Y el archivo estadisticas.csv con el siguiente contenido de ejemplo:
Buenos Aires, México, Budapest, ...
Ciudad,Indicador,valor
Santiago de Chile,Num_empresas,58
Guayaquil,Inversion en $,17423...
Guayaquil,Num_coworkings,5
Nota: La primera línea del archivo estadisticas.csv tiene los nombres de todas las ciudades presentes en el archivo, mientras que la segunda línea es su cabecera. Una ciudad puede estar repetida en varias líneas del archivo pero con un indicador diferente.
Escriba un programa en Python que cree el diccionario indicadores, el arreglo ciudades y la matriz M utilizados en el TEMA 1.
Rúbrica: crear diccionario ( puntos), crear arreglo ( puntos), crear matriz ( puntos) Nota: puntos detallados no indicados en el impreso del examen original.
3ra Evaluación II Término 2018-2019. 15-Febrero-2019 /CCPG001
Tema2. (60 puntos) Asuma que tiene un archivo por cada partido jugado en el Sudamericano Sub-20. Cada archivo tiene información con datos de los jugadores que participaron en el partido con el siguiente formato:
1. actualizaDiccionario(nomArchivo,dic) que recibe el nombre de un archivo con los datos del partido y actualiza el diccionariode totales por jugador que tiene el siguiente formato:
2. buenDeportista(jugador, dic) que recibe el nombre de un jugador y el diccionariode totales y determina si ese jugador puede ser catalogado como un «buen deportista»; la función retorna «True» o «False» . Un jugador se considera «buen deportista»si ha recibido menos de dos tarjetas por cada 270 minutos de juego.
3.JugadorAtleta(jugador,dic) que recibe el nombre de un jugador y el diccionariode totales, determinando si el jugador ha corrido como mínimo el promedio de lo que han corrido los jugadores de su pais y ha anotado al menos un gol; la función retorna «True» o «False»
4. paisBuenasPracicas(pais,dic) que recibe el nombre de un país y el diccionariode totales, analizando si ese país puede ser nominado para el «Best Practices award». Un país puede ser nominado a este premio si TODOS los jugadores del país pueden ser catalogados como «buen deportista». La funcion retorna «True»o «False»
Escriba un programa que:
5. Forme el diccionariode totales a partir de una lista con los nombres de los archivos de datos de los partidos. Asuma que tiene una lista para esta tarea:
L = ['br-ur.csv', ...,'ec-vn.csv']
6. Muestre los siguiente datos por país:
a. Porcentaje de jugadores atletas. es decir e número de jugadores atletas dividido para el total de jugadores del país.
b. Goles por Km recorrido, es decir el número de goles del país dividido para el total de Km recorridos por todos sus jugadores
7. Muestre los países nominados para el «Best Practices award
8 Muestre la nómina de jugadores atletas con su respectivo país.
2da Evaluación II Término 2018-2019. 2-Febrero-2019 /CCPG001
Sección 4. Programa que usa las funciones de la sección 1, 2, 3 (preguntas 6-9)
implemente un programa principal que:
6. Forme las matrices a partir del archivo ‘artico2009-2019.txt‘
7. Muestre por pantalla el código de las especies que en el 2019 son comunes (se repiten) para los cuadrantes Q1, Q2 y Q4 pero que no existan en Q3.
Los siguientes dos numerales se resuelven juntos.
8. Determine si ha habido migración de la especie con código 3. Existe migración si el cuadrante con mayor población en el 2009 y 2019 son diferentes .
9. Una posible explicación para la migración de una especie puede ser el deshielo. Entonces, si existió migración (de la especie con código 3) del cuadrante con mayor población en el 2009 (Qx) al cuadrante con mayor población en el 2019 (Qy), muestre la diferencia (positiva o negativa) de densidad de hielo del 2009 al 2019 para el cuadrante Qx.
Calcule la diferencia con la siguiente fórmula:
Diferencia = densidad_Qx_2019 - densidad_Qx_2009
Por ejemplo:
Si migracionEspecie retorna (‘Q1’, ‘Q4’), la diferencia será la densidad de hielo en el 2009 del cuadrante ‘Q1’ menos la densidad de hielo en el 2019 del mismo cuadrante ‘Q1’.
Para esto dispone de información sobre la cantidad de hielo y población de animales de diversas especies durante los años 2009 y 2019 en un archivo con el siguiente formato:
Número de filas
Número de columnas
Año,fila,columna,hielo,especie
crearMatriz(nomArchivo) que recibe el nombre del archivo con los datos de la WWF y retorna una tupla que contiene las siguientes cuatro matrices:
mhielo2009: Cantidad de hielo 2009
1
0
0
1
…
0
1
1
1
…
1
0
1
0
…
1
1
1
0
…
0
1
0
1
…
1
1
1
0
…
…
…
…
…
…
mhielo2019: Cantidad de hielo 2019
1
0
0
1
…
0
1
0
1
…
1
0
1
0
…
1
0
1
0
…
0
1
0
1
…
0
0
1
0
…
…
…
…
…
…
mAnimales2009: Especies de animales 2009
1
2
4
4
…
2
5
5
3
…
1
3
9
1
…
1
1
4
2
…
4
22
4
7
…
1
1
14
4
…
…
…
…
…
…
mAnimales2019: Especies de animales 2019
3
2
4
1
…
0
11
3
5
…
1
0
67
1
…
2
22
3
2
…
13
13
2
3
…
3
0
1
0
…
…
…
…
…
…
En las matrices de hielo cada valor uno (1) en una celda representa la presencia de hielo.
En las matrices de animales cada celda representa la presencia de un animal de una especie usando una cierta codificación, como la del ejemplo:
0: No hay animal
1: Lobo ártico
2: Oso Polar
3: Reno
4: Foca
5: ...
Rúbrica: numeral 1 (15 puntos): abrir y cerrar archivo, procesar lineas de tamaño de matriz, crear matrices, procesar líneas de datos de matriz, llenar matrices.
3ra Evaluación I Término 2018-2019. 14-Septiembre-2018 /CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
Tema 1 (40 puntos). En una empresa de transporte de carga (trailers) se registran para cada fecha, el código de los choferes que manejaron en una ruta.
id_ruta, id_chofer, fecha
Guayaquil-Cuenca,SMS,17-05-2018
Guayaquil-Cuenca,AGB,18-05-2018
Guayaquil-Cuenca,SMZ,17-05-2018
Guayaquil-Daule,EVN,17-05-2018
Guayaquil-Daule,AAQ,18-05-2018
Por lo rutinario del trabajo, se ha recomendado que los choferes no repitan una ruta para los últimos n días a partir de una fecha. Para seguir la recomendación se requiere implementar:
a) La función cargarDatos(narchivo) que recibe un archivo de registro y retorna una tupla con:
– un conjunto con los choferes que trabajaron en las fechas del archivo (id_chofer)
– los datos del archivo en un diccionario con la estructura mostrada.
b) La función encontrarChoferes(datos, loschoferes, unafecha, unaruta, n), que para seguir la recomendación, encuentra aquellos choferes que no manejaron en una ruta, durante los n dias anteriores a una fecha.
c) La función grabarArchivo(datos, loschoferes, unafecha, unaruta, n) que crea un archivo con el resultado de la función anterior con el formato mostrado. El nombre del archico generado se conforma como: «unaruta_unafecha.txt»
Nombre de archivo: Guayaquil-Cuenca_19-05-2018_2.txt
Para la ruta Guayaquil-Cuenca los choferes disponibles para la fecha 19-05-2018 que no hayan manejado 2 dias anteriores son:
EVN
AAQ
d) Genere todos los archivos para todas las rutas disponibles.
NOTA: Para administrar las fechas, usted ya dispone de una función calcularFecha(unafecha,n) que recibe una fecha y los n días anteriores y determina la fecha pasada. El formato de fecha se maneja en el mismo formato de fecha que el archivo.
>>> calcularFecha('19-05-2018',2)
'17-05-2018'
Rúbrica: Literal a (12 puntos), Literal b(16 puntos), Literal c y d (12 puntos)
2da Evaluación I Término 2018-2019. 31-Agosto-2018 /CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
Tema 2. (50 puntos) Una compañía, con miles de empleados y varias sucursales en el país, paga sus salarios por hora clasificadas como:
– horas regulares (HR),
– horas fuera de horario normal (HER),
– fines de semana (HFDS) y
– feriados (HF).
El registro de asistencia de los empleados contiene: dia, mes, año, cantidad de horas trabajadas, entre otros mostrados en el archivo ejemplo.
El archivo inicia con líneas del valor en dólares por hora, los factores de pago por tipo, una linea de encabezado y el detalle de las horas trabajadas por empleado. Por ejemplo:
VH,10,Valor Hora en ésta compañía
HR,1,Factor Horas Regulares
HER,1.21,Factor Horas Extras en dias Regulares (lunes-viernes)
HFDS,1.37,Factor Horas en Fin De Semana (Sabado o domingo)
HF,1.39,Factor Horas en Feriado
Fecha,dia,feriado,ID,nombre,sucursal,ciudad,horas-trabajadas
...
10-Agosto-2018,5,Si,FG848801,Fabricio Granados,River Mall,Cuenca,1
10-Agosto-2018,5,Si,GH907603,Segunda Vez Zambrano,River Mall,Cuenca,1
09-Agosto-2018,4,No,FG848801,Fabricio Granados,River Mall,Cuenca,9
...
Las horas extras en días regulares se calculan después de la 8va hora de trabajo.
Si el empleado trabajó en un dia feriado, que también es fin de semana, el factor aplicado es el más alto, es decir feriado.
Desarrolle las funciones descritas a continuación y un programa para calcular los valores a pagar para cada empleado.
a) calcularHoras(linea). Recibe una línea del archivo y determina el número de horas trabajadas para cada categoría. El resultado es una tupla con el identificador del empleado, ciudad y horas trabajadas regulares, extras, fines de semana y feriado.
>>> linea = "09-Agosto-2018,4,No,FG848801,Fabricio Granados, River Mall, Cuenca,9"
>>> calcularHoras(linea)
('FG848801','Cuenca',8,1,0,0)
b) leerData(nomA). Recibe el nombre del archivo de nómina (nomA) correspondiente a un mes de un año y retorna una tupla de tres elementos: (totales, mes, año). Totales es un diccionario con la suma en dólares de HR, HER, HFDS y HF trabajados por cada empleado con la siguiente estructura:
c) generaReporte(nomA). Recibe el nombre del archivo de nómina (nomA) correspondiente a un mes de un añoy genera un nuevo archivo reporte para cada ciudad.
Cada archivo reporte tiene como nombre «ciudadMes-Año.txt» y contiene: cabecera y la siguiente información por cada empleado:
3ra Evaluación II Término 2017-2018. Febrero 23, 2018 /CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
Tema 2. (50 puntos) Suponga que tiene el archivo «videojuegos.csv»con información sobre todo el contenido de su biblioteca de videojuegos.
El archivo tiene la siguiente estructura:
videojuegos.csv
Nombre, Año, Consola, Calificación, Tags (separados por ;)
The Legend of Zelda,86,Famicon Disk System,3.5,RPG;Link;Zelda;Hyrile;Triforce
Double Dragon,87,Arcade,3.7,Beat-em up; Billy;Jimmy;Puñete
The Legend of Zelda,88,NES,4.3,RPG;Link;Zelda;Hyrule;Triforce
...
Halo 5:Guardians,15,Xbox One,4,FPS;Master Chief;Cortana;Covenant
Note que un juego aparecerá listado en el archivo una vez por cada consola en la que fué lanzado.
La categoría del juego se especifica siempre en el primer Tag. Por ejemplo, Double Dragon pertenece a la categoriía Beat-‘em up.
Desarrolle lo siguiente:
a) La función juegosConsolas(nomArchivo, categoria, decada) que recibe el nombre del archivo con la información de los videojuegos, una categoría y número de cuatro dígitos representando una década de años. La función retoma una tupla con 2 elementos. El primer elemento es la lista con los valores únicos de todos lo juegos de esa década para esa categoría. El segundo elemento es la lista con valores únicos de todas las consolas que tienen juegos para esa década y categoría.
Por ejemplo, para llamar a juegosConsolas('videojuegos.csv','RPG',1980) retorna:
(['The legend of Zelda', 'Phantasy Star', ...], ['NES', 'Famicon Disk System', ...])
b) La función crearMatriz(nomArchivo, categoria, decada) que recibe el nombre del archivo con la información de los videojuegos, el nombre de una categoría de videojuegos y un número de cuatro dígitos representando una década de años. La función deberá leer el archivo y retornar una matriz donde las filas representan los juegos de categoria para la decada , las columnas representan las consolas que tienen juegos de categoria para la decada y las celdas son las calificaciones de cada juego para cada consola. Si un juego no existe para una consola, su calificación deberá ser cero (0).
c) La función mejoresJuegos(nomArchivo, categoria, decada) que recibe el nombre del archivo con la información de los videojuegos, el nombre de una categoría de videojuegos y un número de cuatro dígitos representando una década de años. La función deberá generar el archivo “Mejores.txt” con los cinco mejores juegos de la decada para la categoria , ordenados de mayor a menor por su calificación promedio. Para calcular el promedio de un juego, considere únicamente las consolas en las que fue lanzado (no considere los valores cero). El archivo tendrá la siguiente estructura:
NombreNombre,Promedio_calificación
d) La función colecciones(nomArchivo, palabras) que recibe el nombre del archivo con la información de los videojuegos y una lista de palabras. La función deberá retornar otra lista de valores únicos con los nombres de todos los juegos que sus Tags contengan todos los términos de la lista palabras .
Rúbrica: literal a (15 puntos), literal b (17 puntos), literal c (18 puntos), literal d Bono (5 puntos)
Comprador, Vendedor, Producto, UnidadesVendidas, Ventasen$, Fecha
Estados Unidos,Ecuador,rosas,59284,631432.21,2018-01-10
Holanda,Japon,tulipanes,2384,12424.87,2017-11-22
...
Estados Unidos,Ecuador,girasoles,38284,331432.75,2018-02-01
Note que un país puede vender el mismo producto al mismo comprador pero en una fecha diferente.
a) Elabore una función calculaTotales(categoria) que procesa los datos del archivo ‘categoria.txt’ y determina los totales de las transacciones entre países. Los totales se muestran en un diccionario de la forma:
Por ejemplo, si en la categoría ‘Flores’, ‘Estados Unidos’ le compró ‘rosas’ a ‘Ecuador’ en 12 fechas diferentes, el total deberá ser la suma de los valores de las 12 transacciones:
{('Estados Unidos', 'Ecuador', 'rosas'): 257868}
b) Escriba una función consolidado(nomArchivo, categorias) que dada una lista de categorías genera el listado del acumulado de unidades vendidas por comprador, vendedor y producto.
El resultado se almacena en el archivo ‘nomArchivo.txt’ con la siguiente estructura:
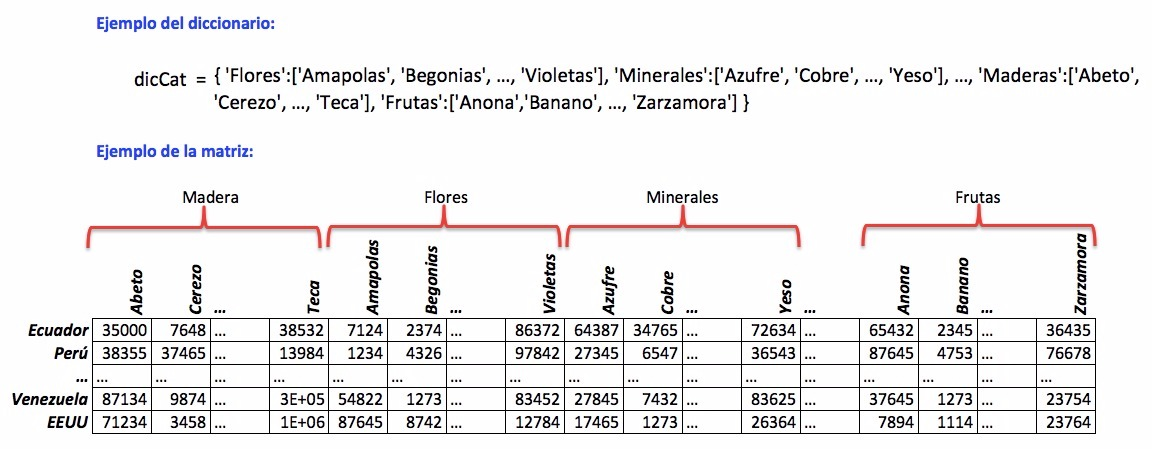
Para el resto del ejercicio, asuma que dispone de una función crearMatriz(narchivo) que recibe el nombre del archivo consolidado y devuelve una tupla con tres elementos:
(1) Matriz M cuyas filas representan países vendedores, columas representan productos ordenados alfabeticamente dentro de cada categoría y las celdas representan ventas totales en unidades.
(2) lista con las etiquetas de las filas y
(3) lista con las etiquetas de las columnas.
c) La función ventasCategorias(nomArchivo, dicCat) realiza un reporte por categoría de los 5 países que han vendido menos productos.
Cada reporte se almacena en un archivo ‘total_categoria.txt’.
Los datos provienen del archivo consolidado nomArchivo.txt y un diccionario donde las claves son las categorías y los valores son listas con todos los productos.
Los productos se encuentran ordenados alfabeticamente dentro de cada categoría, las categorías no están ordenadas alfabéticamente.
Cada archivo tendrá la siguiente estructura:
País,Total_Ventas
Rúbrica: literal a (15 puntos), literal b (15 puntos), literal c (25 puntos).
200901456,Física I,80,91,73,AP
201321454,Química,45,57,73,AP
201121372,Economía,73,82,83,AP
201321454,Fundamentos de Programación,11,9,9,RP
…
Desarrolle los siguientes literales:
a) Elabore la función academico(narchivos) recibe los nombres de los archivosde notas (tupla) para cada semestre y retorna un diccionario de notascon la estructura mostrada.
b) Implemente la función semestres(notas, matricula) que recibe las notas (diccionario) y un número de matrícula de un estudiante para entregar todos los semestres en que ha tomado materias (tupla) .
c) Realice la función nota_academico(notas, matricula, materia) que recibe las notas (en diccionario), una matrículay el nombre de una materia y determina la nota total para esa materia.
La nota total se calcula como el promedio de las dos notas más altas entre parcial, final y mejoramiento. Si el estudiante aún no ha tomado la materia, se presenta como nota cero (0). Si el estudiante en más de una ocasión ha tomado la materiase obtiene la nota con el promedio más alto.
d) Elabore la función mas_aprobados(notas, semestre) que devuelve el nombre de la materia con mayor cantidad de estudiantes aprobados (estado AP) en el semestre indicado.
Rúbrica: Literal a (10 puntos + 5 puntos de bono) b (5 puntos), c y d (15 puntos)
Ejemplo:
narchivos=('notas-2015-I.csv',
'notas-2013-II.csv')
matricula = 201321454
materia = 'Fundamentos de Programación'
semestre = '2015-I'
Se obtiene:
--- para 201321454:
semestres que estudió: ('2015-I', '2013-II')
notas final para Fundamentos de Programación: 82.5
--- En el semestre 2015-I:
la materia con alto indice de aprobación es: Fundamentos de Programación
2da Evaluación I Término 2017-2018. Septiembre 2, 2017 /CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
TEMA 1 (40 PUNTOS). Para el texto de un libro se requiere generar las estadísticas del uso de palabras . Dispone también de una lista con conectores = [‘la’, ‘con’, ‘de’, ‘y’, ‘…’] que son palabras que no agregan mayor significado al texto.
Como ejemplo, el archivo con nombre=’ textolibro.txt ‘ contiene:
Con la ayuda de un grupo de amigos y de valientes aliados Frodo emprende un peligroso viaje con la
misión de destruir el Anillo Único Pero el Señor Oscuro Sauron quien creara el Anillo envía a sus
servidores para perseguir al grupo Si Sauron lograra recuperar el Anillo sería el final de la Tierra
Media Ganadora de cuatro Oscars este inmortal relato sobre el bien y el mal la amistad y el sacrificio
te transportará a un mundo más allá de tu imaginación
...
Desarrolle lo necesario para implementar las siguientes funciones:
a) cargarArchivo(nombre), que lea el archivo de texto denominado ‘nombre’para crear una tabla (NumPy con dtype=’U20′), donde cada fila representa una línea y cada columna contiene una palabra de dicha línea.
Notas: Cada línea del archivo está limitada por ‘\n‘ y cada palabra está separada por un espacio en blanco. Asuma que cada palabra tendrá 20 caracteres como máximo y que el número máximo de palabras por líneas es 30. Si la línea tiene menos de 30 palabras, las celdas restantes deben ser llenadas con una cadena vacía (»).
b) ocurrencias(palabra, tabla), que tiene como resultado el número de veces que la palabraaparece en la tabla.
c) lineas(palabra, tabla), que entrega un vector (tupla) con los números de fila donde aparece la palabra en tabla.
d) contarPalabras(tabla, conectores) que muestra como resultado una tupla con:
– la cantidad de palabras únicas en el texto (incluyendo los conectores) y
– el número solo de conectores que se incluyen en el texto.
Cada palabra (regular o conector) debe ser contada una sola vez sin importar cuantas veces se repita en el texto.
e) concordancia(tabla, conectores) que obtiene las estadísticas de las palabras y entrega el diccionario mostrado en ejemplo.
Para el diccionario interno ‘palabras‘ no debe incluir los ‘conectores’. .
Puede apoyarse en las funciones anteriores para generar el diccionario.