1ra Evaluación II Término 2018-2019, Noviembre 23, 2018. CCPG001
Tema 1. (20 puntos)
a. (10 puntos) ¿Qué imprime el siguiente código? Justifique su respuesta
lista = [89, 45, 23, 17, 55, 95, 13, 41, 28, 11]
lista.sort()
promedio = sum(lista)//len(lista)
print(promedio)
menores = []
i = 0
while lista[i] < promedio:
menores.append(lista[i])
i += 1
print(menores)
b. (10 puntos) ¿Qué imprime el siguiente código? Justifique su respuesta
pal = 'Se van en sus naves'
b = pal[::-1].replace(' ', '').lower()
pal_b = pal.lower().replace(' ', '')
if pal_b == b:
print('Es palíndromo')
else:
print('No es palíndromo')
Nota: Asuma que este tema NO tiemen errores de compilación. Si usted cree que hay algún error de compilación, consúltelo inmediatamente con su profesor
3ra Evaluación I Término 2018-2019. 14-Septiembre-2018 /CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
Tema 2. (50 puntos) En el último discurso presidencial, se mencionaron algunos datos sobre las ganancias de algunos minerales del país que llamaron la atención de los ciudadanos.
Suponga que tiene todo el texto del discurso con el formato en minúsculas, las palabras separadas por un espacio, sin signos de puntuacion ni otros símbolos. Los minerales están identificados por el prefijo «mral_» seguido del nombre del mineral. Por ejemplo: ‘mral_oro’, ‘mral_plata’, ‘mral_cobalto’
discurso = '... y el dia de ayer descubrimos en la mina mirador que la cantidad de mral_oro ...'
a) Implemente la función extraerMinerales(discurso) que al recibir el texto del discurso encuentra los nombres de todos los minerales mencionados. El resultado es una lista con los nombres de los minerales que empiezan con mayúscula y no se repiten en la lista.
Por otro lado, suponque que dispone de las tablas de producción para cada mineral de las canteras del país, costos totales de extracción, costos totales de transporte, los nombres de los minerales y minas asociados a las filas y columnas de las tablas, y los precios cada mineral, semejantes a los mostrados al final del ejercicio.
Con ésta información implemente las siguiente funciones:
b) La función calcularGanancias(P,C,T,precios) que calcula las ganancias o pérdidas de cada mineral por mina. La función recibe la lista de precios de venta de los minerales las tres matrices: producción (P) , costos totales de extracción (C) y costos totales de transporte (T).
Adicionamente, considere las siguientes fórmulas:
ganancia = ventas - costos
ventas = producción*precio
costos = costos de transporte + costo de extracción
c) La función gananciaTotal(M, Minerales) determina las ganancias totales de cada mineral de mayor a menor, junto a los correspondientes nombres de mineral.
La función recibe la matriz del literal anterior y la lista de las etiquetas de los minerales (fila de la matriz).
El resultado es una tupla de dos elementos ordenados por ganancia:
– el vector de Numpy de las ganancias totales por mineral
– una lista con los nombres de los minerales.
d) La función top8(discurso, ganatotal) presenta los nombres de los ocho (8) minerales que generaron más ganancias totales y que fueron mencionados en el discurso. La variable ganatotal corresponde al resultado de la función del literal anterior.
Rúbrica: literal a (1o puntos), literal b (15 puntos), literal c (15 puntos), literal d (10 puntos)
Datos de prueba:
minerales = ['Oro', 'Plata', 'Cobre']
precios = [38.48, 3.43, 0.01]
minas = ['MIRADOR', 'FRUTA_DEL_NORTE', 'LOMA_LARGA', 'otra']
# produccion
P = np.array([[ 13524000, 121072000, 1204000, 9632000],
[ 28000000, 952000, 9632000, 96404000],
[126980000, 896000, 92988000, 9604000]])
# costos totales de extracción
C = np.array([[12.32, 10.23, 23.23, 19.23],
[ 3.13, 1.78, 2.45, 1,69],
[ 8.32, 5.25, 6.32, 6.89]])
# costos totales de transporte
T = np.array([[ 43736616, 341786256, 5442080, 28241024],
[ 76244000, 1827840, 13966400, 435746080],
[156439360, 1121792,300723192, 10785292]])
3ra Evaluación I Término 2018-2019. 14-Septiembre-2018 /CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
Tema 1 (40 puntos). En una empresa de transporte de carga (trailers) se registran para cada fecha, el código de los choferes que manejaron en una ruta.
id_ruta, id_chofer, fecha
Guayaquil-Cuenca,SMS,17-05-2018
Guayaquil-Cuenca,AGB,18-05-2018
Guayaquil-Cuenca,SMZ,17-05-2018
Guayaquil-Daule,EVN,17-05-2018
Guayaquil-Daule,AAQ,18-05-2018
Por lo rutinario del trabajo, se ha recomendado que los choferes no repitan una ruta para los últimos n días a partir de una fecha. Para seguir la recomendación se requiere implementar:
a) La función cargarDatos(narchivo) que recibe un archivo de registro y retorna una tupla con:
– un conjunto con los choferes que trabajaron en las fechas del archivo (id_chofer)
– los datos del archivo en un diccionario con la estructura mostrada.
b) La función encontrarChoferes(datos, loschoferes, unafecha, unaruta, n), que para seguir la recomendación, encuentra aquellos choferes que no manejaron en una ruta, durante los n dias anteriores a una fecha.
c) La función grabarArchivo(datos, loschoferes, unafecha, unaruta, n) que crea un archivo con el resultado de la función anterior con el formato mostrado. El nombre del archico generado se conforma como: «unaruta_unafecha.txt»
Nombre de archivo: Guayaquil-Cuenca_19-05-2018_2.txt
Para la ruta Guayaquil-Cuenca los choferes disponibles para la fecha 19-05-2018 que no hayan manejado 2 dias anteriores son:
EVN
AAQ
d) Genere todos los archivos para todas las rutas disponibles.
NOTA: Para administrar las fechas, usted ya dispone de una función calcularFecha(unafecha,n) que recibe una fecha y los n días anteriores y determina la fecha pasada. El formato de fecha se maneja en el mismo formato de fecha que el archivo.
>>> calcularFecha('19-05-2018',2)
'17-05-2018'
Rúbrica: Literal a (12 puntos), Literal b(16 puntos), Literal c y d (12 puntos)
2da Evaluación I Término 2018-2019. 31-Agosto-2018 /CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
Tema 2. (50 puntos) Una compañía, con miles de empleados y varias sucursales en el país, paga sus salarios por hora clasificadas como:
– horas regulares (HR),
– horas fuera de horario normal (HER),
– fines de semana (HFDS) y
– feriados (HF).
El registro de asistencia de los empleados contiene: dia, mes, año, cantidad de horas trabajadas, entre otros mostrados en el archivo ejemplo.
El archivo inicia con líneas del valor en dólares por hora, los factores de pago por tipo, una linea de encabezado y el detalle de las horas trabajadas por empleado. Por ejemplo:
VH,10,Valor Hora en ésta compañía
HR,1,Factor Horas Regulares
HER,1.21,Factor Horas Extras en dias Regulares (lunes-viernes)
HFDS,1.37,Factor Horas en Fin De Semana (Sabado o domingo)
HF,1.39,Factor Horas en Feriado
Fecha,dia,feriado,ID,nombre,sucursal,ciudad,horas-trabajadas
...
10-Agosto-2018,5,Si,FG848801,Fabricio Granados,River Mall,Cuenca,1
10-Agosto-2018,5,Si,GH907603,Segunda Vez Zambrano,River Mall,Cuenca,1
09-Agosto-2018,4,No,FG848801,Fabricio Granados,River Mall,Cuenca,9
...
Las horas extras en días regulares se calculan después de la 8va hora de trabajo.
Si el empleado trabajó en un dia feriado, que también es fin de semana, el factor aplicado es el más alto, es decir feriado.
Desarrolle las funciones descritas a continuación y un programa para calcular los valores a pagar para cada empleado.
a) calcularHoras(linea). Recibe una línea del archivo y determina el número de horas trabajadas para cada categoría. El resultado es una tupla con el identificador del empleado, ciudad y horas trabajadas regulares, extras, fines de semana y feriado.
>>> linea = "09-Agosto-2018,4,No,FG848801,Fabricio Granados, River Mall, Cuenca,9"
>>> calcularHoras(linea)
('FG848801','Cuenca',8,1,0,0)
b) leerData(nomA). Recibe el nombre del archivo de nómina (nomA) correspondiente a un mes de un año y retorna una tupla de tres elementos: (totales, mes, año). Totales es un diccionario con la suma en dólares de HR, HER, HFDS y HF trabajados por cada empleado con la siguiente estructura:
c) generaReporte(nomA). Recibe el nombre del archivo de nómina (nomA) correspondiente a un mes de un añoy genera un nuevo archivo reporte para cada ciudad.
Cada archivo reporte tiene como nombre «ciudadMes-Año.txt» y contiene: cabecera y la siguiente información por cada empleado:
2da Evaluación I Término 2018-2019. 31-Agosto-2018 /CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
Sistema ECU911
Tema 1. (40 puntos) Para analizar los niveles de seguridad en el país, se registran los incidentes por ciudad y tipo delito en un archivo.
incidentes
robo vehículo
asalto
Escandalo vía pública
…
Quito
540
4523
24
…
Guayaquil
605
6345
5
…
Cuenca
123
676
133
…
Machala
67
1234
412
…
…
…
….
….
…
Dispone de un modulo «ecu911» con la función cargarDatos(nombrearchivo) que lee el archivo y entrega un diccionariocon la las veces que se ha reportado cada tipo de delito para cada ciudad del país en el siguiente formato:
Para crear el diccionario debe importar el módulo.
Se requiere implementar lo siguiente:
a. Una función tablatitulos(diccionario) que recibe el diccionario descrito y retorna una coleccion:
titulos = (ciudad, tipodelito)
ciudad contiene las ciudades del archivo, y tipodelito contiene los tipos considerados en el diccionario, ambos sin duplicados.
b. La función crearMatriz(diccionario) que usando la información del diccionario crea una matriz con el número de incidentes por ciudad y tipo de delito. La matriz es un arreglo de numpy, semejante al ejemplo:
c. Una función ciudadesMenosSeguras(matriz, titulos, untipo, poblacion) que retorna los nombres de las tres ciudades que tienen el mayor indice per capita de para untipode delito.
\text{indice per capita} = \frac{\text{numero de incidentes reportados}}{\text{poblacion de la ciudad}}
La función recibe la matriz , titulos de los literales anteriores, un tipo de delito y la población de cada ciudad del país en un vector, arreglo Numpy.
Rúbrica: literal a (10 puntos), literal b (20 puntos), literal c (10 puntos).
1ra Evaluación I Término 2018-2019, Junio 29, 2018. CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
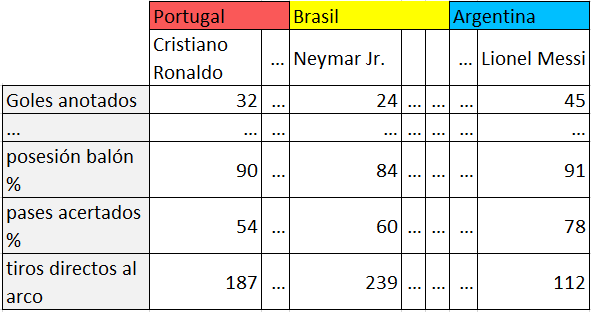
Tema 2. (50 puntos) Dispone de una tabla con el desempeño histórico (estadística) de los jugadores equipos (país) que participan en el Mundial de Futbol:
Los jugadores se encuentran ordenados por equipos siguiendo el orden del listado de países siguiente:
paises = ['Portugal', 'Brasil', … , 'Argentina']
Dispone de otra tabla con los equipos (país) y jugadores, conformada como una lista que contiene como elementos otras listas (lista de listas):
pais_jugadores = [prtgl,
brsl,
…,
argntn]
Cada elemento de la tabla pais_jugadores contiene los nombres de los jugadores registrados en cada equipo:
con los datos disponibles en las tablas y usando instruciones de Python, se requiere:
a. Determinar el país con el promedio de goles más alto.
\text{promedio de goles} =\frac{\text{goles anotados del país}}{\text{numero de jugadores del país}}
b. Contar cuántos jugadores españoles tienen una efectividad mayor que la efectividad promedio de España.
\text{efectividad} = \frac{\text{goles anotados}}{\text{Tiros directo al arco}}
c. Mostrar la lista con los nombres de los jugadores que tienen más del 76% de posesión del balón .
d. Mostrar el jugador con mayor porcentaje de pases acertados, indicando nombre y país al que pertenece.
e. Calcular el promedio mundial por cada una de las características.
( “Goles anotados», «…», «% posesión del balón», «% de pases acertados», «Tiros directos al arco» ).
f. Determine si cada una las características para el jugador «Lionel Messi» están por encima del correspondiente promedio mundial. Muestre el mensaje de respuesta correspondiente:
“Lionel Messi está/no está por encima del promedio mundial”
Sugerencia: Separe el trabajo de ubicar los jugadores de la tabla, del procesamiento de los datos de desempeño.
Para ubicar los jugadores realice una tabla siguiendo las siguientes instrucciones:
1. A partir de los datos pais_jugadores y las listas de jugadores, bosqueje la tabla que se forma como referencia.
2. Unifique en un vector jugadores a todos los de cada país.
3. Realice una tabla en cuyas filas ubique cada pais con el índice [desde, hasta, cuantos] que indica las posiciones desde/hasta dónde se cuentan los jugadores para cada pais, además de la cantidad de jugadores.
Ésta última tabla permitirá ubicar a los jugadores por países.
Para probar los algoritmos, puede usar los datos de las tablas simplificadas para prueba:
1ra Evaluación I Término 2018-2019, Junio 29, 2018. CCPG001
(Editado para tarea, se mantiene el objetivo de aprendizaje)
Tema 1. (40 PUNTOS) La compañía ACME S.A. está desarrollando un nuevo método para detectar especies en base a su ADN.
Para representar una especie por su ADN se utiliza una secuencia S compuesta únicamente de las letras A, C, G y T.
La inversa de una secuencia S se determina con los símbolos en orden inverso a lo presentado. Ejemplo:
>>> inversa('GATACA') = 'ACATAG'
Se tienen como datos:
Un listadoL de secuenciasS y
Una cadena de referencia R que identifica de forma única a la especie buscada. R no tiene letras repetidas.
Implemente un programa que muestre todas las secuencias S que pertenecen a la especie buscada y los índices en la inversa deS donde aparece la cadena de referencia R .
Para realizar esta tarea, por cada secuencia S en listado L :
1. Forme la cadena inversa de la secuencia S
2. La secuencia S pertenece a la especie buscada si:
a) la cadena de referencia R aparece exactamente dos veces en la segunda mitad de inversa y
b) al menos 4 veces en total.
3. Si S pertenece a la especie buscada, muestre la secuencia S y los índices.
Ejemplo:
L = ['ATTTGCTTGCTATTTAAACCGGTTATGCATAGCGC',
'ATTAGCCGCTATCGA',
'…']
R = 'CG'
SALIDA para Secuencia L[0]:
Secuencia: ATTTGCTTGCTATTTAAACCGGTTATGCATAGCGC
Inversa: CGCGATACGTATTGGCCAAATTTATCGTTCGTTTA
Índices: [0, 2, 7, 25, 29]
SALIDA para Secuencia L[1]:
Secuencia: ...
Índices: ...