl, Ruby, Java y. NET
Compatibilidad entre plataformas
- Linux, Windows, Mac OS X, Solaris, y más
Habilidades que ofrece MAPSERVER
Además de aprender cómo los diferentes componentes de una aplicación de MapServer trabajan juntos y aprender la sintaxis Mapfile, la creación de una aplicación básica requiere un poco de comprensión conceptual y en varias áreas de habilidades.
¡Tienes que ser capaz de crear o al menos modificar las páginas HTML y comprender cómo las formas de trabajo HTML. Puesto que el propósito principal de una aplicación MapServer es la creación de mapas, que también tendrá que entender los conceptos básicos de información geográfica y proyecciones probable, mapa. Como las aplicaciones se vuelven más complejas, las habilidades en SQL, DHTML / Javascript, Java, bases de datos, expresiones, la compilación, y secuencias de comandos pueden ser muy útiles.
Software

MapServer es un entorno de desarrollo de código abierto para la creación de espacio habilitado para las aplicaciones de Internet. MapServer sobresale en la representación de datos espaciales para la web. MapServer fue desarrollado originalmente por la Universidad de Minnesota (UMN) proyecto ForNet en cooperación con la NASA y el Departamento de Recursos Naturales de Minnesota (MNDNR). En la actualidad, el proyecto es auspiciado por el proyecto TerraSIP, un proyecto patrocinado por la NASA entre NMS y un consorcio de intereses de gestión de la tierra. El software es mantenido por un número creciente de desarrolladores. Para obtener más información, visite el sitio web de la Universidad de Minnesota en http://mapserver.gis.umn.edu/ , o comuníquese con el Sr. Stephen cal.
Requisitos de hardware
MapServer se ejecuta en Linux, Windows, Mac OS X, Solaris, y más. Para compilar o instalar algunos de los programas necesarios es necesario que tenga derechos de administrador en la máquina.
Requisitos de software
Se necesita que esté trabajando y configurado correctamente el servidor HTTP (web), como Apache o Microsoft Internet Information Server, en el equipo en el que va a instalar MapServer. OSGeo4W contiene Apache ya, pero se puede configurar de nuevo las cosas para usar IIS si es necesario. Por otra parte, ms4w se puede utilizar para instalar MapServer en Windows.
Si es que se está en una máquina Windows, y no se tiene instalado un servidor HTTP, es posible que desee comprobar ms4w, se instalará un pre-configurado del servidor HTTP, MapServer, y mucho más. El FGS Linux Installer proporciona una funcionalidad similar para varias distribuciones de Linux.
También se necesitará un navegador Web, y un editor de texto (vi, emacs, bloc de notepad, homesite), para modificar el código HTML y mapfiles.
SISTEMA DE MAPSERVER
 Hoy en día, Sistema de Información Geográfica (SIG) es una herramienta generalizada de que el apoyo y se utiliza en miles de proyectos. Se compone de dos tipos importantes de datos que son de datos espaciales y datos de atributos para el que se crea Mapsever. Mapserver bases del sistema en tecnología web y tiene el deber de servidor. Se sirve y mantiene la integridad de cientos de miles de registros de datos, al tiempo que permite actualizaciones simultáneas y consultas. Y transfiere los datos, cuando petición de los clientes que tienen un programa navegador web. Los datos del mapa es el envío de datos por Mapserver que tiene básicamente dos métodos para la transferencia: como vector o como mapas de bits.
Hoy en día, Sistema de Información Geográfica (SIG) es una herramienta generalizada de que el apoyo y se utiliza en miles de proyectos. Se compone de dos tipos importantes de datos que son de datos espaciales y datos de atributos para el que se crea Mapsever. Mapserver bases del sistema en tecnología web y tiene el deber de servidor. Se sirve y mantiene la integridad de cientos de miles de registros de datos, al tiempo que permite actualizaciones simultáneas y consultas. Y transfiere los datos, cuando petición de los clientes que tienen un programa navegador web. Los datos del mapa es el envío de datos por Mapserver que tiene básicamente dos métodos para la transferencia: como vector o como mapas de bits.

FUNCIONAMIENTO DE PROGRAMA
Su funcionamiento básico está configurado en un fichero de texto, que generalmente tiene la extensión «.map». En este fichero, los datos del mapa se organizan en capas, a su vez dividida en una o más clases, donde en cada una de las cuales se pueden definir diferentes estilos visuales. Esta estructura permite la generación de mapas con una definición de estilos muy flexible, que también puede depender de la escala del mapa.
El formato de salida de MapServer, es dependiendo de la solicitud, puede ser gráfico (mapa, leyenda, escala, métricas, visión general) o alfanumérico (el resultado de una consulta de datos alfanuméricos o espacial). El archivo «.map» también incluye la posibilidad de fusionar la producción de una plantilla de HTML MapServer, para generar una página web de lectura fácil y agradable.
USO COMO SERVIDOR DE MAPAS
La posibilidad de ser utilizado como servidor de mapas por terceros programas, siguiendo las especificaciones OGC, o bien mediante la API MapScript, ha llevado a la creación de aplicaciones web basadas en MapServer, para la publicación de datos geoespaciales:
•CartoWeb
•Ka-Map
•Chameleon
•Pmapper
ESTRUCTURA BASICA DE LA APLICACION DE MAPSERVER
Una aplicación MapServer simple consiste en:
• Map File – es un archivo de configuración de texto estructurado para su aplicación MapServer. Este define el área de su mapa, le dice al programa MapServer dónde están sus datos y donde colocar las imágenes. También define las capas del mapa, incluyendo su fuente de datos, proyecciones y simbología. Se debe tener una extensión .map o MapServer no lo reconocerá.
• Datos Geográficos – MapServer puede utilizar muchos tipos fuente de datos geográficos. El formato es el archivo de forma ESRI..
• Páginas HTML – Es la interfaz entre el usuario y MapServer. Por lo general se asientan en la raíz Web. En su forma más simple, MapServer se puede llamar para colocar una imagen de mapa estático en una página HTML. Para que el mapa sea interactivo, la imagen se coloca de forma HTML en una página.

Anatomía de una aplicación MapServer

La arquitectura básica de las solicitudes de MapServer.
Una aplicación MapServer simple consiste en:
- Mapa de archivos – un archivo de texto estructurado de configuración para su aplicación MapServer. Se define el área de su mapa, le dice al programa MapServer dónde están sus datos y donde a las imágenes de la salida. También define las capas del mapa, incluyendo su fuente de datos, proyecciones y simbología. Se debe tener una extensión del mapa. MapServer o no lo reconocerá.
Datos Geográficos – MapServer pueden utilizar muchos tipos de datos de origen geográfico. El formato por defecto es el archivo de forma ESRI. Muchos otros formatos de datos pueden ser apoyadas, esto se discute más adelante en la Adición de datos a su sitio .
Páginas HTML – la interfaz entre el usuario y MapServer. Por lo general se siente en la raíz Web. En su forma más simple, MapServer se puede llamar para colocar una imagen de mapa estático en una página HTML.Para que el mapa interactivo, la imagen se coloca en un formulario HTML en una página.
CGI programas son «apátridas», todas las solicitudes que reciben es nueva y no recuerdo nada sobre la última vez que se vieron afectados por su aplicación. Por esta razón, cada vez que su aplicación envía una solicitud para MapServer, tiene que pasar la información de contexto (lo que se encuentran en capas, donde está en el mapa, el modo de aplicación, etc) en las variables de forma oculta o variables de URL.
Un simple MapServer CGI solicitud se podrán incluir dos páginas html:
- Archivo de inicialización – utiliza un formulario con variables ocultas para enviar una consulta inicial con el servidor http y MapServer. Esta forma puede ser colocado en otra página o se sustituye por pasar la información de inicialización como variables en una URL.
- Archivo de plantilla – controla la forma en los mapas y la salida de las leyendas de MapServer aparecerá en el navegador. Al hacer referencia a las variables CGI MapServer en el html de plantilla, que permiten MapServer para rellenar con los valores relacionados con el estado actual de su solicitud (nombre de la imagen del mapa, por ejemplo, nombre de la imagen de referencia, la extensión del mapa, etc), ya que crea la página html para el navegador para leer. La plantilla también determina la forma en que el usuario puede interactuar con la aplicación MapServer (navegar, zoom, pan, consulta).
- MapServer CGI – El archivo binario o ejecutable que recibe las peticiones y devuelve las imágenes, datos, etc se encuentra en el directorio cgi-bin o directorio de scripts del servidor http. El usuario del servidor web debe tener derechos de ejecución para el directorio que se siente, y por razones de seguridad, no debe estar en la raíz web. De forma predeterminada, este programa se llama mapserv
- HTTP Server – sirve las páginas HTML cuando son golpeados por el navegador del usuario. Se necesita un trabajo HTTP (web) del servidor, como Apache o Microsoft Internet Information Server, en el equipo en el que va a instalar MapServer.
MAPSERVER EN GENERAL

. Consulta la web del servidor a través de una URL que contiene la dirección del programa con MapServer
ajustes adecuados,
2. El servidor transmite a los parámetros de consulta de MapServer,
3. MapServer y decodifica la configuración se encuentra la información que se encuentra en el archivo de proyecto «mapfile».
Estas son, posiblemente, modificado de acuerdo a los parámetros pasados en la solicitud,
4. MapServer buscará los elementos del mapa para visualizar,
5. MapServer búsquedas relacionadas no geográficos (es decir, hallar los datos correspondientes
consultas)
6. MapServer lee la plantilla de página HTML para generar (plantilla) y los valores de los parámetros sin marcar
7. MapServer consiste en imágenes de mapa de bits a partir de diferentes fuentes de datos y parámetros. La
imágenes de las Listas (escaleras, las referencias, las capas visibles) se componen,
8. MapServer el resultado de la página HTML
9. MapServer envía la página al servidor Web,
10. El servidor web devuelve la página al cliente.Este servidor de mapas, desarrollado en C, tiene las siguientes características
- OpenSource y robustez
- cumple con las especificaciones del OGC servicios web para WMS (Web Map Service) y CMA (Web Feature Service).
- interfaz con muchos lenguajes de programación: PHP (phpmapscript módulo), Python, Perl, Java, etc.
El siguiente diagrama muestra la arquitectura propuesta por el SIL MapServer


SAGA SIG
Posted by lismabor | Filed under Uncategorized

INTRODUCCION
Cuando la tecnología S.I.G. surgió a través de las primeras etapas del desarrollo de la Geografía cuantitativa (utilización de métodos y técnicas matemáticas) y los desarrollos decisivos de la cartografía y el análisis cartográfico (Mc Hairg ensaya para la planificación territorial la superposición de mapas analógicos) difícilmente se podía pensar que en tan poco tiempo (años 60 fase de desarrollo, años 70 fase de resolución a los problemas técnicos, años 80 y 90 fase de comercialización ) se pudieran utilizar dichos software para las actuales aplicaciones de los Sistemas de Información Geográfica.
Un SIG (Sistema de Información Geográfica), es de los diversos software que existen en el mercado (su potencia, sus cualidades, tipo de software) y en conjunto, para que proyectos son más adecuados. Todos hemos leído diferentes proyectos y las diversas aplicaciones que puede tener uno u otro software; igualmente, somos conscientes del desarrollo tecnológico de cada software y su evolución a lo largo de los años para poder aportar soluciones a los nuevos planteamientos (sistemas abiertos, interfaces sencillos, fácil manejo, potencia de trabajo, conexiones a internet, consultas simples a bases de datos externas, velocidad, compatibilidad con otros sistemas software.
Los nuevos retos tecnológicos van íntimamente ligados a las nuevas aplicaciones SIG y cada día nos sorprende menos una nueva aplicación (arqueología, biología, medicina…) Este continuo desarrollo de aplicaciones unido a las ya existentes genera una cierta confusión a todo aquel que se inicia en esta tecnología, por ello, en este artículo intento plasmar las aplicaciones más comunes junto con ejemplos de algunos proyectos, sabiendo de antemano que me dejo infinidad de actuales y futuras aplicaciones.
HISTORIA DE SAGA
J. Böhner y Conrad O. , ambos están ahora trabajando en el Instituto de Geografía de la Universidad de Hamburgo , Alemania.
La idea para el desarrollo de SAGA evolucionó a finales de 1990 durante los trabajos de varios proyectos de investigación en el Departamento de Geografía Física , Göttingen . Un enfoque de la investigación fue el análisis de datos de trama , en particular de Modelos Digitales de Elevación ( DEM), que se han utilizado por ejemplo para predecir las propiedades del suelo , el terreno dinámica de procesos controlados , así como los parámetros climáticos .
Para ello era necesario el desarrollo e implementación de muchos nuevos métodos para el análisis espacial y la modelización.
El grupo central responsable del desarrollo de métodos, eran, J. Böhner , Conrad O. , Köthe R. y A. Ringeler , era muy heterogéneo en lo que respecta a los sistemas operativos preferidos , lenguajes de programación , entornos de desarrollo , formatos de datos y así sucesivamente , de modo que una plataforma común de desarrollo con soporte integrado para el análisis de datos geográficos que prometía ser una importante mejora para todo el equipo . Y porque no había plataforma de desarrollo que cumplan realmente disponible en ese momento, se ha creado SAGA . que una plataforma común de desarrollo con soporte integrado para el análisis de datos geográficos que prometía ser una importante mejora para todo el equipo. porque no había plataforma de desarrollo que cumplan realmente disponible en ese momento.
De secundarios se tomó un tiempo hasta que una versión utilizable primero se había preparado, pero desde ese momento el sistema ha sido mejorado. Después de muchas discusiones uno ha tomado la decisión de publicar SAGA como Free Open Source Software y compartir sus capacidades con la ventaja de todo el mundo geocientíficos.
Desde entonces SAGA tiene cada vez mayor en todo el mundo una comunidad de usuarios, que también dio lugar a numerosas contribuciones desde el exterior del equipo principal de desarrolladores.
Con el fin de permitir a largo plazo el desarrollo sostenible que abarca toda la gama de intereses de los usuarios, la Asociación Grupo de Usuarios de SAGA , una organización sin fines de lucro , fue fundada en mayo de 2005. Una de sus tareas es la organización de reuniones de grupos de usuarios, de los cuales el primero internacional tuvo lugar en julio de 2006 en el marco de la Conferencia y Exposición sobre Geomática Aplicada, AGIT en Salzburgo , Austria.
SAGA GIS
SAGA (Sistema para Análisis Automatizados Geocientíficos ) es un software híbrido de información geográfica. Desarrollado por el Departamento de Geografía Física , Göttingen (Alemania ) sólo unos 10 MB de espacio en disco . No requiere instalación. SAGA GIS puede ser usado junto con otros programas de SIG como Kosmo para obtener mejores datos vectoriales y de mapa con capacidad de producir.
SAGA es un Free Open Source Software (FOSS), que por lo general significa que se tiene la libertad para ejecutar el programa con cualquier propósito de estudiar cómo funciona el programa y modificarlo, de distribuir copias, para mejorar el programa y hacer públicas las mejoras para el usuario.

CARACTERISTICAS
- SAGA ha sido diseñado para una fácil y eficaz aplicación de algoritmos espaciales.
- SAGA ofrece una amplia, creciente conjunto de métodos geocientíficos.
- SAGA proporciona una interfaz de usuario accesible fácilmente con muchas opciones de visualización.
- SAGA se ejecuta bajo Windows y sistemas operativos Linux se ejecuta bajo Windows y sistemas operativos
- Programado en C++ permite desarrollar módulos propios o modificar su API en función de las necesidades.
- Soportar datos vectoriales provenientes de los formatos más conocidos
- Simula procesos dinámicos.
- Posee herramientas para el manejo de grids.
- Permite realizar análisis geoestadísticos.
- Reclasificación de imágenes.
- Herramientas vectoriales.
- Puede ser usado junto con otros programas de SIG como kosmos para obtener mejores datos vectoriales y de mapa con capacidad de producir.
- Sólo ocupa unos 10 MB de espacio en disco.
SOFTWARE
El primer objetivo de SAGA es dar (geo -) los científicos pueden aprender una sencilla pero eficaz plataforma para la implementación de métodos geocientíficos .
Esto se logra mediante la única interfaz de programación de aplicaciones SAGA (API ) .

El segundo es hacer estos métodos accesibles de una manera fácil. Esto se consigue principalmente mediante su interfaz gráfica de usuario (GUI) Juntos, API Y GUI son el verdadero potencial de SAGA: un sistema cada vez mayor y rápido de métodos.

Interfaz Grafica de Usuario
La interfaz gráfica de usuario permite al usuario gestionar y visualizar los datos, así como para realizar análisis de datos y la manipulación mediante la ejecución de los módulos. Además del menú, de herramientas y barras de estado , que son típicos para la mayoría de los programas modernos , SAGA interfaces al usuario con tres elementos de control adicionales.
El control de área de trabajo tiene ventanas sub para los módulos, los datos de mapas y espacios de trabajo . Cada área de trabajo muestra una vista en árbol, a través del cual los objetos asociados área de trabajo se puede acceder.
")
Un módulo se puede ejecutar ya sea por un botón en la ventana de configuración relacionados oa través de una entrada de menú aparece en la lista de módulos de la barra de menús. La ubicación exacta de la entrada del menú se ha especificado por el programador del módulo, por lo que un procedimiento de geoestadística, como ‘Universal Kriging «debe encontrarse en» Geoestadística «la categoría sub. Antes de que un módulo se ejecuta, los parámetros de entrada obligatoria, es decir, los datos a analizar, se deben establecer. Después de llamar a un módulo a través de su entrada en el menú, un cuadro de diálogo aparece, donde esto se puede hacer (Fig. 20). Después de confirmar, que los parámetros se han ajustado correctamente, se inicia el módulo de ejecución real. Información sobre el progreso se da en la barra de estado y las ventanas de notificación de mensajes. La ejecución del módulo se puede detener por el usuario pulsando la tecla de escape, o usando el menú de módulos. Pero no todos los módulos de iniciar su cálculo inmediato. módulos interactivos esperar a la entrada del usuario, por lo general por los clics del ratón en una ventana del mapa, para realizar una acción. Para ello el modo de ratón habrá de ajustarse, por ejemplo, de captura o sartén de modo en el modo interactivo.La mayoría de los módulos de creación de nuevos conjuntos de datos como resultado de su cálculo, que se agregará automáticamente al área de trabajo de datos, para que estos se pueden guardar, utilizar como entrada para los cálculos posteriores, o que aparecen en un mapa.
 La manera estándar de visualización de datos espaciales es el mapa cartográfico. Cada conjunto de datos espaciales se pueden añadir a un mapa como capa temática. órdenes de visualización de capas temáticas se cambian en el espacio de trabajo de los mapas. En dependencia del tipo de datos diferentes opciones de visualización están disponibles para la creación de mapas expresiva. valores de los atributos de los datos vectoriales se pueden utilizar como etiquetas, para determinar los tamaños de los símbolos punto o anchos de línea, o para indicar colores de la pantalla. los datos de mapa de bits son de color de acuerdo a sus valores de datos, ya sea mediante el uso de una tabla de búsqueda o un esquema de clasificación métricas. Un valor de transparencia permite utilizar datos de la trama de efectos de sombreado. Apariencia lisa cuando el zoom se consigue mediante interpolación valor opcional. puntos de vista en 3D pueden ser fácilmente creados para cada mapa, por lo que los datos adecuados de elevación se han cargado. Vector, así como datos de la trama se pueden editar directamente en las vistas de mapa. Otras posibilidades para la visualización de datos son histogramas y gráficos de dispersión. Gráficos de dispersión se han construido en función de regresión y se puede aplicar a los datos vectoriales, raster y tabla. Además de las vistas de tabla simple con capacidades de edición y clasificación, también diagramas están disponibles para mostrar datos de la tabla.
La manera estándar de visualización de datos espaciales es el mapa cartográfico. Cada conjunto de datos espaciales se pueden añadir a un mapa como capa temática. órdenes de visualización de capas temáticas se cambian en el espacio de trabajo de los mapas. En dependencia del tipo de datos diferentes opciones de visualización están disponibles para la creación de mapas expresiva. valores de los atributos de los datos vectoriales se pueden utilizar como etiquetas, para determinar los tamaños de los símbolos punto o anchos de línea, o para indicar colores de la pantalla. los datos de mapa de bits son de color de acuerdo a sus valores de datos, ya sea mediante el uso de una tabla de búsqueda o un esquema de clasificación métricas. Un valor de transparencia permite utilizar datos de la trama de efectos de sombreado. Apariencia lisa cuando el zoom se consigue mediante interpolación valor opcional. puntos de vista en 3D pueden ser fácilmente creados para cada mapa, por lo que los datos adecuados de elevación se han cargado. Vector, así como datos de la trama se pueden editar directamente en las vistas de mapa. Otras posibilidades para la visualización de datos son histogramas y gráficos de dispersión. Gráficos de dispersión se han construido en función de regresión y se puede aplicar a los datos vectoriales, raster y tabla. Además de las vistas de tabla simple con capacidades de edición y clasificación, también diagramas están disponibles para mostrar datos de la tabla.Módulos
SAGA viene con un conjunto completo de módulos gratuitos , la mayoría de ellos publicados bajo la GPL (34 bibliotecas con 119 módulos en la versión 1.2 , 42 bibliotecas con 234 módulos en la versión 2.0.0 , 48 bibliotecas con 300 módulos en la versión 2.0.3) .. No todos estos módulos son sofisticados análisis de alta o herramientas de modelado . Muchos módulos de datos realizar operaciones simples en lugar . Sin embargo, varios de estos módulos representan el estado de la técnica en el análisis de ciencias de la tierra . El siguiente resumen muestra la gama de métodos cubiertos. Sin embargo, varios de estos módulos representan el estado de la técnica en el análisis de ciencias de la tierra.

CONJUNTO DE DATOS ESPACIALES
Fundamentales para el trabajo con los datos espaciales son interfaces para los formatos de archivo innumerables . En particular, el intercambio de datos entre diferentes programas por lo general requiere un conjunto de filtros de importación y exportación. SAGA ofrece varios filtros a los formatos de datos comunes , incluyendo la imagen y varios formatos de GPS.

PROYECCION
Para que todos los conjuntos de datos espaciales de un proyecto pertenecen a un único sistema de coordenadas. Además de una herramienta de georreferenciación , SAGA proporciona acceso a las dos cartográfica libre Una vez los datos hayan sido importados, el siguiente paso necesario en la mayoría de los casos para georeferenciar o para para que todos los conjuntos de datos espaciales de proyecto pertenecen a sistema de coordenadas. Además de una herramienta de georreferenciación, SAGA proporciona acceso a las dos bibliotecas de proyección, elGeográfica Traductor GeoTrans colección desarrollada por la National Geospatial Intelligence Agency y la proj.4 la colección iniciada por el Servicio Geológico de EE.UU. Ambos funcionan las bibliotecas de trama , así como para los datos vectoriales y proporcionar de forma gratuita diversas proyecciones cartográficas parámetros definibles.

|
ANALISIS DE DATOS VECTORIAL Existen muchos módulos para la manipulación y análisis de datos vectoriales , como la fusión de capas , la selección de formas, la manipulación de atributos de tabla, conversión de tipos y la creación de documentos automatizados. Existen muchos para la manipulación análisis de datos vectoriales, como la fusión de capas, la selección de formas, la manipulaciónde atributos de tabla, conversión de tipos la creación de documentos operaciones estándar en los datos vectoriales son intersecciones capa de polígonos y los datos de creación de vectores de datos de trama , por ejemplo, creación de líneas de contorno en los datos vectoriales son polígonos y los datos creación vectores datos trama, por ejemplo, creación líneas contorno
de datos puede ser creada desde el punto utilizando el vecino más próximo , la triangulación y otras técnicas de interpolación . raster) de datos puede ser creada desde el punto el vecino más próximo, la triangulación y otras técnicas de interpolación. Módulos para la construcción y preparación de datos raster, permita que el nuevo muestreo , el cierre de las lagunas y la manipulación del valor por el usuario las reglas definidas . Módulos para la construcción y preparación de datos raster, permita que el nuevo muestreo,el cierre de las lagunas yla manipulación del valor por el usuario las reglas definidas. Los análisis de datos imagen de la cubierta, entre otros, y patrón de análisis de costos.
|





{kind=link}
{kind=link}
KOSMO GIS
Posted by lismabor | Filed under Uncategorized
Primero vamos hacer una introduccion de Que es un GIS?
")
Componentes de un GIS
Los elementos básico de un sistema de estas característica son:
Serie de DATOS y base de datos.
SOFTWARE, relacionado con un sistema de gestión.
HARDWARE: procesador, periféricos
Equipo HUMANO
PROCEDIMIENTOS: modelo de negocio

Kosmo es un sistema de información geográfica (SIG) de escritorio de funcionalidades avanzadas. Es el primer componente de una serie de desarrollos que están en marcha y que, a partir de ahora, irán siendo puestos a disposición de toda la comunidad.
Características
-Kosmo ha sido implementado usando el lenguaje de programación Java.
-Desarrollado a partir de la plataforma JUMP y de una larga serie de bibliotecas de código libre
-Se trata de una herramienta capaz de visualizar y procesar datos espaciales.
-se caracteriza por poseer una interfaz de usuario amigable.
-Tener la capacidad de acceder a múltiples formatos de datos, tanto vectoriales, como ráster.
-Posibilidad de ampliar su funcionalidad en base a extensiones.
-El idioma principal en el que se desarrolla Kosmo es el español, estando también disponible en inglés, portugués, ruso, italiano y alemán.
BASES DE DATOS
Kosmo puede conectarse al siguiente servidor de bases de datos: MySQL a partir de la version 4.1.
Postgresql con extensión de PostGis y Oracle con la extensión LOCATOR/SPATIAL instalada.
")

Sistema Operativo en la que se puede instalar
Esta disponible para los sistema operativos windows y linux
")
REQUERIMIENTO PREVIOS A LA INSTALACIÓN
La aplicación Kosmo requiere de la instalación previa de la máquina virtual JAVA, version 1.4.2 o superior.
")
El proyecto Kosmo es la primera plataforma SIG libre corporativo, distribuida bajo la licencia GNU/GP.
En él se hace uso intensivo y se desarrollan o integran las herramientas necesarias para satisfacer la necesidades de la mayoría de los usuarios, y para ello se implementa:
Kosmo Server: Servidor de Cartografía raster y vectorial
Kosmo Desktop: SIG de escritorio con potente capacidad de consulta, edición y análisis
Kosmo Cliente Ligero: Navegador cartográfico para conexión con Servicios basados en estándares OGC
Kosmo Móvil: Software SIG para dispositivos móviles.
Kosmo Desktop
v Desde la fecha de liberación de la primera versión estable, en abril de 2006, de Kosmo Desktop, la evolución ha sido continua y creciente. La próxima version que se está preparando incluirá una serie conceptos, utilidades y posibilidades.
v Un aspecto diferenciador de Kosmo-Desktop es su diseño, muy orientado en cuanto a funcionalidades a las necesidades reales y más habituales de usuarios. El «qué debe tener» y el «cómo debe presentarse al usuario» se diseñan desde el punto de vista de los usuarios.
Kosmo-Desktop hace uso de elementos de otros proyectos como:
v Geotools: biblioteca de base para multitud de utilidades.
v Castor: biblioteca Java que permite serializar objetos Java en XML. En Kosmo nos permite guardar y recuperar los objetos del proyecto.
v Ermapper: biblioteca gratuita para trabajar con ficheros en formato ECW.
v GDAL
v Log4J: Permite crear un registro de las operaciones que lleva a cabo la aplicación.
Kosmo y Sextante
En el año 2008 se iniciaron las tareas necesarias para incorporar Sextante como extensión de Kosmo – Desktop. Sextante es una librería de software libre que implementa algoritmos de análisis geoespacial publicada con licencia GPL que se puede utilizar en otros conocidos clientes de escritorio OpenSource.
")
INTEL vs. AMD
Posted by lismabor | Filed under Uncategorized

Vamos hablar sobre dos empresas de primer nivel, con muy alta calidad.
 pero antes vamos hablar de cada uno de ellos
pero antes vamos hablar de cada uno de ellos

Pasado
Fue fundada por Gordon E. Moore y Robert Noyce en 1969. Inicialmente quisieron llamar a la empresa Moore Noyce, pero sonaba mal, por lo que eligieron como nombre las siglas de Integrated Electronic, en español Electrónica Integrada. La compañía comenzó fabricando memorias antes de dar el salto a los microprocesadores. Hasta los años 70 fueron lideres gracias al competitivo mercado de las memorias DRAM, SRAM y ROM.


Gordon E. Moore Robert Noyce
se fundó en 1.968 en Santa Clara (California).
Es la primera empresa productora de microprocesadores para ordenadores del mundo, si bien sus diferencias han bajado en los últimos años (llegó a ser del 85% en 1.995) con respecto a AMD.
Comparte el honor, junto con Texas Instruments (los expertos no se ponen totalmente de acuerdo sobre este punto) de ser el creador del primer microprocesador del tipo x86 para ordenadores, en 1.971.
De todos es conocida la trayectoria de INTEL como creador y fabricante de microprocesadores.
Hagamos una reseña de los principales micros.
1971.- Intel 4004. Fue el primer microprocesador comercial, salió al mercado el 15 de noviembre de 1971.
1974.- Intel 8008.
1978.- Intel 8086.
1979.- Intel 8088.
1982.- Intel 80286.
1985.- Intel 80386, AMD 386.
1989.- Intel 80486, AMD 486.
1993.- Intel Pentium, AMD K5.
1995.- Intel Pentium Pro.
1997.- Intel Pentium II, AMD K6.
1999.- Intel Pentium III, AMD K6-2.
2000.- Intel Pentium 4, Intel Itanium 2, AMD Athlon XP, AMD Duron.
2004.- Intel Pentium M.
2005.- Intel Pentium D, Intel Extreme Edition con hyper threading, Intel Core Duo, AMD Athlon 64, AMD Athlon FX.
2006.- Intel Core 2 Duo, Intel Core 2 Extreme, AMD Athlon 64 X2.
2007.- Intel Core 2 Quad, AMD Quad Core.
En el año 2.005 llegó a un acuerdo con Apple para suministrar microprocesadores P-4 para los nuevos Mac.
INTEL tiene registradas más de 300 patentes de componentes relacionadas con el mundo de los ordenadores, entre las que están el bus PCI, AGP, USB y PCIexpress.
INTEL tiene fábricas repartidas por el sudeste asiático y Filipinas.
AMD (Advanced Micro Devices) se fundó en 1.969 en Sunnyvale (California).
Es la segunda empresa productora de microprocesadores para ordenadores, por detrás de INTEL.
En el año 1.982 firma un acuerdo con INTEL que duraría hasta 1.986, y que le permitía fabricar microprocesadores basados en la tecnología INTEL. Este acuerdo se rompió con la irrupción en el mercado de los ordenadores ”clónicos” y la cada vez menor dependencia de las exigencias de IBM en cuanto a las características que debían tener los microprocesadores. Esto llevó a ambas compañías a una larga lucha legal por la ruptura de este acuerdo, siendo esta favorable a AMD en la inmensa mayoría de las ocasiones, lo que le permitió seguir fabricando microprocesadores basados en x86.
En 1.994 firman un nuevo acuerdo que permite a AMD fabricar microprocesadores basados en 285, 386 y 486.
Hasta ese momento, AMD no es más que un fabricante de microprocesadores con tecnología de terceros (en este caso INTEL), pero con unos costos menores, lo que la hizo popular en muchos mercados.
En 1.995 saca al mercado la serie K (el K5), que es el primer microprocesador desarrollado íntegramente por AMD, para competir con los Pentium de INTEL.
Posteriormente lanzaría los K6 (1.997) y K6-2 (1.999) para competir con los nuevos P-II y P-III de INTEL. Estos procesadores utilizan parte de la arquitectura RISC, lo que hace que a menor velocidad de reloj las prestaciones sean superiores a las de INTEL.
En 2.000 lanza al mercado los K7 (Athlon), para entrar en competencia directa con los P4 de INTEL. AMD adoptó el sistema de nombrar a sus microprocesadores por su equivalente en rendimiento a INTEL P4, no por su velocidad real.
Una cuestión muy importante para considerar el rendimiento de los AMD es que no son compatibles con los chipset de INTEL. Esto hizo que al principio dieran muchos problemas (sobre todo los K5) tanto de rendimiento como de fiabilidad, dependiendo sobre todo de la calidad de la placa base utilizada. No obstante a medida que fabricantes de chipset como VIA y SiS fueron desarrollando chips para estos sistemas fue aumentando tanto su rendimiento final como su fiabilidad. De hecho, VIA se ha convertido en el principal suministrador de chipset, tanto para placas basadas en AMD como en placas basadas en INTEL (después, en este caso, de la propia INTEL).
En el año 2.003 compró Geode (la antigua Cyrix), lo que propició que en 2.004 AMD sacara la gama GEODE de microprocesadores de bajo consumo para equipos integrados.
Es el mayor productor mundial de chips para TV, consolas y móviles
Tiene fábricas en Singapur y en Dresden (Alemania).
")
Tanto AMD como INTEL tienen una gama lo suficientemente amplia como para satisfacer cualquier necesidad. Desde procesadores de bajo costo y un solo núcleo, aunque compatibles en ambos casos con 64bits y velocidades de más de 3Ghz (Sempron de AMD y Celeron D en el caso de INTEL) hasta procesadores de doble núcleo y procesadores para servidores de doble núcleo y cuádruple nucleo (AMD Opteron e INTEL Xeon), pasando por la gama específica de bajo consumo para portátiles (Turion en AMD y serie M o Mobile en INTEL). En este tutorial nos vamos a centrar en los microprocesadores para ordenadores de sobremesa.
Vamos a analizar las opciones que tenemos. Lo primero que vemos es un exceso de oferta (26 en el caso de AMD y 51 en el caso de INTEL), a lo que hay que añadir en el caso de AMD 5 microprocesadores Sempron con socket 754 (para ensambladores de PC de bajo costo) y 4 Athlon XP64 con socket 939 y en el caso de INTEL un mayor número de series de producción (Celeron D, Pentium D, Extreme Edition, Core 2 Duo, Core 2 Duo Extreme Edition). Esto hace que la gama de posibilidades sea muy amplia en ambas marcas, pero también que sea cada vez más difícil para el usuario saber cuál es el procesador que necesita.
Antes de continuar quisiera hablar de un mito que se mantiene y que en la actualidad no es real en absoluto, siendo además una de las razones que muchos argumentan en contra de AMD.
Los micros de AMD se calientan mucho más que los de INTEL . Esto era muy cierto en los K5 y K6, hasta el punto de incorporar una chapa disipadora en el micro, y cierto en los primeros K7. Dejó de ser cierto con la salida de los Athlon XP, que trabajan prácticamente a la misma temperatura que los INTEL y es falso con los nuevos procesadores XP64 de un núcleo y de doble núcleo, que trabajan a las mismas temperaturas que los INTEL, con una temperatura de trabajo en el caso de los X2 de 65w de entre 28º y 35º, superando solo cuando se les exige un gran rendimiento (y consumo) los 40º-45º. De hecho, el procesador que más problemas de temperatura da en la historia reciente (los K5 y K6 son de los años 90) no es AMD, sino Intel, y se trata de los P4 con núcleo Prescott (los últimos 478 y primeros 775 de un solo núcleo), sobre todo cuando sobrepasan los 2.6Mhzl.
CARACTERISTICAS PRINCIPALES DE CADA FABRICANTE.
AMD
La principal característica de los procesadores AMD de un solo núcleo es que, gracias a su tecnología, consigue unos rendimientos similares a los de INTEL, pero con una velocidad de reloj bastante menor y con una memoria caché también menor. La proporción en el rendimiento y la velocidad de reloj esta aprox. en 1:1.60. Esto quiere decir que para obtener el rendimiento de un P4 a 3800Mhz, un Athlon XP64 3800+ trabaja a 2400Mhz. Esto ha motivado que, por razones comerciales, AMD denomine sus micros en relación a su rendimiento comparado con INTEL, no por su velocidad real de reloj. Tienen también una mayor velocidad FSB (entre los 1600Mhz de los Sempron y los 2000Mhz del resto de la gama, frente a los 1066Mhz de los INTEL de mayor velocidad) y una característica muy importante, y es que la memoria RAM está gestionada directamente por el microprocesador, y no por el NorthBridge, lo que hace que tanto la utilización como el acceso y la gestión de esta sea más rápido que en el caso de INTEL.
Esto supone una cierta ventaja en los procesadores de un solo núcleo, pero… ¿lo es también para los de doble núcleo?. Pues la verdad es que no tanto, aunque en velocidad de acceso a la RAM y en ancho de banda siguen siendo bastante superiores. En los procesadores del tipo Dual Core, AMD se ve penalizada por su menor memoria caché, sobre todo en aplicaciones que hacen mucho uso de esta. Al final veremos algunos resultados basados en tests Benchmark.
La gama de AMD consta de las siguientes familias:**
**Datos extraídos de la web de AMD (www.amd.com)
Athlon 64 (un núcleo).
3500+, 3800+ y 4000+, con una frecuencia de reloj de 2.2Ghz, 2.4Ghz y 2.6Ghz y una caché L1 de 128KB (64KB para instrucciones y 64KB para datos) y L2 de 512 a 1MB y 2000FSB
Athlon 64 x2 (doble núcleo).
3600+ a 6400+, con una frecuencia de reloj de entre 1.9Ghz y 3.2Ghz x núcleo, y una caché L1 de 128KB (64KB para instrucciones y 64KB para datos) y L2 de 512KB a 1MB x núcleo y 2000 FSB
Athlon Phenom (4 núcleos)
9500 y 9600, con una frecuencia de reloj de 2.2Ghz y 2.3Ghz x núcleo respectivamente, y una caché L1 de 128KB (64KB para instrucciones y 64KB para datos) y L2 de 512KB a 1MB x núcleo y 2000 FSB. Llevan además una caché L3 de 2MB compartida para los cuatro núcleos. Utilizan el socket AM2+, compatible con el AM2.
Athlon 64 FX
FX64.- 2 x 2.8Ghz, Caché L1 de 256KB y L2 de 2MB. y un banding al sistema de 8.0GB/s a 2000Mhz y a la memoria de 12.8GB/s a 800Mhz.
FX70.- 4 x 2.6Ghz, Caché L1 de 512KB (256KB x procesador) y L2 de 4MB (2MB x procesador). y un banding al sistema de 8.0GB/s a 2000Mhz y a la memoria de 12.8GB/s a 800Mhz x procesador (un total de 33.6GB/s).
FX72.- 4 x 2.8Ghz, Caché L1 de 512KB (256KB x procesador) y L2 de 4MB (2MB x procesador). y un banding al sistema de 8.0GB/s a 2000Mhz y a la memoria de 12.8GB/s a 800Mhz x procesador (un total de 33.6GB/s).
FX74.- 4 x 3.0Ghz, Caché L1 de 512KB (256KB x procesador) y L2 de 4MB (2Mb x procesador). y un banding al sistema de 8.0GB/s a 2000Mhz y a la memoria de 12.8GB/s a 800Mhz x procesador (un total de 33.6GB/s).
Los FX70, FX72 y FX74 utilizan el nuevo socket F (1207FX), exclusivo para estos procesadores. A diferencia de los Quad de INTELy de los Phenom de AMD, no se trata de un procesador con 4 núcleos, sino de la unión de 2 procesadores de doble núcleo, trabajando sincronizados.
Todos los procesadores AMD cuentan con HyperTransport de 2000Mhz full duplex, gestor integrado de memoria de 128bits + 16bits ECC, con un banding total al sistema de 18.6GB/s. (20.8 en los Athlon 64 x2 Y FX64 y de de 33.6 en los FX70, FX72 y FX74)), NorthBridge integrado, con una ruta de datos de 128 bits para la frecuencia del núcleo del procesador, Cool’n’Quiet, AMD64, instrucciones 3D y multimedia y protección mejorada antivirus. AMD se ha decantado por el socket AM2, de 940 pines, diseñados para el uso de memorias DDR2, y sólo mantiene algunos Sempron de bajo precio en socket 754 y unos pocos en socket 939 (para memorias DDR), destinados a desaparecer.
Veamos algunas de estas tecnologías:
Hypertransport.- Es un vínculo punto a punto de baja latencia y alta velocidad. Aumenta la velocidad de comunicación entre los diferentes circuitos del ordenador (NorthBridge, SouthBridge, memoria…), reduciendo el número de buses y cuellos de botella y dando un mayor ancho de banda.
AMD64.- Permite la información simultanea en 32 y 64 bits sin pérdida de rendimiento.
AMD Virtual.- Extensión para la ejecución de programas virtuales. Trabaja con programas tales como Microsoft Virtual PC y Microsoft Virtual Server.
Cool ‘n’ Quiet.- Regula la frecuencia del microprocesador en relación a la potencia requerida. Reduce el consumo, la generación de calor y, por consiguiente, el ruido generado, al permitir que los ventiladores giren a menor velocidad cuando no sea necesario su máximo rendimiento.
Protección mejorada antivirus.- Esta protección funciona solamente con Windows XP SP2, Linux, Solaris y BSD Unix. Separa parte de la memoria RAM, designando esas áreas separadas como ‘’solo datos”, haciendo que en esas áreas solo se pueda leer y escribir, pero NO ejecutar los códigos que contengan.
Instrucciones 3D y multimedia.- Los procesadores ADM son compatibles con las instrucciones AMD 3DNow!, MMX, SSE, SSE2 y dependiendo del procesador SSE3.
INTEL
No hay que olvidar que hablamos de la primera empresa fabricante de microprocesadores, con una gama de productos amplísima (quizás excesivamente amplia), sobre todo en denominaciones de familias, lo que ya de por sí hace un poco difícil decidir cuál es el microprocesador que deseamos o necesitamos. Son procesadores muy rápidos y con bastante memoria caché (generalmente el doble que los AMD).
Además de procesadores, fabrica también chipset y placas base específicamente adaptados a sus productos. La unión de estos hace que sean conjuntos con un gran rendimiento.
INTEL siempre ha nombrado a sus micros por la velocidad de reloj, pero últimamente ha abandonado esta práctica para nombrarlos por sus respectivas claves, lo que hace aun más dificil su identificación.
En general podemos guiarnos por la siguiente tabla:**
**Datos extraidos de la web de INTEL (www.intel.com/espanol/).
Procesadores P4 de un núcleo.
521 a 551.- Procesadores con Hyper Threading, entre 2.8Ghz y 3.4Ghz
630 a 670.- Procesadores con Hyper Threading y SpeedStep, entre 3.0Ghz y 3.8Ghz
Procesadores Pentium D (doble núcleo).
805.- Procesador con 800 FSB, sin SpeedStep, de 2.66Ghz, con 2×1MB L2. Tec. 90 nm
820.- Procesador con 800 FSB, sin SpeedStep, de 2.80Ghz, con 2×1MB L2. Tec. 90 nm
830 y 840.- Procesadores con 800 FSB, con SpeedStep, de 3.0Ghz y 3.2Ghz, con 2×1MB L2. Tec. 90 nm
915 a 960.- Procesadores con 800 FSB, con SpeedStep, de 2.80Ghz a 3.60Ghz, con 2×2MB L2. Tec. 65 nm
Procesadores Pentium Extreme (duble núcleo).
840.- Procesador con 800 FSB, con Hyper Threading, de 3.20Ghz, con 2×1MB L2.
955 y 965.- Procesador con 1066 FSB, con Hyper Threading, de 3.46Ghz y 3.73Ghz, con 2×2MB L2.
Procesadores Core 2 Duo (doble núcleo).
T5500 y T5600.- Procesadores con 667 FSB, con SpeedStep mejorada, de 1.66Ghz y 1.83Ghz, con 2MB L2 compartida.
T7200 a T7600.- Procesadores con 667 FSB, con SpeedStep mejorada, de 2.00Ghz a 2.33Ghz, con 4MB L2 compartida.
E4300.- Procesador con 800 FSB, con SpeedStep mejorada, de 1.80Ghz, con 4MB L2 compartida.
E6300 a E6700.- Procesadores con 1066 FSB, con SpeedStep mejorada, de 1.86Ghz y 2.66Ghz, con 4MB L2 compartida.
Procesador Core 2 Quad (cuádruple núcleo).
Q6600.- Procesador con 1066 FSB, con SpeedStep mejorada, de 2.40Ghz x núcleo, con 2×4MB L2 Inteligente.
Procesadores Core 2 Extreme.
X6800.- Procesador con 1066 FSB, con SpeedStep mejorada, de 2.93Ghz x 2 núcleos, con 4MB L2 compartida.
Q6700.- Procesador con 1066 FSB, con SpeedStep mejorada, de 2.66Ghz x 4 núcleos, con 2×4MB L2 Inteligente.
Al margen de que el Quaq y los Core 2 Extreme deben ser auténticas bombas, como puede observarse, tanto lo variado de la gama como el tener procesadores con similares velocidades de reloj en varias familias y variedad de FSB puede llegar a hacer bastante complicada la labor de decantarnos por uno u otro procesador. A esto además hay que añadir que no siempre una aparente superioridad de un procesador sobre otro implica un mejor rendimiento. Como dato baste decir que un P4 478 a 3.0Ghz tenía un rendimiento superior a los P4 630 y 631, también de 3.0Ghz.
Los procesadores INTEL actuales van todos sobre socket LGA775 y soportan tanto memorias DDR como DDR2. A este respecto hay que recordar que mientras que en Intel la memoria la gestiona el NorthBridge, en AMD es el propio procesador el que la gestiona. De ahí que Intel soporte varios tipos de memoria (en realidad no depende del procesador, como es el caso de AMD, sino de la placa base).
En cuanto a las tecnologías empleadas por INTEL, veamos unas cuantas.
Hiper Threading.- Consiste en el uso de dos procesadores lógicos a partir de un solo procesador físico, permitiendo la ejecución de instrucciones en paralelo. Necesita tanto software como hardware diseñado para su uso. Consigue una mejora en el rendimiento de aprox. un 20-25% sobre el mismo procesador sin esta tecnología.
INTEL64.- Conjunto de extensiones de 64bits. Muy similar (casi idéntico) a AMD64.
INTEL VT (Tegnología Intel de Virtualización)l.- Extensión para la ejecución de programas virtuales. Trabaja con programas tales como Microsoft Virtual PC y Microsoft Virtual Server.
SpeedStep.- Regula la frecuencia del microprocesador en relación a la potencia requerida. Reduce el consumo, la generación de calor y, por consiguiente, el ruido generado, al permitir que los ventiladores giren a menor velocidad cuando no sea necesario su máximo rendimiento.
Bit de desactivación de ejecución.- Protección contra ataques maliciosos. Funciona exactamente igual que la protección mejorada antivirus de AMD. Funciona con un SO compatible con esta tecnología (aunque INTEL no señala ninguno en concreto).
Instrucciones 3D y multimedia.- Los procesadores INTEL son compatibles con las instrucciones MMX, SSE, SSE2 y dependiendo del procesador SSE3.
Bien. No debe extrañarnos las similitudes entre ambas marcas (características con distinto nombre pero con idénticos desempeños y resultados), lo que hace pensar en algún tipo de acuerdo de desarrollo entre ambas.
¿Por cuál decidirnos?.
La cuestión no tiene una fácil respuesta, ya que en la práctica no hay grandes diferencias en prestaciones ni en consumos (tanto AMD como INTEL estan sobre los 65w), ni en temperatura generada (y menos con las funciones Cool’n’Quiet y SpeedStep activadas). Gran parte de las diferencias en el rendimiento las vamos a encontrar principalmente más en la placa base y memorias que usemos, así cómo en el resto de elementos, que en el procesador en sí, y sobre todo, en las necesidades de memoria caché del software en cuestión.
En una prueba Benchmark realizada entre varios procesadores AMD e INTEL vamos a escoger el AMD5200+ (2.66Mhz x núcleo) y los INTEL E6600 (2.44Mhz x núcleo) y E6700 (2.66Mhz x núcleo), con una caché L2 en el caso de AMD de 1MB x núcleo y de 4MB compartida en el caso de INTEL. Estas pruebas toman como base 100 el procesador INTEL Pentium D 805 (2.66 Mhz, FSB 800Mhz y 2×1MB de caché L2)
3D y renderización:
AMD 5200+ – 150
INTEL E6600 – 178
INTEL E6700 – 195
CAD:
AMD 5200+ – 152
INTEL E6600 – 148
INTEL E6700 – 162
Compilación:
AMD 5200+ – 200
INTEL E6600 – 210
INTEL E6700 – 234
Procesos con muy poco requerimiento de caché:
AMD 5200+ – 161
INTEL E6600 – 157
INTEL E6700 – 173
Procesamiento fotográfico:
AMD 5200+ – 135
INTEL E6600 – 152
INTEL E6700 – 165
Compresión/descompresión:
AMD 5200+ – 152
INTEL E6600 – 181
INTEL E6700 – 193
Procesamiento de audio:
AMD 5200+ – 160
INTEL E6600 – 171
INTEL E6700 – 193
Procesamiento de vídeo:
AMD 5200+ – 148
INTEL E6600 – 172
INTEL E6700 – 190
Juegos 3D:
AMD 5200+ – 168
INTEL E6600 – 181
INTEL E6700 – 196
Media uso profesional:
AMD 5200+ – 164
INTEL E6600 – 176
INTEL E6700 – 195
Media uso doméstico:
AMD 5200+ – 155
INTEL E6600 – 177
INTEL E6700 – 195
Media total (uso profesional y doméstico):
AMD 5200+ – 160
INTEL E6600 – 167
INTEL E6700 – 195
Eficiencia x Mhz:
AMD 5200+ – 57.14
INTEL E6600 – 73.75
INTEL E6700 – 73.31
De esto se deduce algo que ya se venía diciendo: Que INTEL es superior a AMD, más que nada por la mayor caché de los procesadores INTEL, superando AMD a INTEL (E6600) en procesos CAD y procesos con muy poco requerimiento de caché.
Observamos también que el E6600 supera en general al AMD 5200+ por muy poco (algo menos del 5%), yéndose este porcentaje a cerca del 22% en el caso del E6700. Resulta también curioso que el E6600 sea el más eficiente de los tres en relación a su velocidad de reloj, quedando muy penalizado el AMD por su baja caché. Aquí surge una pregunta. ¿Cómo quedaría esta comparativa con un 5200+ de igual caché a INTEL?. Pero quedan dos interrogantes más fáciles de responder (al menos en teoría). La primera es si esta diferencia es apreciable para el usuario medio (no tanto en el caso del E6700 como en el del E6600). La segunda es quizás más importante: ¿Compensa esta diferencia de rendimiento (que conste que hablamos de unos rendimientos muy altos en ambos casos) una diferencia en precio en torno al 40% en el caso del E6600 y del 96% en el caso del E6700? Estamos hablando de 99.00 euros y de 236 euros de diferencia, lo que no es poco.
Conclusión
Pues bien. Después de todo esto, seguimos con la misma duda ¿AMD o INTEL?. Los dos fabrican con la misma calidad, con un consumo prácticamente igual y unas temperaturas de funcionamiento también iguales. INTEL ofrece un mayor rendimiento comparando micros de igual velocidad (por supuesto nos referimos a los Core 2 Duo y superiores, en el resto de la gama es al contrario), pero sólo cuando se le exige el máximo, ya que las diferencias en general no son demasiado altas y se salen de las prestaciones que va a necesitar el usuario medio. Lo cierto es que este extra de rendimiento nos cuesta un dinero (bastante), que es al final lo que debemos decidir, si para nuestras necesidades nos compensa ese desembolso extra.