1ra Evaluación II Término 2018-2019, Noviembre 23, 2018. CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
Tema 3. (50 puntos) El Black Friday inaugura la temporada de compras navideñas con significativas rebajas en muchas tiendas minoristas y grandes almacenes. 
Sucede después de la celebración de Acción de Gracias en Estados Unidos.
Suponga que posee los datos de los productos de una tienda en los siguientes arreglos:
C: códigos de todos los productos (cadenas de caracteres)
P: precios en dólares para cada uno de los productos (valores con decimales).
D: descuentos asociados a cada producto (enteros entre 0 y 100)
S: nombre de la sección donde se encuentra cada producto (cadenas de caracteres)
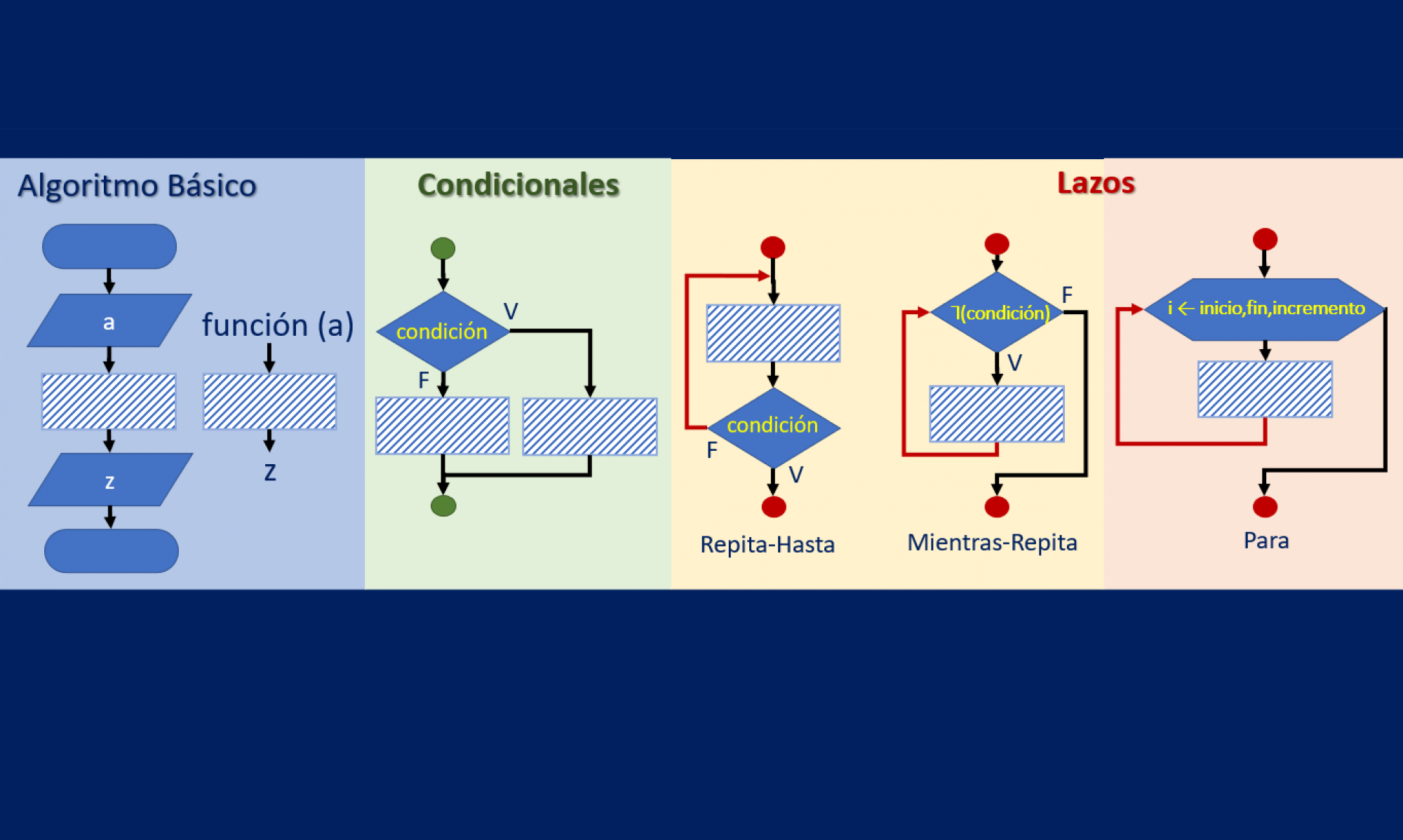
Se requiere implementar las siguientes funciones:
- calcularPrecio(codigo,C,P,D) que recibe un código y los arreglos C,P,D y retorna el precio final del producto, aplicando el descuento correspondiente.
Para calcular el precio final, aplique las siguiente fórmula:
precio_final = precio - precio*\frac{descuento}{100} - calcularTotal(compras,C,P,D) que recibe una lista de compras con los códigos de los productos, los arreglos C,P,D y aplicando todos los descuentos calcula el valor total a pagar, .
- hallarSecciones(compras,C,S) que recibe una lista de compras con los códigos de los productos, los arreglos C y S y determina las secciones que deberán visitar durante las compras. La lista de visitas no tiene elementos repetidos.
- descuentosPorSección (D,S) que recibe los arrelgos D y S y retorna una tabla con el nombre de cada sección y la cantidad de productos que tienen más del 50% de descuento.
Realice un programa que inicialmente muestre una tabla con las secciones y cantidad de productos con más del 50% de descuento. Luego para las compras, permita ingresar los códigos de los productos, procese y muestre el valor total a pagar y las secciones que necesita visitar. El usuario terminará de ingresar las compras escribiendo ‘fin’.
Ejemplos de arreglos:
C = ['CTR-2424', 'SKU-5675', 'PSS-4542'] P = [ 56.65, 32.00, 22.22] D = [0, 50, 10] S = ['Ropa Niños', 'Juguetes', 'Hombre']
Rúbrica: numeral 1 (5 puntos), numeral 2 y 3 (10 puntos c/u), numeral 4 (15 puntos). programa (10 puntos)
Referencias: