Ejercicio: 1Eva_IIT2017_T3 Venta combustibles
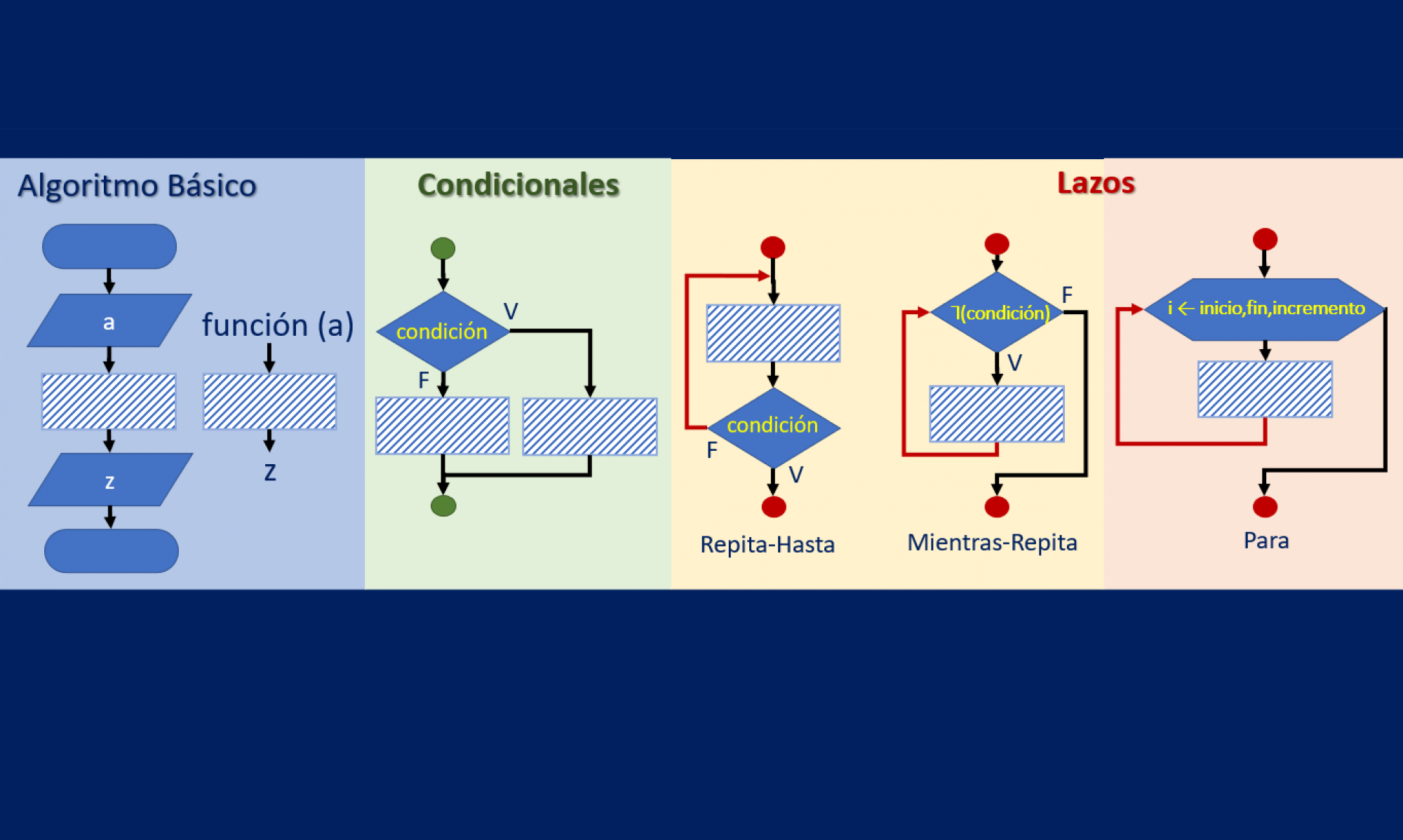
Propuesta de solución en Python:
Se usan datos de prueba para probar la ejecución del algoritmo por cada literal. En el bloque de ingreso se pide solo un tipo de combustible (literal a) y una ciudad (literal b).
Se usa vector.index(dato) para ubicar la posición de un dato en el vector.
Como algunas respuestas tienen un número indeterminado de elementos se usan listas, al inicio vacias. Revise el uso de np.concatenate() para hacerlo con arreglos.
# CCPG1001 Fundamentos de Programación FIEC-ESPOL # 1Eva_IIT2017_T3 Venta combustibles import numpy as np # INGRESO venta = np.array([ [ 239034, 678493, 896321, 32438, 554213], [4568321, 6745634, 9754008, 3242342, 3456123], [ 234773, 56743, 123678, 4783, 90874], [ 45672, 45212, 90781, 3904, 90431]]) tipoGasolina = np.array(['Regular', 'Extra', 'Super', 'Premium']) gasolinera = np.array(['Primax Alborada', 'PS Los Ríos', 'Móbil Cumbayá', 'Lutexa Cia Ltda', 'PS Remigio Crespo']) distrito = np.array(['distrito1', 'distrito2', 'distrito1', 'distrito2', 'distrito4']) ciudad = np.array(['Guayaquil', 'Babahoyo', 'Quito', 'Guayaquil', 'Cuenca']) meta = 5000000 untipo = input('un tipo de gasolina: ') unaciudad = input('una ciudad: ') # PROCEDIMIENTO tipoGasolina = list(tipoGasolina) gasolinera = list(gasolinera) distrito = list(distrito) ciudad = list(ciudad) tamano = np.shape(venta) n = tamano[0] m = tamano[1] # literal a cual = tipoGasolina.index(untipo) cantidad = venta[cual,:] prom_anual = np.sum(cantidad)/m menosprom = [] for c in range(0,m,1): if (cantidad[c]<prom_anual): menosprom.append(gasolinera[c]) # literal b cual = ciudad.index(unaciudad) anual = np.sum(venta, axis=0) menosciudad = [] for c in range(0,m,1): if (ciudad[c] == unaciudad and anual[c]<meta): menosciudad.append(gasolinera[c]) cuantas = len(menosciudad) # literal c cual = tipoGasolina.index('Premium') cantidad = venta[cual,:] nombres = [] valores = [] for c in range(0,m,1): if (distrito[c] == 'distrito2'): nombres.append(ciudad[c]) valores.append(cantidad[c]) k = len(nombres) mayor = np.argmax(np.array(valores)) mejorendistrito = nombres[mayor] # SALIDA print('literal a') print('con menos ventas anuales que promedio: ') print(menosprom) print('literal b') print('cantidad de estaciones de ' + unaciudad + ': ') print(cuantas) print('literal c') print(nombres) print(valores) print(mejorendistrito)
Resultado del algoritmo
un tipo de gasolina: Regular una ciudad: Guayaquil literal a con menos ventas anuales que promedio: ['Primax Alborada', 'Lutexa Cia Ltda'] literal b cantidad de estaciones de Guayaquil: 1 literal c ['Babahoyo', 'Guayaquil'] [45212, 3904] Babahoyo >>>